 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Public Fine-Tuning Datasets: A Complex Review of Current Practices from a Construction Perspective
Jul 11, 2024


With the rapid development of the large model domain, research related to fine-tuning has concurrently seen significant advancement, given that fine-tuning is a constituent part of the training process for large-scale models. Data engineering plays a fundamental role in the training process of models, which includes data infrastructure, data processing, etc. Data during fine-tuning likewise forms the base for large models. In order to embrace the power and explore new possibilities of fine-tuning datasets, this paper reviews current public fine-tuning datasets from the perspective of data construction. An overview of public fine-tuning datasets from two sides: evolution and taxonomy, is provided in this review, aiming to chart the development trajectory. Construction techniques and methods for public fine-tuning datasets of Large Language Models (LLMs), including data generation and data augmentation among others, are detailed. This elaboration follows the aforementioned taxonomy, specifically across demonstration, comparison, and generalist categories. Additionally, a category tree of data generation techniques has been abstracted in our review to assist researchers in gaining a deeper understanding of fine-tuning datasets from the construction dimension. Our review also summarizes the construction features in different data preparation phases of current practices in this field, aiming to provide a comprehensive overview and inform future research. Fine-tuning dataset practices, encompassing various data modalities, are also discussed from a construction perspective in our review. Towards the end of the article, we offer insights and considerations regarding the future construction and developments of fine-tuning datasets.
Generalizable Implicit Motion Modeling for Video Frame Interpolation
Jul 11, 2024Motion modeling is critical in flow-based Video Frame Interpolation (VFI). Existing paradigms either consider linear combinations of bidirectional flows or directly predict bilateral flows for given timestamps without exploring favorable motion priors, thus lacking the capability of effectively modeling spatiotemporal dynamics in real-world videos. To address this limitation, in this study, we introduce Generalizable Implicit Motion Modeling (GIMM), a novel and effective approach to motion modeling for VFI. Specifically, to enable GIMM as an effective motion modeling paradigm, we design a motion encoding pipeline to model spatiotemporal motion latent from bidirectional flows extracted from pre-trained flow estimators, effectively representing input-specific motion priors. Then, we implicitly predict arbitrary-timestep optical flows within two adjacent input frames via an adaptive coordinate-based neural network, with spatiotemporal coordinates and motion latent as inputs. Our GIMM can be smoothly integrated with existing flow-based VFI works without further modifications. We show that GIMM performs better than the current state of the art on the VFI benchmarks.
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
Jul 10, 2024



Visual instruction tuning has made considerable strides in enhancing the capabilities of Large Multimodal Models (LMMs). However, existing open LMMs largely focus on single-image tasks, their applications to multi-image scenarios remains less explored. Additionally, prior LMM research separately tackles different scenarios, leaving it impossible to generalize cross scenarios with new emerging capabilities. To this end, we introduce LLaVA-NeXT-Interleave, which simultaneously tackles Multi-image, Multi-frame (video), Multi-view (3D), and Multi-patch (single-image) scenarios in LMMs. To enable these capabilities, we regard the interleaved data format as a general template and compile the M4-Instruct dataset with 1,177.6k samples, spanning 4 primary domains with 14 tasks and 41 datasets. We also curate the LLaVA-Interleave Bench to comprehensively evaluate the multi-image performance of LMMs. Through extensive experiments, LLaVA-NeXT-Interleave achieves leading results in multi-image, video, and 3D benchmarks, while maintaining the performance of single-image tasks. Besides, our model also exhibits several emerging capabilities, e.g., transferring tasks across different settings and modalities. Code is available at https://github.com/LLaVA-VL/LLaVA-NeXT
Music Era Recognition Using Supervised Contrastive Learning and Artist Information
Jul 07, 2024Does popular music from the 60s sound different than that of the 90s? Prior study has shown that there would exist some variations of patterns and regularities related to instrumentation changes and growing loudness across multi-decadal trends. This indicates that perceiving the era of a song from musical features such as audio and artist information is possible. Music era information can be an important feature for playlist generation and recommendation. However, the release year of a song can be inaccessible in many circumstances. This paper addresses a novel task of music era recognition. We formulate the task as a music classification problem and propose solutions based on supervised contrastive learning. An audio-based model is developed to predict the era from audio. For the case where the artist information is available, we extend the audio-based model to take multimodal inputs and develop a framework, called MultiModal Contrastive (MMC) learning, to enhance the training. Experimental result on Million Song Dataset demonstrates that the audio-based model achieves 54% in accuracy with a tolerance of 3-years range; incorporating the artist information with the MMC framework for training leads to 9% improvement further.
InternLM-XComposer-2.5: A Versatile Large Vision Language Model Supporting Long-Contextual Input and Output
Jul 03, 2024



