 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFirst Return, Entropy-Eliciting Explore
Jul 09, 2025Reinforcement Learning from Verifiable Rewards (RLVR) improves the reasoning abilities of Large Language Models (LLMs) but it struggles with unstable exploration. We propose FR3E (First Return, Entropy-Eliciting Explore), a structured exploration framework that identifies high-uncertainty decision points in reasoning trajectories and performs targeted rollouts to construct semantically grounded intermediate feedback. Our method provides targeted guidance without relying on dense supervision. Empirical results on mathematical reasoning benchmarks(AIME24) show that FR3E promotes more stable training, produces longer and more coherent responses, and increases the proportion of fully correct trajectories. These results highlight the framework's effectiveness in improving LLM reasoning through more robust and structured exploration.
ZeCO: Zero Communication Overhead Sequence Parallelism for Linear Attention
Jul 02, 2025Linear attention mechanisms deliver significant advantages for Large Language Models (LLMs) by providing linear computational complexity, enabling efficient processing of ultra-long sequences (e.g., 1M context). However, existing Sequence Parallelism (SP) methods, essential for distributing these workloads across devices, become the primary bottleneck due to substantial communication overhead. In this paper, we introduce ZeCO (Zero Communication Overhead) sequence parallelism for linear attention models, a new SP method designed to overcome these limitations and achieve end-to-end near-linear scalability for long sequence training. For example, training a model with a 1M sequence length across 64 devices using ZeCO takes roughly the same time as training with an 16k sequence on a single device. At the heart of ZeCO lies All-Scan, a new collective communication primitive. All-Scan provides each SP rank with precisely the initial operator state it requires while maintaining a minimal communication footprint, effectively eliminating communication overhead. Theoretically, we prove the optimaity of ZeCO, showing that it introduces only negligible time and space overhead. Empirically, we compare the communication costs of different sequence parallelism strategies and demonstrate that All-Scan achieves the fastest communication in SP scenarios. Specifically, on 256 GPUs with an 8M sequence length, ZeCO achieves a 60\% speedup compared to the current state-of-the-art (SOTA) SP method. We believe ZeCO establishes a clear path toward efficiently training next-generation LLMs on previously intractable sequence lengths.
MMSearch-R1: Incentivizing LMMs to Search
Jun 25, 2025



Robust deployment of large multimodal models (LMMs) in real-world scenarios requires access to external knowledge sources, given the complexity and dynamic nature of real-world information. Existing approaches such as retrieval-augmented generation (RAG) and prompt engineered search agents rely on rigid pipelines, often leading to inefficient or excessive search behaviors. We present MMSearch-R1, the first end-to-end reinforcement learning framework that enables LMMs to perform on-demand, multi-turn search in real-world Internet environments. Our framework integrates both image and text search tools, allowing the model to reason about when and how to invoke them guided by an outcome-based reward with a search penalty. To support training, We collect a multimodal search VQA dataset through a semi-automated pipeline that covers diverse visual and textual knowledge needs and curate a search-balanced subset with both search-required and search-free samples, which proves essential for shaping efficient and on-demand search behavior. Extensive experiments on knowledge-intensive and info-seeking VQA tasks show that our model not only outperforms RAG-based baselines of the same model size, but also matches the performance of a larger RAG-based model while reducing search calls by over 30%. We further analyze key empirical findings to offer actionable insights for advancing research in multimodal search.
video-SALMONN 2: Captioning-Enhanced Audio-Visual Large Language Models
Jun 18, 2025Videos contain a wealth of information, and generating detailed and accurate descriptions in natural language is a key aspect of video understanding. In this paper, we present video-SALMONN 2, an advanced audio-visual large language model (LLM) with low-rank adaptation (LoRA) designed for enhanced video (with paired audio) captioning through directed preference optimisation (DPO). We propose new metrics to evaluate the completeness and accuracy of video descriptions, which are optimised using DPO. To further improve training, we propose a novel multi-round DPO (MrDPO) approach, which involves periodically updating the DPO reference model, merging and re-initialising the LoRA module as a proxy for parameter updates after each training round (1,000 steps), and incorporating guidance from ground-truth video captions to stabilise the process. Experimental results show that MrDPO significantly enhances video-SALMONN 2's captioning accuracy, reducing the captioning error rates by 28\%. The final video-SALMONN 2 model, with just 7 billion parameters, surpasses leading models such as GPT-4o and Gemini-1.5-Pro in video captioning tasks, while maintaining highly competitive performance to the state-of-the-art on widely used video question-answering benchmarks among models of similar size. Codes are available at \href{https://github.com/bytedance/video-SALMONN-2}{https://github.com/bytedance/video-SALMONN-2}.
Afterburner: Reinforcement Learning Facilitates Self-Improving Code Efficiency Optimization
May 29, 2025



