 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToolSpec: Accelerating Tool Calling via Schema-Aware and Retrieval-Augmented Speculative Decoding
Apr 15, 2026Tool calling has greatly expanded the practical utility of large language models (LLMs) by enabling them to interact with external applications. As LLM capabilities advance, effective tool use increasingly involves multi-step, multi-turn interactions to solve complex tasks. However, the resulting growth in tool interactions incurs substantial latency, posing a key challenge for real-time LLM serving. Through empirical analysis, we find that tool-calling traces are highly structured, conform to constrained schemas, and often exhibit recurring invocation patterns. Motivated by this, we propose ToolSpec, a schema-aware, retrieval-augmented speculative decoding method for accelerating tool calling. ToolSpec exploits predefined tool schemas to generate accurate drafts, using a finite-state machine to alternate between deterministic schema token filling and speculative generation for variable fields. In addition, ToolSpec retrieves similar historical tool invocations and reuses them as drafts to further improve efficiency. ToolSpec presents a plug-and-play solution that can be seamlessly integrated into existing LLM workflows. Experiments across multiple benchmarks demonstrate that ToolSpec achieves up to a 4.2x speedup, substantially outperforming existing training-free speculative decoding methods.
Annealed Relaxation of Speculative Decoding for Faster Autoregressive Image Generation
Jan 14, 2026Despite significant progress in autoregressive image generation, inference remains slow due to the sequential nature of AR models and the ambiguity of image tokens, even when using speculative decoding. Recent works attempt to address this with relaxed speculative decoding but lack theoretical grounding. In this paper, we establish the theoretical basis of relaxed SD and propose COOL-SD, an annealed relaxation of speculative decoding built on two key insights. The first analyzes the total variation (TV) distance between the target model and relaxed speculative decoding and yields an optimal resampling distribution that minimizes an upper bound of the distance. The second uses perturbation analysis to reveal an annealing behaviour in relaxed speculative decoding, motivating our annealed design. Together, these insights enable COOL-SD to generate images faster with comparable quality, or achieve better quality at similar latency. Experiments validate the effectiveness of COOL-SD, showing consistent improvements over prior methods in speed-quality trade-offs.
Demystifying the Slash Pattern in Attention: The Role of RoPE
Jan 13, 2026Large Language Models (LLMs) often exhibit slash attention patterns, where attention scores concentrate along the $Δ$-th sub-diagonal for some offset $Δ$. These patterns play a key role in passing information across tokens. But why do they emerge? In this paper, we demystify the emergence of these Slash-Dominant Heads (SDHs) from both empirical and theoretical perspectives. First, by analyzing open-source LLMs, we find that SDHs are intrinsic to models and generalize to out-of-distribution prompts. To explain the intrinsic emergence, we analyze the queries, keys, and Rotary Position Embedding (RoPE), which jointly determine attention scores. Our empirical analysis reveals two characteristic conditions of SDHs: (1) Queries and keys are almost rank-one, and (2) RoPE is dominated by medium- and high-frequency components. Under these conditions, queries and keys are nearly identical across tokens, and interactions between medium- and high-frequency components of RoPE give rise to SDHs. Beyond empirical evidence, we theoretically show that these conditions are sufficient to ensure the emergence of SDHs by formalizing them as our modeling assumptions. Particularly, we analyze the training dynamics of a shallow Transformer equipped with RoPE under these conditions, and prove that models trained via gradient descent exhibit SDHs. The SDHs generalize to out-of-distribution prompts.
Sparse-to-Dense: A Free Lunch for Lossless Acceleration of Video Understanding in LLMs
May 25, 2025Due to the auto-regressive nature of current video large language models (Video-LLMs), the inference latency increases as the input sequence length grows, posing challenges for the efficient processing of video sequences that are usually very long. We observe that during decoding, the attention scores of most tokens in Video-LLMs tend to be sparse and concentrated, with only certain tokens requiring comprehensive full attention. Based on this insight, we introduce Sparse-to-Dense (StD), a novel decoding strategy that integrates two distinct modules: one leveraging sparse top-K attention and the other employing dense full attention. These modules collaborate to accelerate Video-LLMs without loss. The fast (sparse) model speculatively decodes multiple tokens, while the slow (dense) model verifies them in parallel. StD is a tuning-free, plug-and-play solution that achieves up to a 1.94$\times$ walltime speedup in video processing. It maintains model performance while enabling a seamless transition from a standard Video-LLM to a sparse Video-LLM with minimal code modifications.
