 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable User Satisfaction Estimation for Conversational Systems with Large Language Models
Mar 19, 2024



Accurate and interpretable user satisfaction estimation (USE) is critical for understanding, evaluating, and continuously improving conversational systems. Users express their satisfaction or dissatisfaction with diverse conversational patterns in both general-purpose (ChatGPT and Bing Copilot) and task-oriented (customer service chatbot) conversational systems. Existing approaches based on featurized ML models or text embeddings fall short in extracting generalizable patterns and are hard to interpret. In this work, we show that LLMs can extract interpretable signals of user satisfaction from their natural language utterances more effectively than embedding-based approaches. Moreover, an LLM can be tailored for USE via an iterative prompting framework using supervision from labeled examples. The resulting method, Supervised Prompting for User satisfaction Rubrics (SPUR), not only has higher accuracy but is more interpretable as it scores user satisfaction via learned rubrics with a detailed breakdown.
GenSERP: Large Language Models for Whole Page Presentation
Feb 22, 2024



The advent of large language models (LLMs) brings an opportunity to minimize the effort in search engine result page (SERP) organization. In this paper, we propose GenSERP, a framework that leverages LLMs with vision in a few-shot setting to dynamically organize intermediate search results, including generated chat answers, website snippets, multimedia data, knowledge panels into a coherent SERP layout based on a user's query. Our approach has three main stages: (1) An information gathering phase where the LLM continuously orchestrates API tools to retrieve different types of items, and proposes candidate layouts based on the retrieved items, until it's confident enough to generate the final result. (2) An answer generation phase where the LLM populates the layouts with the retrieved content. In this phase, the LLM adaptively optimize the ranking of items and UX configurations of the SERP. Consequently, it assigns a location on the page to each item, along with the UX display details. (3) A scoring phase where an LLM with vision scores all the generated SERPs based on how likely it can satisfy the user. It then send the one with highest score to rendering. GenSERP features two generation paradigms. First, coarse-to-fine, which allow it to approach optimal layout in a more manageable way, (2) beam search, which give it a better chance to hit the optimal solution compared to greedy decoding. Offline experimental results on real-world data demonstrate how LLMs can contextually organize heterogeneous search results on-the-fly and provide a promising user experience.
DUBLIN -- Document Understanding By Language-Image Network
May 24, 2023



Visual document understanding is a complex task that involves analyzing both the text and the visual elements in document images. Existing models often rely on manual feature engineering or domain-specific pipelines, which limit their generalization ability across different document types and languages. In this paper, we propose DUBLIN, which is pretrained on web pages using three novel objectives: Masked Document Content Generation Task, Bounding Box Task, and Rendered Question Answering Task, that leverage both the spatial and semantic information in the document images. Our model achieves competitive or state-of-the-art results on several benchmarks, such as Web-Based Structural Reading Comprehension, Document Visual Question Answering, Key Information Extraction, Diagram Understanding, and Table Question Answering. In particular, we show that DUBLIN is the first pixel-based model to achieve an EM of 77.75 and F1 of 84.25 on the WebSRC dataset. We also show that our model outperforms the current pixel-based SoTA models on DocVQA and AI2D datasets by 2% and 21%, respectively. Also, DUBLIN is the first ever pixel-based model which achieves comparable performance to text-based SoTA methods on XFUND dataset for Semantic Entity Recognition showcasing its multilingual capability. Moreover, we create new baselines for text-based datasets by rendering them as document images to promote research in this direction.
