 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNaturalSpeech: End-to-End Text to Speech Synthesis with Human-Level Quality
May 10, 2022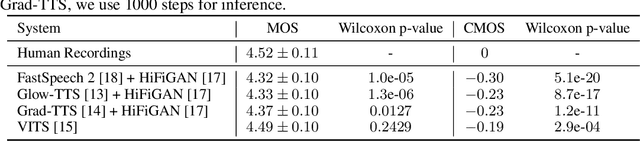
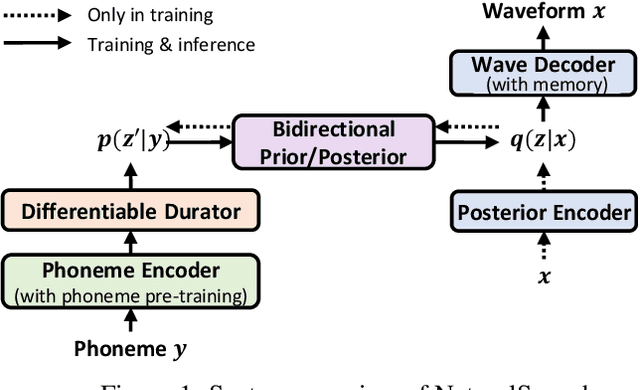
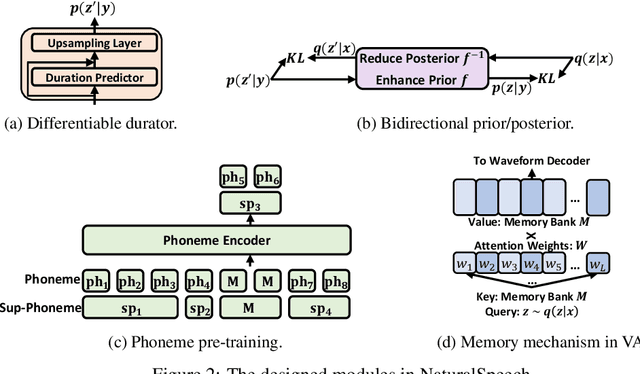
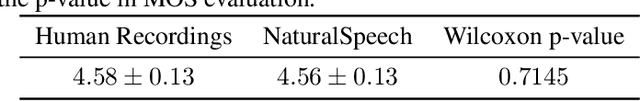
Text to speech (TTS) has made rapid progress in both academia and industry in recent years. Some questions naturally arise that whether a TTS system can achieve human-level quality, how to define/judge that quality and how to achieve it. In this paper, we answer these questions by first defining the human-level quality based on the statistical significance of subjective measure and introducing appropriate guidelines to judge it, and then developing a TTS system called NaturalSpeech that achieves human-level quality on a benchmark dataset. Specifically, we leverage a variational autoencoder (VAE) for end-to-end text to waveform generation, with several key modules to enhance the capacity of the prior from text and reduce the complexity of the posterior from speech, including phoneme pre-training, differentiable duration modeling, bidirectional prior/posterior modeling, and a memory mechanism in VAE. Experiment evaluations on popular LJSpeech dataset show that our proposed NaturalSpeech achieves -0.01 CMOS (comparative mean opinion score) to human recordings at the sentence level, with Wilcoxon signed rank test at p-level p >> 0.05, which demonstrates no statistically significant difference from human recordings for the first time on this dataset.