BanditSpec: Adaptive Speculative Decoding via Bandit Algorithms
May 21, 2025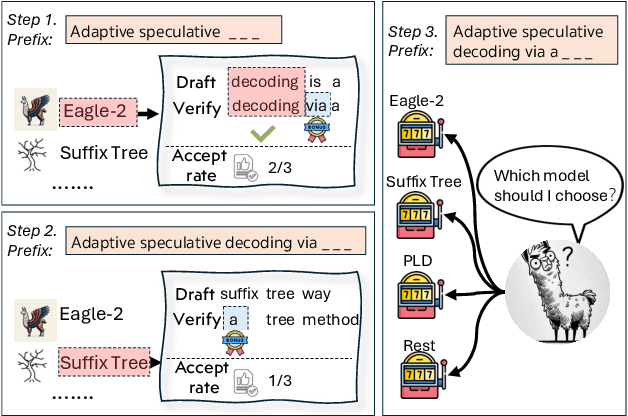
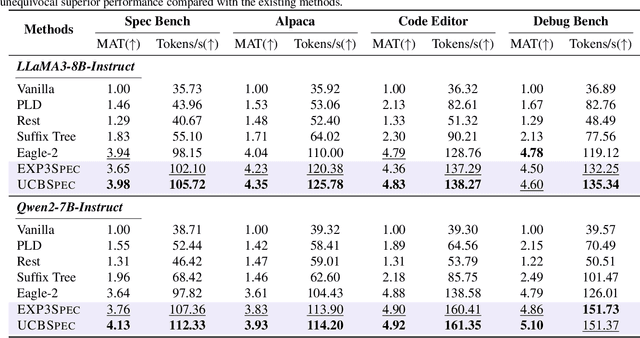
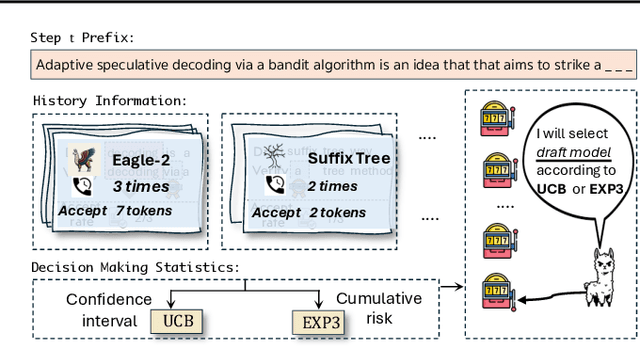
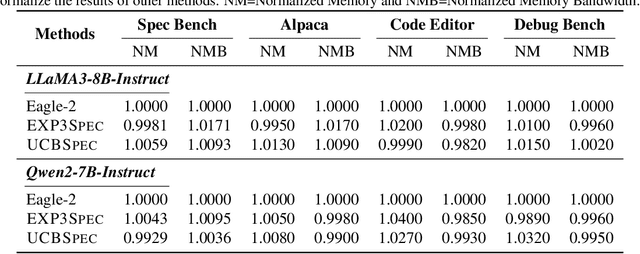
Speculative decoding has emerged as a popular method to accelerate the inference of Large Language Models (LLMs) while retaining their superior text generation performance. Previous methods either adopt a fixed speculative decoding configuration regardless of the prefix tokens, or train draft models in an offline or online manner to align them with the context. This paper proposes a training-free online learning framework to adaptively choose the configuration of the hyperparameters for speculative decoding as text is being generated. We first formulate this hyperparameter selection problem as a Multi-Armed Bandit problem and provide a general speculative decoding framework BanditSpec. Furthermore, two bandit-based hyperparameter selection algorithms, UCBSpec and EXP3Spec, are designed and analyzed in terms of a novel quantity, the stopping time regret. We upper bound this regret under both stochastic and adversarial reward settings. By deriving an information-theoretic impossibility result, it is shown that the regret performance of UCBSpec is optimal up to universal constants. Finally, extensive empirical experiments with LLaMA3 and Qwen2 demonstrate that our algorithms are effective compared to existing methods, and the throughput is close to the oracle best hyperparameter in simulated real-life LLM serving scenarios with diverse input prompts.