Large Language Models (LLMs) generate functionally correct solutions but often fall short in code efficiency, a critical bottleneck for real-world deployment. In this paper, we introduce a novel test-time iterative optimization framework to address this, employing a closed-loop system where LLMs iteratively refine code based on empirical performance feedback from an execution sandbox. We explore three training strategies: Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO), and Group Relative Policy Optimization~(GRPO). Experiments on our Venus dataset and the APPS benchmark show that SFT and DPO rapidly saturate in efficiency gains. In contrast, GRPO, using reinforcement learning (RL) with execution feedback, continuously optimizes code performance, significantly boosting both pass@1 (from 47% to 62%) and the likelihood of outperforming human submissions in efficiency (from 31% to 45%). Our work demonstrates effective test-time code efficiency improvement and critically reveals the power of RL in teaching LLMs to truly self-improve code efficiency.
General-Reasoner: Advancing LLM Reasoning Across All Domains
May 21, 2025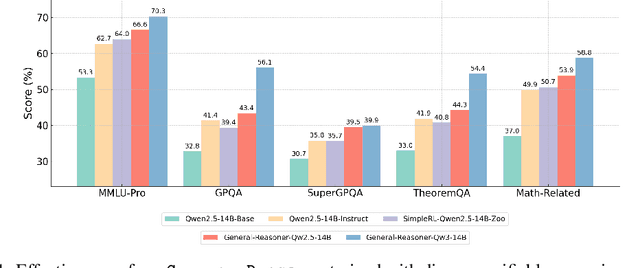
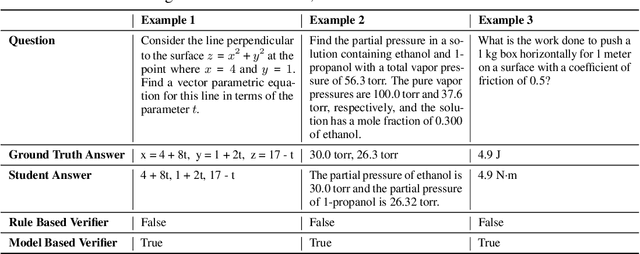

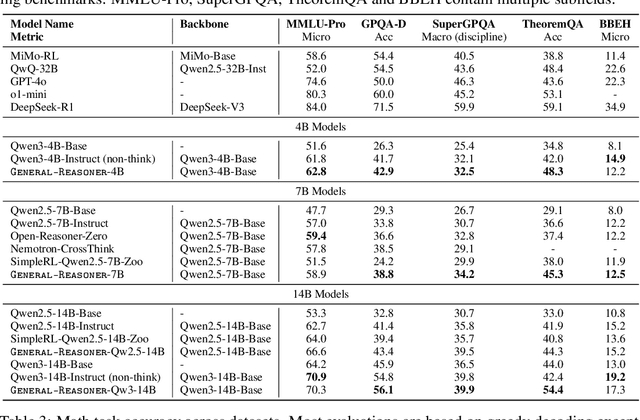
Reinforcement learning (RL) has recently demonstrated strong potential in enhancing the reasoning capabilities of large language models (LLMs). Particularly, the "Zero" reinforcement learning introduced by Deepseek-R1-Zero, enables direct RL training of base LLMs without relying on an intermediate supervised fine-tuning stage. Despite these advancements, current works for LLM reasoning mainly focus on mathematical and coding domains, largely due to data abundance and the ease of answer verification. This limits the applicability and generalization of such models to broader domains, where questions often have diverse answer representations, and data is more scarce. In this paper, we propose General-Reasoner, a novel training paradigm designed to enhance LLM reasoning capabilities across diverse domains. Our key contributions include: (1) constructing a large-scale, high-quality dataset of questions with verifiable answers curated by web crawling, covering a wide range of disciplines; and (2) developing a generative model-based answer verifier, which replaces traditional rule-based verification with the capability of chain-of-thought and context-awareness. We train a series of models and evaluate them on a wide range of datasets covering wide domains like physics, chemistry, finance, electronics etc. Our comprehensive evaluation across these 12 benchmarks (e.g. MMLU-Pro, GPQA, SuperGPQA, TheoremQA, BBEH and MATH AMC) demonstrates that General-Reasoner outperforms existing baseline methods, achieving robust and generalizable reasoning performance while maintaining superior effectiveness in mathematical reasoning tasks.
LiveCC: Learning Video LLM with Streaming Speech Transcription at Scale
Apr 22, 2025



