 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaVA-OneVision-2: Towards Next-Generation Perceptual Intelligence
May 25, 2026We introduce LLaVA-OneVision-2 (LLaVA-OV-2), the most capable vision-language model in the LLaVA-OneVision series to date, achieving superior performance across a broad range of multimodal benchmarks. The model builds on a native OneVision-Encoder and incorporates Windowed Attention for efficient local computation while maintaining native resolution. Its key advance is codec-stream tokenization: it treats compressed video as a continuous bit-cost stream, where bit-cost dynamics determine adaptive temporal groups, and motion-residual cues select salient spatial evidence into compact visual canvases. This allocation concentrates a limited token budget on event-bearing content, enabling more stable long-video token compression than fixed groups of pictures. A shared 3D RoPE further places codec canvases, sampled frames, and images in a unified spatiotemporal coordinate system. Furthermore, we build the LLaVA-OV-2 data and training stack around large-scale open supervision: approximately 8M re-captioned video samples for pretraining, a 4M-sample spatial corpus for fine-tuning. We also introduce JumpScore, a temporal-localization benchmark targeting fine-grained grounding in high-frequency, densely repeated motion, a regime underrepresented by existing video evaluations. A standout capability of LLaVA-OV-2 is its unified perception across video understanding, temporal grounding, spatial grounding, and manipulation-trace reasoning. On JumpScore, LLaVA-OneVision-2-8B reaches 74.9 JumpScore mAP, surpassing Qwen3-VL-8B (30.1) by +44.8 points; under matched visual-token budgets on the same benchmark, codec-stream inputs improve temporal grounding over frame sampling by +9.7 points. Across standard benchmarks, LLaVA-OneVision-2-8B further outperforms Qwen3-VL-8B by +4.3 average points on video tasks, +5.3 on spatial tasks, and +15.6 average J&F on tracking tasks.
SortedRL: Accelerating RL Training for LLMs through Online Length-Aware Scheduling
Mar 24, 2026Scaling reinforcement learning (RL) has shown strong promise for enhancing the reasoning abilities of large language models (LLMs), particularly in tasks requiring long chain-of-thought generation. However, RL training efficiency is often bottlenecked by the rollout phase, which can account for up to 70% of total training time when generating long trajectories (e.g., 16k tokens), due to slow autoregressive generation and synchronization overhead between rollout and policy updates. We propose SortedRL, an online length-aware scheduling strategy designed to address this bottleneck by improving rollout efficiency and maintaining training stability. SortedRL reorders rollout samples based on output lengths, prioritizing short samples forming groups for early updates. This enables large rollout batches, flexible update batches, and near on-policy micro-curriculum construction simultaneously. To further accelerate the pipeline, SortedRL incorporates a mechanism to control the degree of off-policy training through a cache-based mechanism, and is supported by a dedicated RL infrastructure that manages rollout and update via a stateful controller and rollout buffer. Experiments using LLaMA-3.1-8B and Qwen-2.5-32B on diverse tasks, including logical puzzles, and math challenges like AIME 24, Math 500, and Minerval, show that SortedRL reduces RL training bubble ratios by over 50%, while attaining 3.9% to 18.4% superior performance over baseline given same amount of data.
UniG2U-Bench: Do Unified Models Advance Multimodal Understanding?
Mar 03, 2026Unified multimodal models have recently demonstrated strong generative capabilities, yet whether and when generation improves understanding remains unclear. Existing benchmarks lack a systematic exploration of the specific tasks where generation facilitates understanding. To this end, we introduce UniG2U-Bench, a comprehensive benchmark categorizing generation-to-understanding (G2U) evaluation into 7 regimes and 30 subtasks, requiring varying degrees of implicit or explicit visual transformations. Extensive evaluation of over 30 models reveals three core findings: 1) Unified models generally underperform their base Vision-Language Models (VLMs), and Generate-then-Answer (GtA) inference typically degrades performance relative to direct inference. 2) Consistent enhancements emerge in spatial intelligence, visual illusions, or multi-round reasoning subtasks, where enhanced spatial and shape perception, as well as multi-step intermediate image states, prove beneficial. 3) Tasks with similar reasoning structures and models sharing architectures exhibit correlated behaviors, suggesting that generation-understanding coupling induces class-consistent inductive biases over tasks, pretraining data, and model architectures. These findings highlight the necessity for more diverse training data and novel paradigms to fully unlock the potential of unified multimodal modeling.