METRO: Efficient Denoising Pretraining of Large Scale Autoencoding Language Models with Model Generated Signals
Apr 16, 2022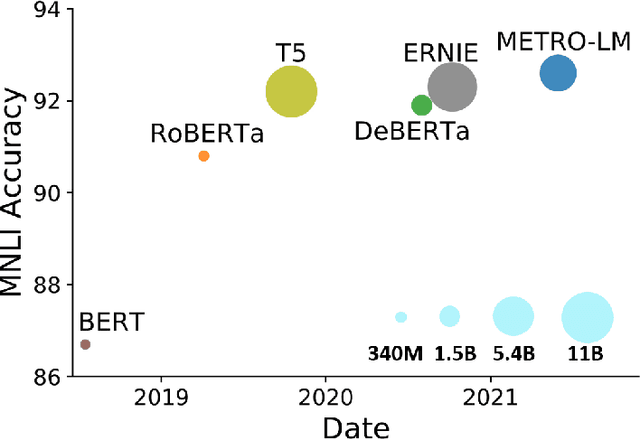
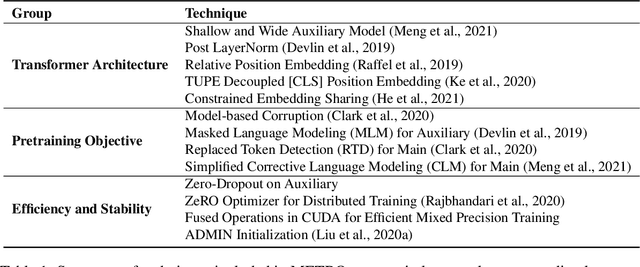
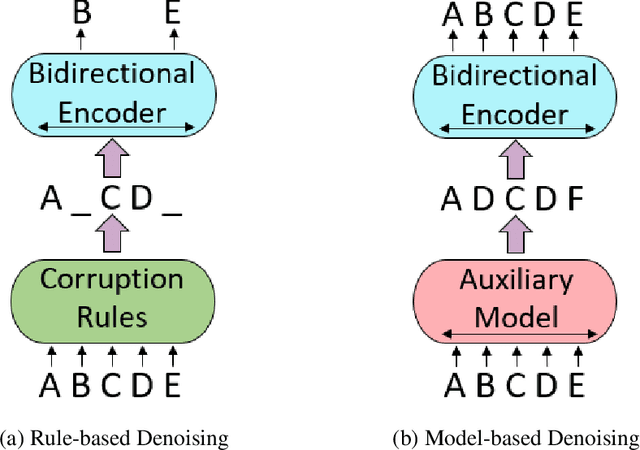
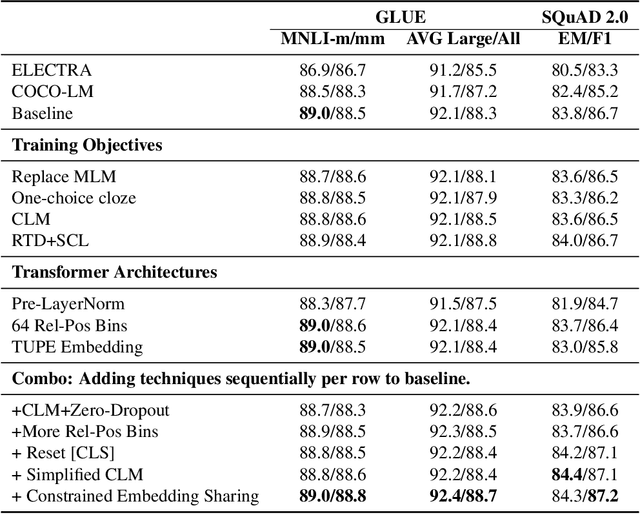
We present an efficient method of pretraining large-scale autoencoding language models using training signals generated by an auxiliary model. Originated in ELECTRA, this training strategy has demonstrated sample-efficiency to pretrain models at the scale of hundreds of millions of parameters. In this work, we conduct a comprehensive empirical study, and propose a recipe, namely "Model generated dEnoising TRaining Objective" (METRO), which incorporates some of the best modeling techniques developed recently to speed up, stabilize, and enhance pretrained language models without compromising model effectiveness. The resultant models, METRO-LM, consisting of up to 5.4 billion parameters, achieve new state-of-the-art on the GLUE, SuperGLUE, and SQuAD benchmarks. More importantly, METRO-LM are efficient in that they often outperform previous large models with significantly smaller model sizes and lower pretraining cost.