METRO: Efficient Denoising Pretraining of Large Scale Autoencoding Language Models with Model Generated Signals
Apr 16, 2022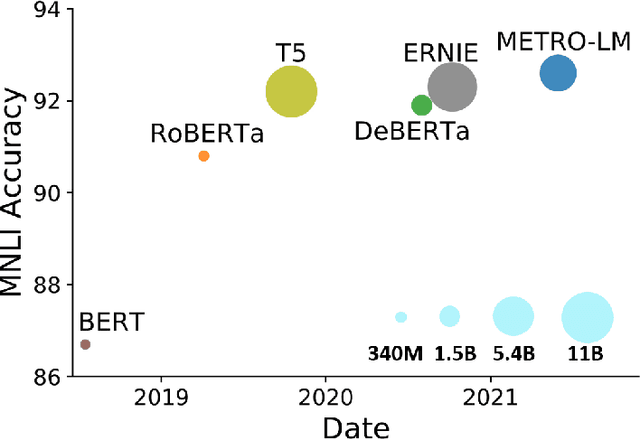
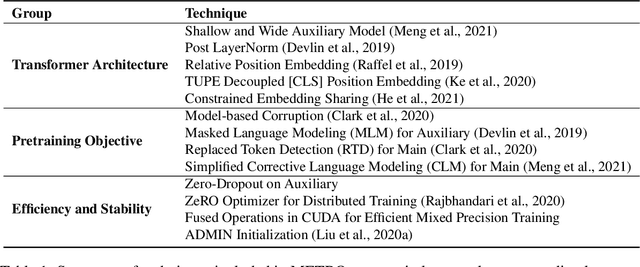
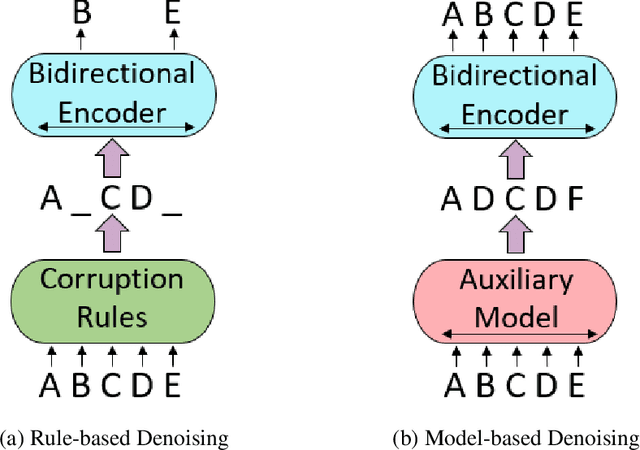
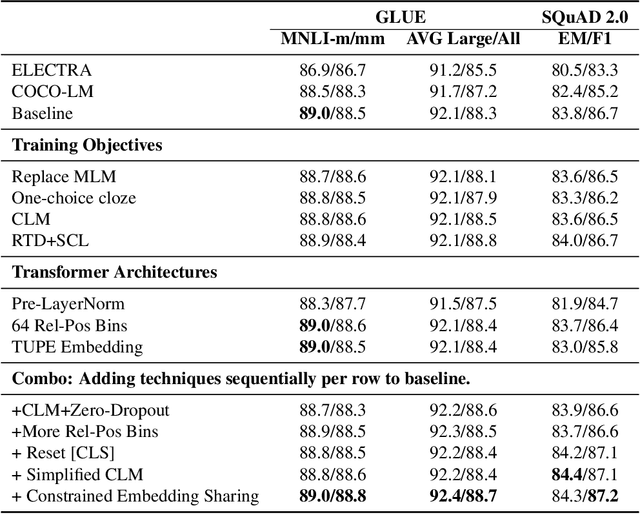
We present an efficient method of pretraining large-scale autoencoding language models using training signals generated by an auxiliary model. Originated in ELECTRA, this training strategy has demonstrated sample-efficiency to pretrain models at the scale of hundreds of millions of parameters. In this work, we conduct a comprehensive empirical study, and propose a recipe, namely "Model generated dEnoising TRaining Objective" (METRO), which incorporates some of the best modeling techniques developed recently to speed up, stabilize, and enhance pretrained language models without compromising model effectiveness. The resultant models, METRO-LM, consisting of up to 5.4 billion parameters, achieve new state-of-the-art on the GLUE, SuperGLUE, and SQuAD benchmarks. More importantly, METRO-LM are efficient in that they often outperform previous large models with significantly smaller model sizes and lower pretraining cost.