OneVision-Encoder: Codec-Aligned Sparsity as a Foundational Principle for Multimodal Intelligence
Feb 09, 2026Hypothesis. Artificial general intelligence is, at its core, a compression problem. Effective compression demands resonance: deep learning scales best when its architecture aligns with the fundamental structure of the data. These are the fundamental principles. Yet, modern vision architectures have strayed from these truths: visual signals are highly redundant, while discriminative information, the surprise, is sparse. Current models process dense pixel grids uniformly, wasting vast compute on static background rather than focusing on the predictive residuals that define motion and meaning. We argue that to solve visual understanding, we must align our architectures with the information-theoretic principles of video, i.e., Codecs. Method. OneVision-Encoder encodes video by compressing predictive visual structure into semantic meaning. By adopting Codec Patchification, OV-Encoder abandons uniform computation to focus exclusively on the 3.1%-25% of regions rich in signal entropy. To unify spatial and temporal reasoning under irregular token layouts, OneVision-Encoder employs a shared 3D RoPE and is trained with a large-scale cluster discrimination objective over more than one million semantic concepts, jointly capturing object permanence and motion dynamics. Evidence. The results validate our core hypothesis: efficiency and accuracy are not a trade-off; they are positively correlated. When integrated into LLM, it consistently outperforms strong vision backbones such as Qwen3-ViT and SigLIP2 across 16 image, video, and document understanding benchmarks, despite using substantially fewer visual tokens and pretraining data. Notably, on video understanding tasks, OV-Encoder achieves an average improvement of 4.1% over Qwen3-ViT. Codec-aligned, patch-level sparsity is a foundational principle, enabling OV-Encoder as a scalable engine for next-generation visual generalists.
OLion: Approaching the Hadamard Ideal by Intersecting Spectral and $\ell_{\infty}$ Implicit Biases
Feb 01, 2026Many optimizers can be interpreted as steepest-descent methods under norm-induced geometries, and thus inherit corresponding implicit biases. We introduce \nameA{} (\fullname{}), which combines spectral control from orthogonalized update directions with $\ell_\infty$-style coordinate control from sign updates. \nameA{} forms a Lion-style momentum direction, approximately orthogonalizes it via a few Newton--Schulz iterations, and then applies an entrywise sign, providing an efficient approximation to taking a maximal step over the intersection of the spectral and $\ell_\infty$ constraint sets (a scaled Hadamard-like set for matrix parameters). Despite the strong nonlinearity of orthogonalization and sign, we prove convergence under a mild, empirically verified diagonal-isotropy assumption. Across large-scale language and vision training, including GPT-2 and Llama pretraining, SiT image pretraining, and supervised fine-tuning, \nameA{} matches or outperforms AdamW and Muon under comparable tuning while using only momentum-level optimizer state, and it mitigates optimizer mismatch when fine-tuning AdamW-pretrained checkpoints.
Patient-Similarity Cohort Reasoning in Clinical Text-to-SQL
Jan 14, 2026Real-world clinical text-to-SQL requires reasoning over heterogeneous EHR tables, temporal windows, and patient-similarity cohorts to produce executable queries. We introduce CLINSQL, a benchmark of 633 expert-annotated tasks on MIMIC-IV v3.1 that demands multi-table joins, clinically meaningful filters, and executable SQL. Solving CLINSQL entails navigating schema metadata and clinical coding systems, handling long contexts, and composing multi-step queries beyond traditional text-to-SQL. We evaluate 22 proprietary and open-source models under Chain-of-Thought self-refinement and use rubric-based SQL analysis with execution checks that prioritize critical clinical requirements. Despite recent advances, performance remains far from clinical reliability: on the test set, GPT-5-mini attains 74.7% execution score, DeepSeek-R1 leads open-source at 69.2% and Gemini-2.5-Pro drops from 85.5% on Easy to 67.2% on Hard. Progress on CLINSQL marks tangible advances toward clinically reliable text-to-SQL for real-world EHR analytics.
VidGuard-R1: AI-Generated Video Detection and Explanation via Reasoning MLLMs and RL
Oct 02, 2025With the rapid advancement of AI-generated videos, there is an urgent need for effective detection tools to mitigate societal risks such as misinformation and reputational harm. In addition to accurate classification, it is essential that detection models provide interpretable explanations to ensure transparency for regulators and end users. To address these challenges, we introduce VidGuard-R1, the first video authenticity detector that fine-tunes a multi-modal large language model (MLLM) using group relative policy optimization (GRPO). Our model delivers both highly accurate judgments and insightful reasoning. We curate a challenging dataset of 140k real and AI-generated videos produced by state-of-the-art generation models, carefully designing the generation process to maximize discrimination difficulty. We then fine-tune Qwen-VL using GRPO with two specialized reward models that target temporal artifacts and generation complexity. Extensive experiments demonstrate that VidGuard-R1 achieves state-of-the-art zero-shot performance on existing benchmarks, with additional training pushing accuracy above 95%. Case studies further show that VidGuard-R1 produces precise and interpretable rationales behind its predictions. The code is publicly available at https://VidGuard-R1.github.io.