Neural Operator with Regularity Structure for Modeling Dynamics Driven by SPDEs
Apr 14, 2022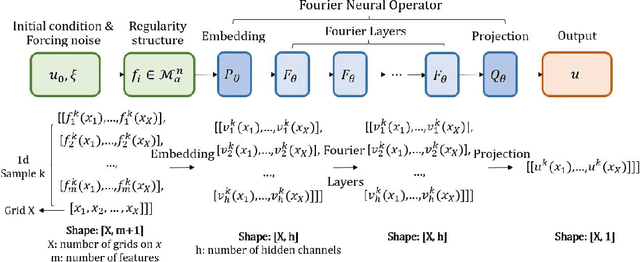

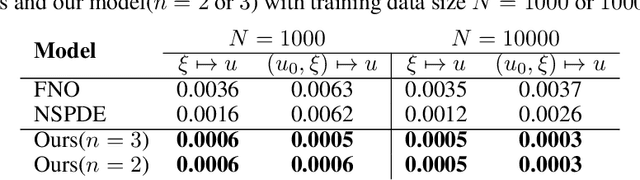
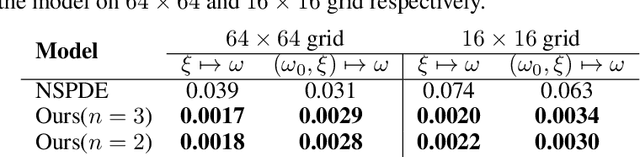
Stochastic partial differential equations (SPDEs) are significant tools for modeling dynamics in many areas including atmospheric sciences and physics. Neural Operators, generations of neural networks with capability of learning maps between infinite-dimensional spaces, are strong tools for solving parametric PDEs. However, they lack the ability to modeling SPDEs which usually have poor regularity due to the driving noise. As the theory of regularity structure has achieved great successes in analyzing SPDEs and provides the concept model feature vectors that well-approximate SPDEs' solutions, we propose the Neural Operator with Regularity Structure (NORS) which incorporates the feature vectors for modeling dynamics driven by SPDEs. We conduct experiments on various of SPDEs including the dynamic Phi41 model and the 2d stochastic Navier-Stokes equation, and the results demonstrate that the NORS is resolution-invariant, efficient, and achieves one order of magnitude lower error with a modest amount of data.
AdaSpeech 4: Adaptive Text to Speech in Zero-Shot Scenarios
Apr 01, 2022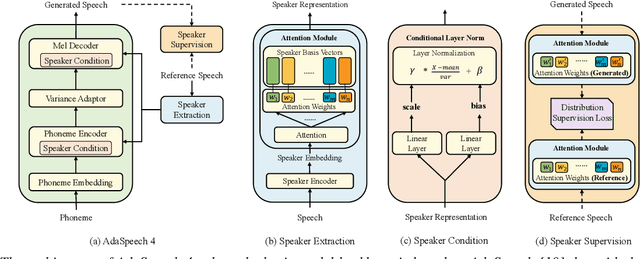
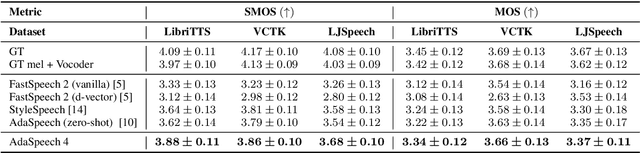
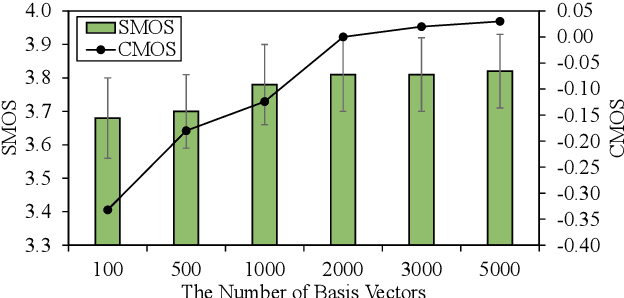
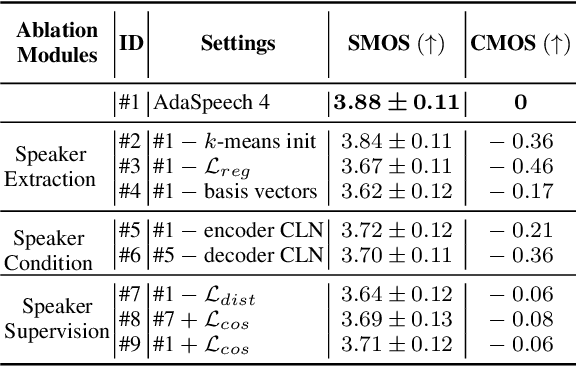
Adaptive text to speech (TTS) can synthesize new voices in zero-shot scenarios efficiently, by using a well-trained source TTS model without adapting it on the speech data of new speakers. Considering seen and unseen speakers have diverse characteristics, zero-shot adaptive TTS requires strong generalization ability on speaker characteristics, which brings modeling challenges. In this paper, we develop AdaSpeech 4, a zero-shot adaptive TTS system for high-quality speech synthesis. We model the speaker characteristics systematically to improve the generalization on new speakers. Generally, the modeling of speaker characteristics can be categorized into three steps: extracting speaker