We present InternLM-XComposer-2.5 (IXC-2.5), a versatile large-vision language model that supports long-contextual input and output. IXC-2.5 excels in various text-image comprehension and composition applications, achieving GPT-4V level capabilities with merely 7B LLM backend. Trained with 24K interleaved image-text contexts, it can seamlessly extend to 96K long contexts via RoPE extrapolation. This long-context capability allows IXC-2.5 to excel in tasks requiring extensive input and output contexts. Compared to its previous 2.0 version, InternLM-XComposer-2.5 features three major upgrades in vision-language comprehension: (1) Ultra-High Resolution Understanding, (2) Fine-Grained Video Understanding, and (3) Multi-Turn Multi-Image Dialogue. In addition to comprehension, IXC-2.5 extends to two compelling applications using extra LoRA parameters for text-image composition: (1) Crafting Webpages and (2) Composing High-Quality Text-Image Articles. IXC-2.5 has been evaluated on 28 benchmarks, outperforming existing open-source state-of-the-art models on 16 benchmarks. It also surpasses or competes closely with GPT-4V and Gemini Pro on 16 key tasks. The InternLM-XComposer-2.5 is publicly available at https://github.com/InternLM/InternLM-XComposer.
WildAvatar: Web-scale In-the-wild Video Dataset for 3D Avatar Creation
Jul 02, 2024



Existing human datasets for avatar creation are typically limited to laboratory environments, wherein high-quality annotations (e.g., SMPL estimation from 3D scans or multi-view images) can be ideally provided. However, their annotating requirements are impractical for real-world images or videos, posing challenges toward real-world applications on current avatar creation methods. To this end, we propose the WildAvatar dataset, a web-scale in-the-wild human avatar creation dataset extracted from YouTube, with $10,000+$ different human subjects and scenes. WildAvatar is at least $10\times$ richer than previous datasets for 3D human avatar creation. We evaluate several state-of-the-art avatar creation methods on our dataset, highlighting the unexplored challenges in real-world applications on avatar creation. We also demonstrate the potential for generalizability of avatar creation methods, when provided with data at scale. We will publicly release our data source links and annotations, to push forward 3D human avatar creation and other related fields for real-world applications.
Comprehensive Generative Replay for Task-Incremental Segmentation with Concurrent Appearance and Semantic Forgetting
Jun 28, 2024Generalist segmentation models are increasingly favored for diverse tasks involving various objects from different image sources. Task-Incremental Learning (TIL) offers a privacy-preserving training paradigm using tasks arriving sequentially, instead of gathering them due to strict data sharing policies. However, the task evolution can span a wide scope that involves shifts in both image appearance and segmentation semantics with intricate correlation, causing concurrent appearance and semantic forgetting. To solve this issue, we propose a Comprehensive Generative Replay (CGR) framework that restores appearance and semantic knowledge by synthesizing image-mask pairs to mimic past task data, which focuses on two aspects: modeling image-mask correspondence and promoting scalability for diverse tasks. Specifically, we introduce a novel Bayesian Joint Diffusion (BJD) model for high-quality synthesis of image-mask pairs with their correspondence explicitly preserved by conditional denoising. Furthermore, we develop a Task-Oriented Adapter (TOA) that recalibrates prompt embeddings to modulate the diffusion model, making the data synthesis compatible with different tasks. Experiments on incremental tasks (cardiac, fundus and prostate segmentation) show its clear advantage for alleviating concurrent appearance and semantic forgetting. Code is available at https://github.com/jingyzhang/CGR.
A Comprehensive Solution to Connect Speech Encoder and Large Language Model for ASR
Jun 25, 2024