Recent video large language models (Video LLMs) often depend on costly human annotations or proprietary model APIs (e.g., GPT-4o) to produce training data, which limits their training at scale. In this paper, we explore large-scale training for Video LLM with cheap automatic speech recognition (ASR) transcripts. Specifically, we propose a novel streaming training approach that densely interleaves the ASR words and video frames according to their timestamps. Compared to previous studies in vision-language representation with ASR, our method naturally fits the streaming characteristics of ASR, thus enabling the model to learn temporally-aligned, fine-grained vision-language modeling. To support the training algorithm, we introduce a data production pipeline to process YouTube videos and their closed captions (CC, same as ASR), resulting in Live-CC-5M dataset for pre-training and Live-WhisperX-526K dataset for high-quality supervised fine-tuning (SFT). Remarkably, even without SFT, the ASR-only pre-trained LiveCC-7B-Base model demonstrates competitive general video QA performance and exhibits a new capability in real-time video commentary. To evaluate this, we carefully design a new LiveSports-3K benchmark, using LLM-as-a-judge to measure the free-form commentary. Experiments show our final LiveCC-7B-Instruct model can surpass advanced 72B models (Qwen2.5-VL-72B-Instruct, LLaVA-Video-72B) in commentary quality even working in a real-time mode. Meanwhile, it achieves state-of-the-art results at the 7B/8B scale on popular video QA benchmarks such as VideoMME and OVOBench, demonstrating the broad generalizability of our approach. All resources of this paper have been released at https://showlab.github.io/livecc.
ACVUBench: Audio-Centric Video Understanding Benchmark
Mar 25, 2025



Audio often serves as an auxiliary modality in video understanding tasks of audio-visual large language models (LLMs), merely assisting in the comprehension of visual information. However, a thorough understanding of videos significantly depends on auditory information, as audio offers critical context, emotional cues, and semantic meaning that visual data alone often lacks. This paper proposes an audio-centric video understanding benchmark (ACVUBench) to evaluate the video comprehension capabilities of multimodal LLMs with a particular focus on auditory information. Specifically, ACVUBench incorporates 2,662 videos spanning 18 different domains with rich auditory information, together with over 13k high-quality human annotated or validated question-answer pairs. Moreover, ACVUBench introduces a suite of carefully designed audio-centric tasks, holistically testing the understanding of both audio content and audio-visual interactions in videos. A thorough evaluation across a diverse range of open-source and proprietary multimodal LLMs is performed, followed by the analyses of deficiencies in audio-visual LLMs. Demos are available at https://github.com/lark-png/ACVUBench.
SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild
Mar 24, 2025DeepSeek-R1 has shown that long chain-of-thought (CoT) reasoning can naturally emerge through a simple reinforcement learning (RL) framework with rule-based rewards, where the training may directly start from the base models-a paradigm referred to as zero RL training. Most recent efforts to reproduce zero RL training have primarily focused on the Qwen2.5 model series, which may not be representative as we find the base models already exhibit strong instruction-following and self-reflection abilities. In this work, we investigate zero RL training across 10 diverse base models, spanning different families and sizes including LLama3-8B, Mistral-7B/24B, DeepSeek-Math-7B, Qwen2.5-math-7B, and all Qwen2.5 models from 0.5B to 32B. Leveraging several key design strategies-such as adjusting format reward and controlling query difficulty-we achieve substantial improvements in both reasoning accuracy and response length across most settings. However, by carefully monitoring the training dynamics, we observe that different base models exhibit distinct patterns during training. For instance, the increased response length does not always correlate with the emergence of certain cognitive behaviors such as verification (i.e., the "aha moment"). Notably, we observe the "aha moment" for the first time in small models not from the Qwen family. We share the key designs that enable successful zero RL training, along with our findings and practices. To facilitate further research, we open-source the code, models, and analysis tools.
Improving LLM Video Understanding with 16 Frames Per Second
Mar 18, 2025



Human vision is dynamic and continuous. However, in video understanding with multimodal large language models (LLMs), existing methods primarily rely on static features extracted from images sampled at a fixed low frame rate of frame-per-second (FPS) $\leqslant$2, leading to critical visual information loss. In this paper, we introduce F-16, the first multimodal LLM designed for high-frame-rate video understanding. By increasing the frame rate to 16 FPS and compressing visual tokens within each 1-second clip, F-16 efficiently captures dynamic visual features while preserving key semantic information. Experimental results demonstrate that higher frame rates considerably enhance video understanding across multiple benchmarks, providing a new approach to improving video LLMs beyond scaling model size or training data. F-16 achieves state-of-the-art performance among 7-billion-parameter video LLMs on both general and fine-grained video understanding benchmarks, such as Video-MME and TemporalBench. Furthermore, F-16 excels in complex spatiotemporal tasks, including high-speed sports analysis (\textit{e.g.}, basketball, football, gymnastics, and diving), outperforming SOTA proprietary visual models like GPT-4o and Gemini-1.5-pro. Additionally, we introduce a novel decoding method for F-16 that enables highly efficient low-frame-rate inference without requiring model retraining. Upon acceptance, we will release the source code, model checkpoints, and data.