representation, taking this speaker representation as condition, and synthesizing speech/mel-spectrogram given this speaker representation. Accordingly, we improve the modeling in three steps: 1) To extract speaker representation with better generalization, we factorize the speaker characteristics into basis vectors and extract speaker representation by weighted combining of these basis vectors through attention. 2) We leverage conditional layer normalization to integrate the extracted speaker representation to TTS model. 3) We propose a novel supervision loss based on the distribution of basis vectors to maintain the corresponding speaker characteristics in generated mel-spectrograms. Without any fine-tuning, AdaSpeech 4 achieves better voice quality and similarity than baselines in multiple datasets.
Multi-View Substructure Learning for Drug-Drug Interaction Prediction
Mar 28, 2022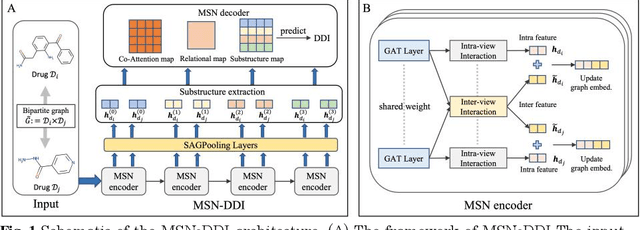
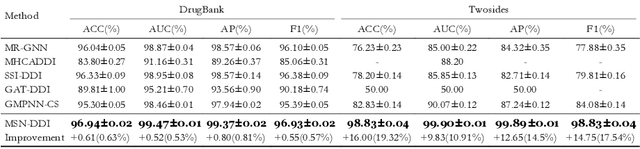
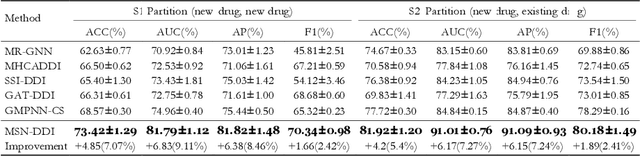
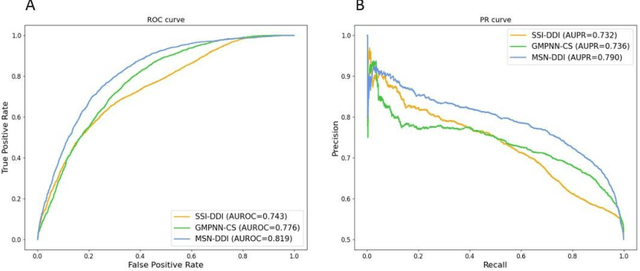
Drug-drug interaction (DDI) prediction provides a drug combination strategy for systemically effective treatment. Previous studies usually model drug information constrained on a single view such as the drug itself, leading to incomplete and noisy information, which limits the accuracy of DDI prediction. In this work, we propose a novel multi- view drug substructure network for DDI prediction (MSN-DDI), which learns chemical substructures from both the representations of the single drug (intra-view) and the drug pair (inter-view) simultaneously and utilizes the substructures to update the drug representation iteratively. Comprehensive evaluations demonstrate that MSN-DDI has almost solved DDI prediction for existing drugs by achieving a relatively improved accuracy of 19.32% and an over 99% accuracy under the transductive setting. More importantly, MSN-DDI exhibits better generalization ability to unseen drugs with a relatively improved accuracy of 7.07% under more challenging inductive scenarios. Finally, MSN-DDI improves prediction performance for real-world DDI applications to new drugs.