LongSpec: Long-Context Speculative Decoding with Efficient Drafting and Verification
Feb 24, 2025
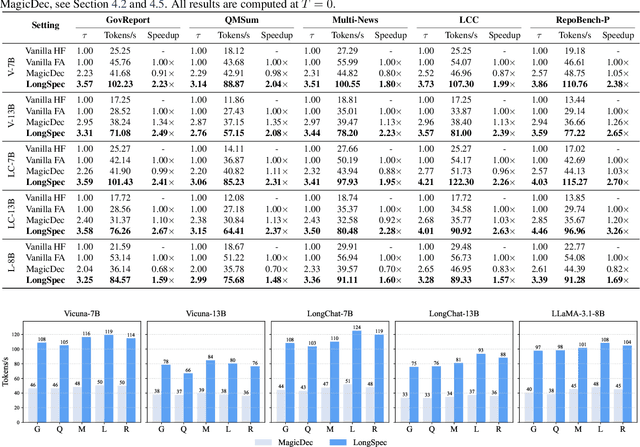

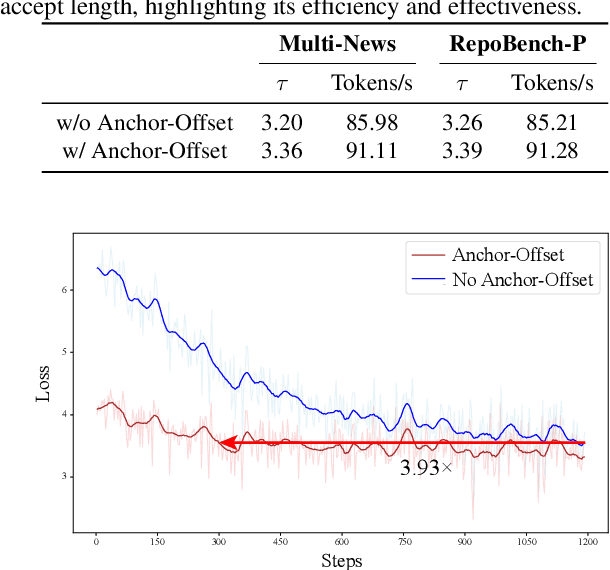
Speculative decoding has become a promising technique to mitigate the high inference latency of autoregressive decoding in Large Language Models (LLMs). Despite its promise, the effective application of speculative decoding in LLMs still confronts three key challenges: the increasing memory demands of the draft model, the distribution shift between the short-training corpora and long-context inference, and inefficiencies in attention implementation. In this work, we enhance the performance of speculative decoding in long-context settings by addressing these challenges. First, we propose a memory-efficient draft model with a constant-sized Key-Value (KV) cache. Second, we introduce novel position indices for short-training data, enabling seamless adaptation from short-context training to long-context inference. Finally, we present an innovative attention aggregation method that combines fast implementations for prefix computation with standard attention for tree mask handling, effectively resolving the latency and memory inefficiencies of tree decoding. Our approach achieves strong results on various long-context tasks, including repository-level code completion, long-context summarization, and o1-like long reasoning tasks, demonstrating significant improvements in latency reduction. The code is available at https://github.com/sail-sg/LongSpec.
Sailor2: Sailing in South-East Asia with Inclusive Multilingual LLMs
Feb 18, 2025



Sailor2 is a family of cutting-edge multilingual language models for South-East Asian (SEA) languages, available in 1B, 8B, and 20B sizes to suit diverse applications. Building on Qwen2.5, Sailor2 undergoes continuous pre-training on 500B tokens (400B SEA-specific and 100B replay tokens) to support 13 SEA languages while retaining proficiency in Chinese and English. Sailor2-20B model achieves a 50-50 win rate against GPT-4o across SEA languages. We also deliver a comprehensive cookbook on how to develop the multilingual model in an efficient manner, including five key aspects: data curation, pre-training, post-training, model customization and evaluation. We hope that Sailor2 model (Apache 2.0 license) will drive language development in the SEA region, and Sailor2 cookbook will inspire researchers to build more inclusive LLMs for other under-served languages.