Pretraining Text Encoders with Adversarial Mixture of Training Signal Generators
Apr 07, 2022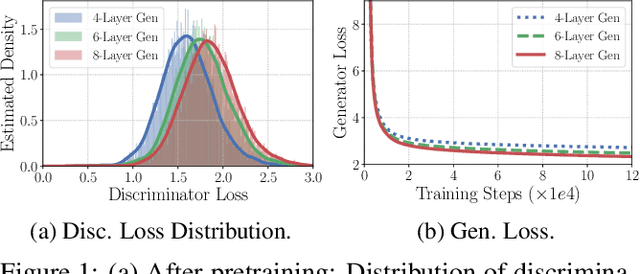
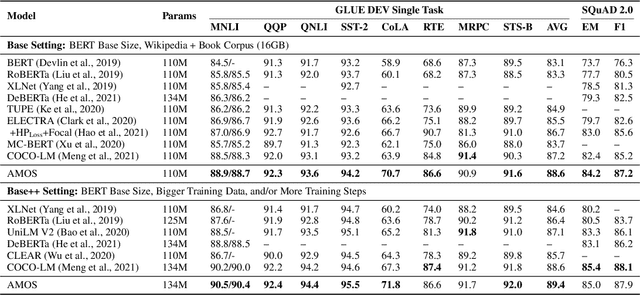
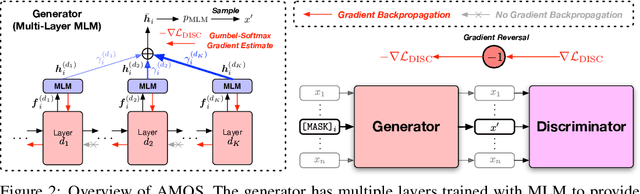
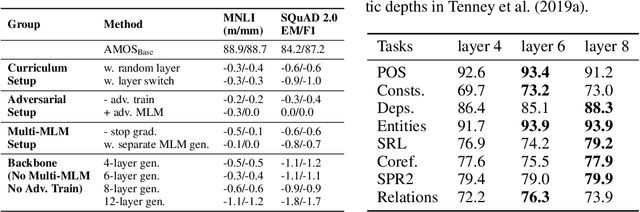
We present a new framework AMOS that pretrains text encoders with an Adversarial learning curriculum via a Mixture Of Signals from multiple auxiliary generators. Following ELECTRA-style pretraining, the main encoder is trained as a discriminator to detect replaced tokens generated by auxiliary masked language models (MLMs). Different from ELECTRA which trains one MLM as the generator, we jointly train multiple MLMs of different sizes to provide training signals at various levels of difficulty. To push the discriminator to learn better with challenging replaced tokens, we learn mixture weights over the auxiliary MLMs' outputs to maximize the discriminator loss by backpropagating the gradient from the discriminator via Gumbel-Softmax. For better pretraining efficiency, we propose a way to assemble multiple MLMs into one unified auxiliary model. AMOS outperforms ELECTRA and recent state-of-the-art pretrained models by about 1 point on the GLUE benchmark for BERT base-sized models.
Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model
Feb 04, 2022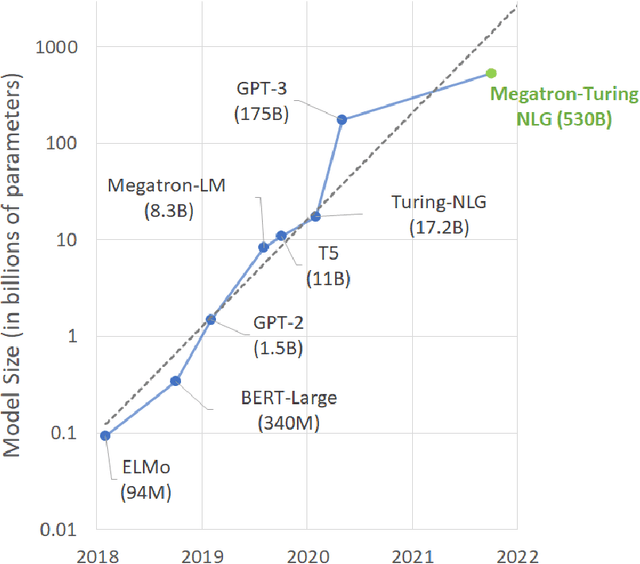
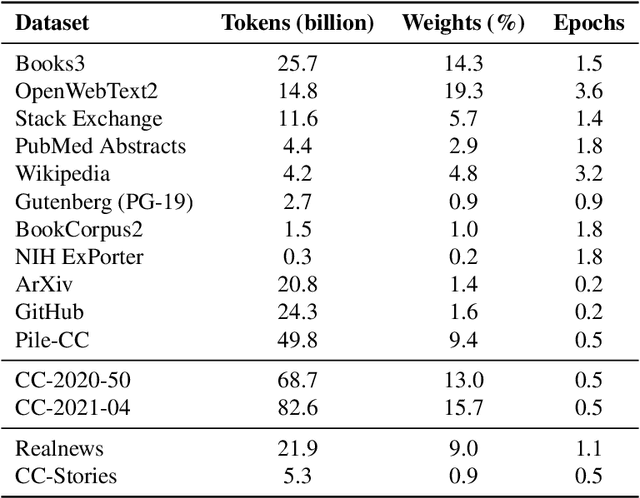
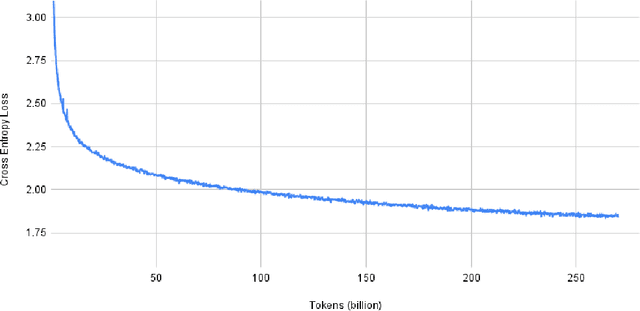