Benefits and Pitfalls of Reinforcement Learning for Language Model Planning: A Theoretical Perspective
Sep 26, 2025Recent reinforcement learning (RL) methods have substantially enhanced the planning capabilities of Large Language Models (LLMs), yet the theoretical basis for their effectiveness remains elusive. In this work, we investigate RL's benefits and limitations through a tractable graph-based abstraction, focusing on policy gradient (PG) and Q-learning methods. Our theoretical analyses reveal that supervised fine-tuning (SFT) may introduce co-occurrence-based spurious solutions, whereas RL achieves correct planning primarily through exploration, underscoring exploration's role in enabling better generalization. However, we also show that PG suffers from diversity collapse, where output diversity decreases during training and persists even after perfect accuracy is attained. By contrast, Q-learning provides two key advantages: off-policy learning and diversity preservation at convergence. We further demonstrate that careful reward design is necessary to prevent reward hacking in Q-learning. Finally, applying our framework to the real-world planning benchmark Blocksworld, we confirm that these behaviors manifest in practice.
SciVer: Evaluating Foundation Models for Multimodal Scientific Claim Verification
Jun 18, 2025We introduce SciVer, the first benchmark specifically designed to evaluate the ability of foundation models to verify claims within a multimodal scientific context. SciVer consists of 3,000 expert-annotated examples over 1,113 scientific papers, covering four subsets, each representing a common reasoning type in multimodal scientific claim verification. To enable fine-grained evaluation, each example includes expert-annotated supporting evidence. We assess the performance of 21 state-of-the-art multimodal foundation models, including o4-mini, Gemini-2.5-Flash, Llama-3.2-Vision, and Qwen2.5-VL. Our experiment reveals a substantial performance gap between these models and human experts on SciVer. Through an in-depth analysis of retrieval-augmented generation (RAG), and human-conducted error evaluations, we identify critical limitations in current open-source models, offering key insights to advance models' comprehension and reasoning in multimodal scientific literature tasks.
TRAIL: Transferable Robust Adversarial Images via Latent diffusion
May 22, 2025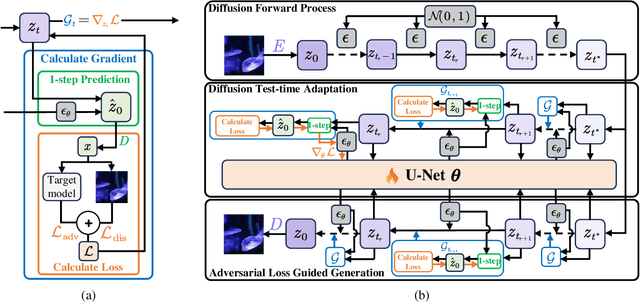
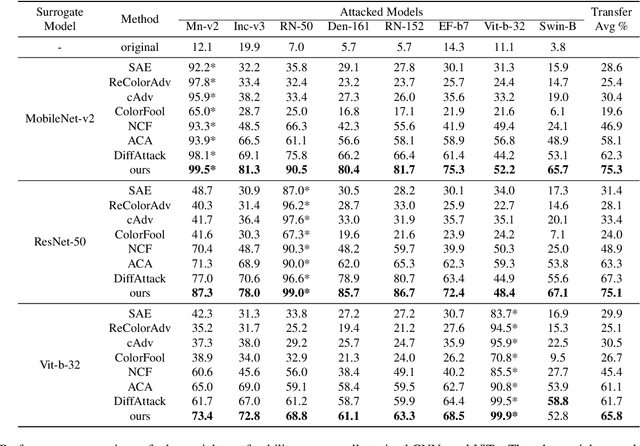
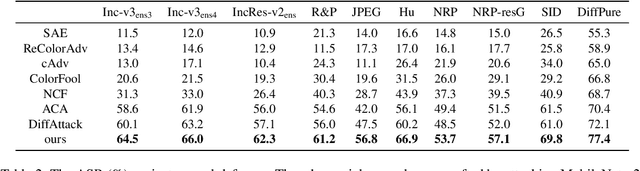

Adversarial attacks exploiting unrestricted natural perturbations present severe security risks to deep learning systems, yet their transferability across models remains limited due to distribution mismatches between generated adversarial features and real-world data. While recent works utilize pre-trained diffusion models as adversarial priors, they still encounter challenges due to the distribution shift between the distribution of ideal adversarial samples and the natural image distribution learned by the diffusion model. To address the challenge, we propose Transferable Robust Adversarial Images via Latent Diffusion (TRAIL), a test-time adaptation framework that enables the model to generate images from a distribution of images with adversarial features and closely resembles the target images. To mitigate the distribution shift, during attacks, TRAIL updates the diffusion U-Net's weights by combining adversarial objectives (to mislead victim models) and perceptual constraints (to preserve image realism). The adapted model then generates adversarial samples through iterative noise injection and denoising guided by these objectives. Experiments demonstrate that TRAIL significantly outperforms state-of-the-art methods in cross-model attack transferability, validating that distribution-aligned adversarial feature synthesis is critical for practical black-box attacks.