DEPTS: Deep Expansion Learning for Periodic Time Series Forecasting
Mar 15, 2022
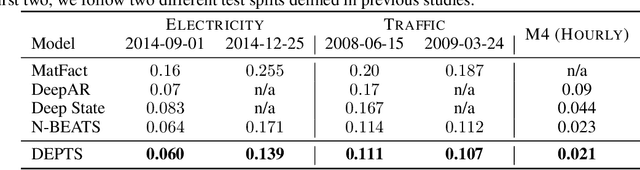
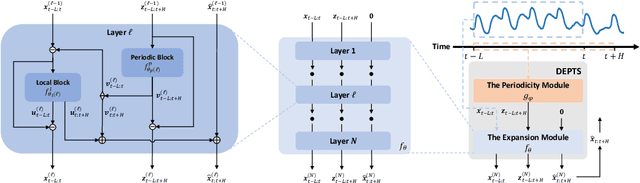
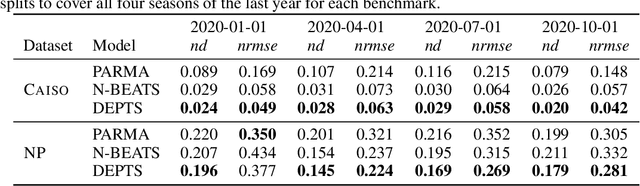
Periodic time series (PTS) forecasting plays a crucial role in a variety of industries to foster critical tasks, such as early warning, pre-planning, resource scheduling, etc. However, the complicated dependencies of the PTS signal on its inherent periodicity as well as the sophisticated composition of various periods hinder the performance of PTS forecasting. In this paper, we introduce a deep expansion learning framework, DEPTS, for PTS forecasting. DEPTS starts with a decoupled formulation by introducing the periodic state as a hidden variable, which stimulates us to make two dedicated modules to tackle the aforementioned two challenges. First, we develop an expansion module on top of residual learning to perform a layer-by-layer expansion of those complicated dependencies. Second, we introduce a periodicity module with a parameterized periodic function that holds sufficient capacity to capture diversified periods. Moreover, our two customized modules also have certain interpretable capabilities, such as attributing the forecasts to either local momenta or global periodicity and characterizing certain core periodic properties, e.g., amplitudes and frequencies. Extensive experiments on both synthetic data and real-world data demonstrate the effectiveness of DEPTS on handling PTS. In most cases, DEPTS achieves significant improvements over the best baseline. Specifically, the error reduction can even reach up to 20% for a few cases. Finally, all codes are publicly available.