When Precision Meets Position: BFloat16 Breaks Down RoPE in Long-Context Training
Nov 20, 2024



Extending context window sizes allows large language models (LLMs) to process longer sequences and handle more complex tasks. Rotary Positional Embedding (RoPE) has become the de facto standard due to its relative positional encoding properties that benefit long-context training. However, we observe that using RoPE with BFloat16 format results in numerical issues, causing it to deviate from its intended relative positional encoding, especially in long-context scenarios. This issue arises from BFloat16's limited precision and accumulates as context length increases, with the first token contributing significantly to this problem. To address this, we develop AnchorAttention, a plug-and-play attention method that alleviates numerical issues caused by BFloat16, improves long-context capabilities, and speeds up training. AnchorAttention reduces unnecessary attention computations, maintains semantic coherence, and boosts computational efficiency by treating the first token as a shared anchor with a consistent position ID, making it visible to all documents within the training context. Experiments on three types of LLMs demonstrate that AnchorAttention significantly improves long-context performance and reduces training time by over 50\% compared to standard full attention mechanisms, while preserving the original LLM's capabilities on general tasks. Our code is available at https://github.com/haonan3/AnchorContext.
SimLayerKV: A Simple Framework for Layer-Level KV Cache Reduction
Oct 17, 2024



Recent advancements in large language models (LLMs) have extended their capabilities to handle long contexts. However, increasing the number of model layers and the length of input sequences significantly escalates the memory required to store key-value (KV) cache, posing challenges for efficient inference. To mitigate this issue, we present SimLayerKV, a simple yet effective method that reduces inter-layer KV cache redundancies by selectively dropping cache in identified lazy layers. Our approach is based on the observation that certain layers in long-context LLMs exhibit "lazy" behavior, contributing less to modeling long-range dependencies compared to non-lazy layers. By analyzing attention weight patterns, we find that the behavior of these lazy layers is consistent across tokens during generation for a given input. This insight motivates our SimLayerKV, which identifies lazy layers and reduces their KV cache accordingly. SimLayerKV is training-free, generalizable, and can be implemented with only seven lines of code. We conduct extensive experiments on three representative LLMs, e.g., LLaMA2-7B, LLaMA3-8B, and Mistral-7B across 16 tasks from the LongBench benchmark. The results demonstrate that SimLayerKV achieves a KV cache compression ratio of 5$\times$ with only a 1.2% performance drop when combined with 4-bit quantization. Our code is available at https://github.com/sail-sg/SimLayerKV.
When Attention Sink Emerges in Language Models: An Empirical View
Oct 14, 2024



Language Models (LMs) assign significant attention to the first token, even if it is not semantically important, which is known as attention sink. This phenomenon has been widely adopted in applications such as streaming/long context generation, KV cache optimization, inference acceleration, model quantization, and others. Despite its widespread use, a deep understanding of attention sink in LMs is still lacking. In this work, we first demonstrate that attention sinks exist universally in LMs with various inputs, even in small models. Furthermore, attention sink is observed to emerge during the LM pre-training, motivating us to investigate how optimization, data distribution, loss function, and model architecture in LM pre-training influence its emergence. We highlight that attention sink emerges after effective optimization on sufficient training data. The sink position is highly correlated with the loss function and data distribution. Most importantly, we find that attention sink acts more like key biases, storing extra attention scores, which could be non-informative and not contribute to the value computation. We also observe that this phenomenon (at least partially) stems from tokens' inner dependence on attention scores as a result of softmax normalization. After relaxing such dependence by replacing softmax attention with other attention operations, such as sigmoid attention without normalization, attention sinks do not emerge in LMs up to 1B parameters. The code is available at https://github.com/sail-sg/Attention-Sink.