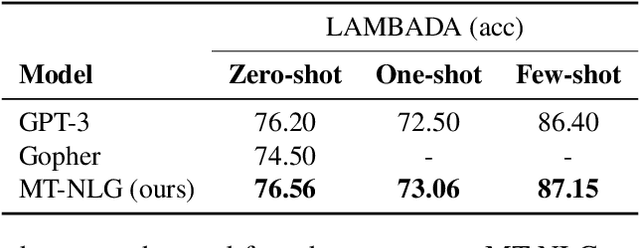
Pretrained general-purpose language models can achieve state-of-the-art accuracies in various natural language processing domains by adapting to downstream tasks via zero-shot, few-shot and fine-tuning techniques. Because of their success, the size of these models has increased rapidly, requiring high-performance hardware, software, and algorithmic techniques to enable training such large models. As the result of a joint effort between Microsoft and NVIDIA, we present details on the training of the largest monolithic transformer based language model, Megatron-Turing NLG 530B (MT-NLG), with 530 billion parameters. In this paper, we first focus on the infrastructure as well as the 3D parallelism methodology used to train this model using DeepSpeed and Megatron. Next, we detail the training process, the design of our training corpus, and our data curation techniques, which we believe is a key ingredient to the success of the model. Finally, we discuss various evaluation results, as well as other interesting observations and new properties exhibited by MT-NLG. We demonstrate that MT-NLG achieves superior zero-, one-, and few-shot learning accuracies on several NLP benchmarks and establishes new state-of-the-art results. We believe that our contributions will help further the development of large-scale training infrastructures, large-scale language models, and natural language generations.