An Empirical Study of Graphormer on Large-Scale Molecular Modeling Datasets
Mar 14, 2022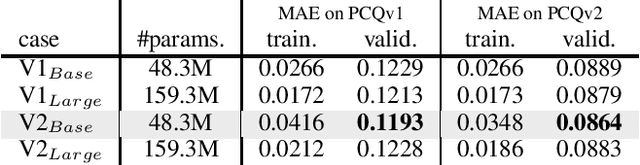
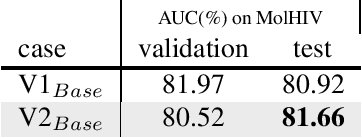
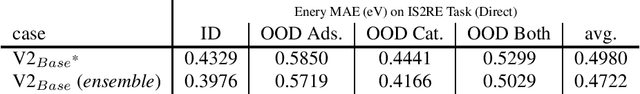

This technical note describes the recent updates of Graphormer, including architecture design modifications, and the adaption to 3D molecular dynamics simulation. The "Graphormer-V2" could attain better results on large-scale molecular modeling datasets than the vanilla one, and the performance gain could be consistently obtained on downstream tasks. In addition, we show that with a global receptive field and an adaptive aggregation strategy, Graphormer is more powerful than classic message-passing-based GNNs. Graphormer-V2 achieves much less MAE than the vanilla Graphormer on the PCQM4M quantum chemistry dataset used in KDD Cup 2021, where the latter one won the first place in this competition. In the meanwhile, Graphormer-V2 greatly outperforms the competitors in the recent Open Catalyst Challenge, which is a competition track on NeurIPS 2021 workshop, and aims to model the catalyst-adsorbate reaction system with advanced AI models. All models could be found at \url{https://github.com/Microsoft/Graphormer}.
Benchmarking Graphormer on Large-Scale Molecular Modeling Datasets
Mar 09, 2022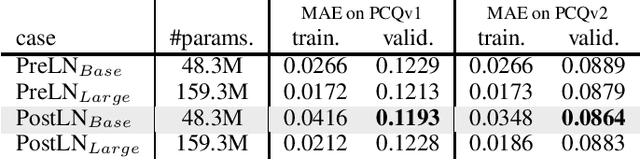
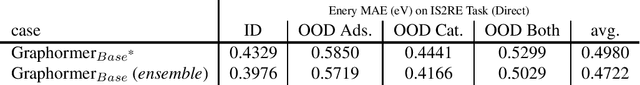
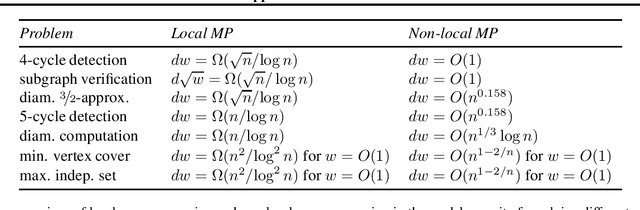
This technical note describes the recent updates of Graphormer, including architecture design modifications, and the adaption to 3D molecular dynamics simulation. With these simple modifications, Graphormer could attain better results on large-scale molecular modeling datasets than the vanilla one, and the performance gain could be consistently obtained on 2D and 3D molecular graph modeling tasks. In addition, we show that with a global receptive field and an adaptive aggregation strategy, Graphormer is more powerful than classic message-passing-based GNNs. Empirically, Graphormer could achieve much less MAE than the originally reported results on the PCQM4M quantum chemistry dataset used in KDD Cup 2021. In the meanwhile, it greatly outperforms the competitors in the recent Open Catalyst Challenge, which is a competition track on NeurIPS 2021 workshop, and aims to model the catalyst-adsorbate reaction system with advanced AI models. All codes could be found at https://github.com/Microsoft/Graphormer.