Recent works have shown promising results in connecting speech encoders to large language models (LLMs) for speech recognition. However, several limitations persist, including limited fine-tuning options, a lack of mechanisms to enforce speech-text alignment, and high insertion errors especially in domain mismatch conditions. This paper presents a comprehensive solution to address these issues. We begin by investigating more thoughtful fine-tuning schemes. Next, we propose a matching loss to enhance alignment between modalities. Finally, we explore training and inference methods to mitigate high insertion errors. Experimental results on the Librispeech corpus demonstrate that partially fine-tuning the encoder and LLM using parameter-efficient methods, such as LoRA, is the most cost-effective approach. Additionally, the matching loss improves modality alignment, enhancing performance. The proposed training and inference methods significantly reduce insertion errors.
GIM: A Million-scale Benchmark for Generative Image Manipulation Detection and Localization
Jun 24, 2024



The extraordinary ability of generative models emerges as a new trend in image editing and generating realistic images, posing a serious threat to the trustworthiness of multimedia data and driving the research of image manipulation detection and location(IMDL). However, the lack of a large-scale data foundation makes IMDL task unattainable. In this paper, a local manipulation pipeline is designed, incorporating the powerful SAM, ChatGPT and generative models. Upon this basis, We propose the GIM dataset, which has the following advantages: 1) Large scale, including over one million pairs of AI-manipulated images and real images. 2) Rich Image Content, encompassing a broad range of image classes 3) Diverse Generative Manipulation, manipulated images with state-of-the-art generators and various manipulation tasks. The aforementioned advantages allow for a more comprehensive evaluation of IMDL methods, extending their applicability to diverse images. We introduce two benchmark settings to evaluate the generalization capability and comprehensive performance of baseline methods. In addition, we propose a novel IMDL framework, termed GIMFormer, which consists of a ShadowTracer, Frequency-Spatial Block (FSB), and a Multi-window Anomalous Modelling (MWAM) Module. Extensive experiments on the GIM demonstrate that GIMFormer surpasses previous state-of-the-art works significantly on two different benchmarks.
video-SALMONN: Speech-Enhanced Audio-Visual Large Language Models
Jun 22, 2024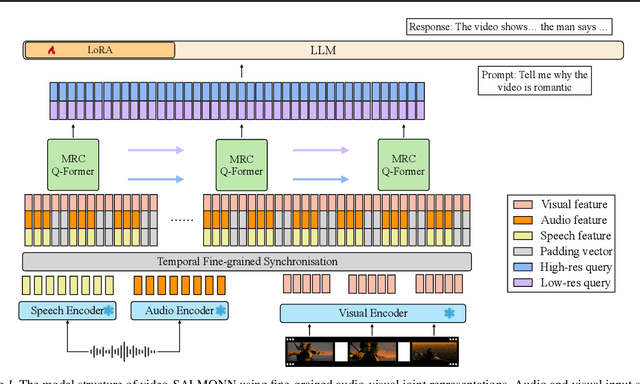



Speech understanding as an element of the more generic video understanding using audio-visual large language models (av-LLMs) is a crucial yet understudied aspect. This paper proposes video-SALMONN, a single end-to-end av-LLM for video processing, which can understand not only visual frame sequences, audio events and music, but speech as well. To obtain fine-grained temporal information required by speech understanding, while keeping efficient for other video elements, this paper proposes a novel multi-resolution causal Q-Former (MRC Q-Former) structure to connect pre-trained audio-visual encoders and the backbone large language model. Moreover, dedicated training approaches including the diversity loss and the unpaired audio-visual mixed training scheme are proposed to avoid frames or modality dominance. On the introduced speech-audio-visual evaluation benchmark, video-SALMONN achieves more than 25\% absolute accuracy improvements on the video-QA task and over 30\% absolute accuracy improvements on audio-visual QA tasks with human speech. In addition, video-SALMONN demonstrates remarkable video comprehension and reasoning abilities on tasks that are unprecedented by other av-LLMs. Our training code and model checkpoints are available at \texttt{\url{https://github.com/bytedance/SALMONN/}}.