COCO-LM: Correcting and Contrasting Text Sequences for Language Model Pretraining
Feb 16, 2021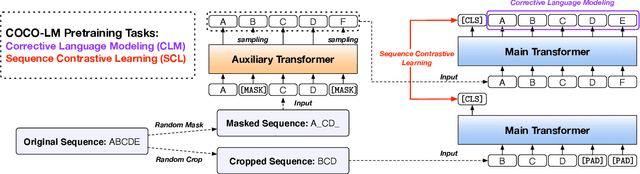
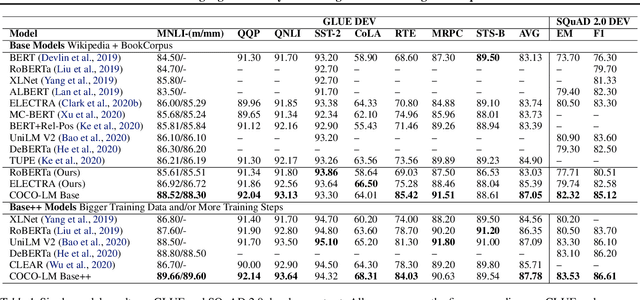
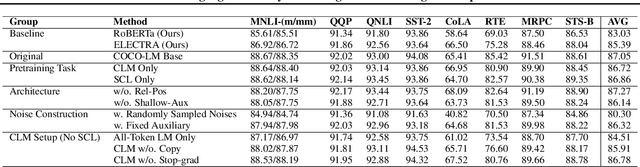
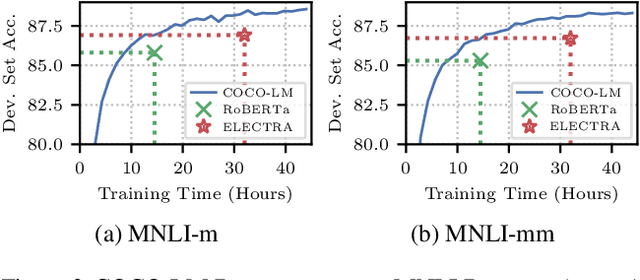
We present COCO-LM, a new self-supervised learning framework that pretrains Language Models by COrrecting challenging errors and COntrasting text sequences. COCO-LM employs an auxiliary language model to mask-and-predict tokens in original text sequences. It creates more challenging pretraining inputs, where noises are sampled based on their likelihood in the auxiliary language model. COCO-LM then pretrains with two tasks: The first task, corrective language modeling, learns to correct the auxiliary model's corruptions by recovering the original tokens. The second task, sequence contrastive learning, ensures that the language model generates sequence representations that are invariant to noises and transformations. In our experiments on the GLUE and SQuAD benchmarks, COCO-LM outperforms recent pretraining approaches in various pretraining settings and few-shot evaluations, with higher pretraining efficiency. Our analyses reveal that COCO-LM's advantages come from its challenging training signals, more contextualized token representations, and regularized sequence representations.
Knowledge-Aware Language Model Pretraining
Jun 29, 2020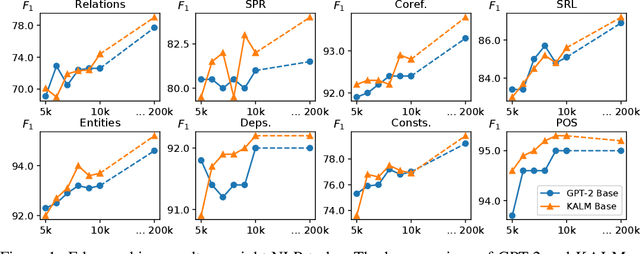
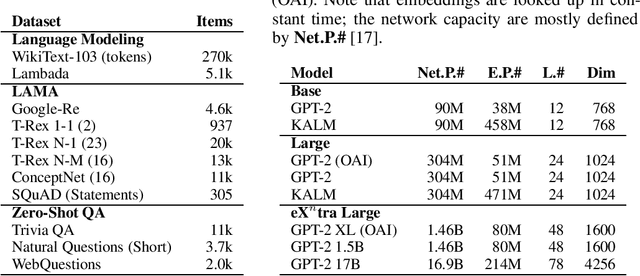
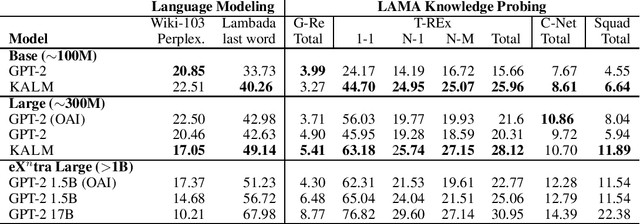
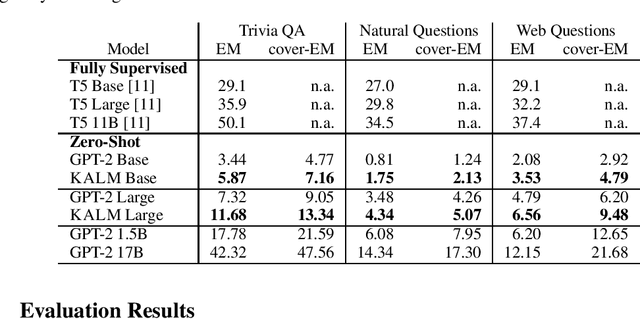
How much knowledge do pretrained language models hold? Recent research observed that pretrained transformers are adept at modeling semantics but it is unclear to what degree they grasp human knowledge, or how to ensure they do so. In this paper we incorporate knowledge-awareness in language model pretraining without changing the transformer architecture, inserting explicit knowledge layers, or adding external storage of semantic information. Rather, we simply signal the existence