Revisiting Over-Smoothness in Text to Speech
Feb 26, 2022


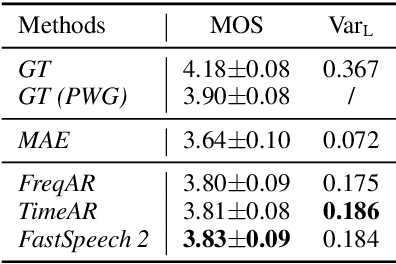
Non-autoregressive text to speech (NAR-TTS) models have attracted much attention from both academia and industry due to their fast generation speed. One limitation of NAR-TTS models is that they ignore the correlation in time and frequency domains while generating speech mel-spectrograms, and thus cause blurry and over-smoothed results. In this work, we revisit this over-smoothing problem from a novel perspective: the degree of over-smoothness is determined by the gap between the complexity of data distributions and the capability of modeling methods. Both simplifying data distributions and improving modeling methods can alleviate the problem. Accordingly, we first study methods reducing the complexity of data distributions. Then we conduct a comprehensive study on NAR-TTS models that use some advanced modeling methods. Based on these studies, we find that 1) methods that provide additional condition inputs reduce the complexity of data distributions to model, thus alleviating the over-smoothing problem and achieving better voice quality. 2) Among advanced modeling methods, Laplacian mixture loss performs well at modeling multimodal distributions and enjoys its simplicity, while GAN and Glow achieve the best voice quality while suffering from increased training or model complexity. 3) The two categories of methods can be combined to further alleviate the over-smoothness and improve the voice quality. 4) Our experiments on the multi-speaker dataset lead to similar conclusions as above and providing more variance information can reduce the difficulty of modeling the target data distribution and alleviate the requirements for model capacity.
Learning Physics-Informed Neural Networks without Stacked Back-propagation
Feb 18, 2022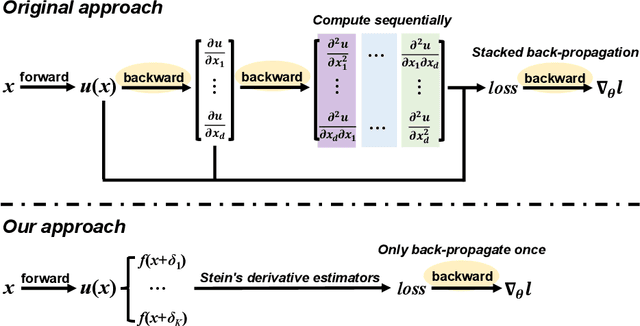
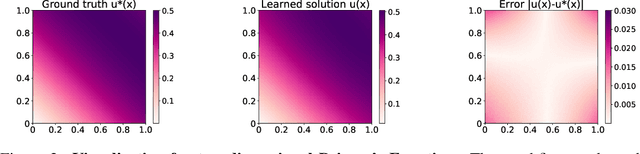
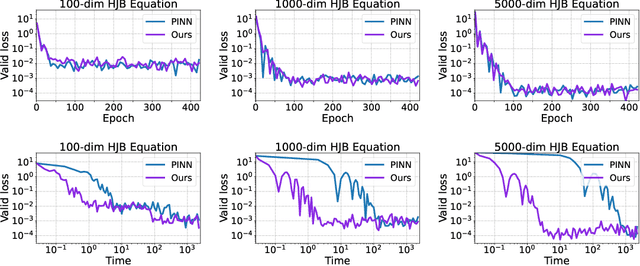
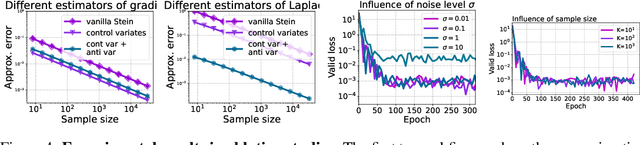
Physics-Informed Neural Network (PINN) has become a commonly used machine learning approach to solve partial differential equations (PDE). But, facing high-dimensional second-order PDE problems, PINN will suffer from severe scalability issues since its loss includes second-order derivatives, the computational cost of which will grow along with the dimension during stacked back-propagation. In this paper, we develop a novel approach that can significantly accelerate the training of Physics-Informed Neural Networks. In particular, we parameterize the PDE solution by the Gaussian smoothed model and show that, derived from Stein's Identity, the second-order derivatives can be efficiently calculated without back-propagation. We further discuss the model capacity and provide variance reduction methods to address key limitations in the derivative estimation. Experimental results show that our proposed method can achieve competitive error compared to standard PINN training but is two orders of magnitude faster.