of entities to the input of the transformer in pretraining, with an entity-extended tokenizer; and at the output, with an additional entity prediction task. Our experiments show that solely by adding these entity signals in pretraining, significantly more knowledge is packed into the transformer parameters: we observe improved language modeling accuracy, factual correctness in LAMA knowledge probing tasks, and semantics in the hidden representations through edge probing.We also show that our knowledge-aware language model (KALM) can serve as a drop-in replacement for GPT-2 models, significantly improving downstream tasks like zero-shot question-answering with no task-related training.
Generic Intent Representation in Web Search
Jul 24, 2019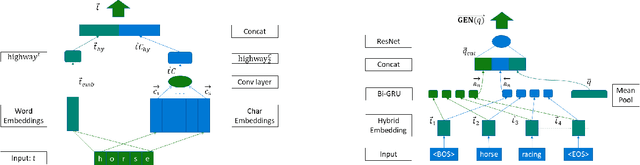


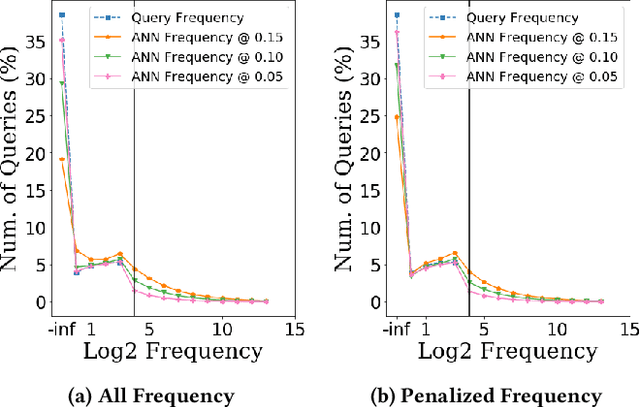
This paper presents GEneric iNtent Encoder (GEN Encoder) which learns a distributed representation space for user intent in search. Leveraging large scale user clicks from Bing search logs as weak supervision of user intent, GEN Encoder learns to map queries with shared clicks into similar embeddings end-to-end and then finetunes on multiple paraphrase tasks. Experimental results on an intrinsic evaluation task - query intent similarity modeling - demonstrate GEN Encoder's robust and significant advantages over previous representation methods. Ablation studies reveal the crucial role of learning from implicit user feedback in representing user intent and the contributions of multi-task learning in representation generality. We also demonstrate that GEN Encoder alleviates the sparsity of tail search traffic and cuts down half of the unseen queries by using an efficient approximate nearest neighbor search to effectively identify previous queries with the same search intent. Finally, we demonstrate distances between GEN encodings reflect certain information seeking behaviors in search sessions.
MS MARCO: A Human Generated MAchine Reading COmprehension Dataset
Oct 31, 2018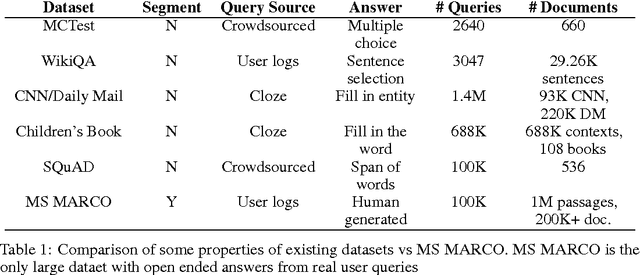
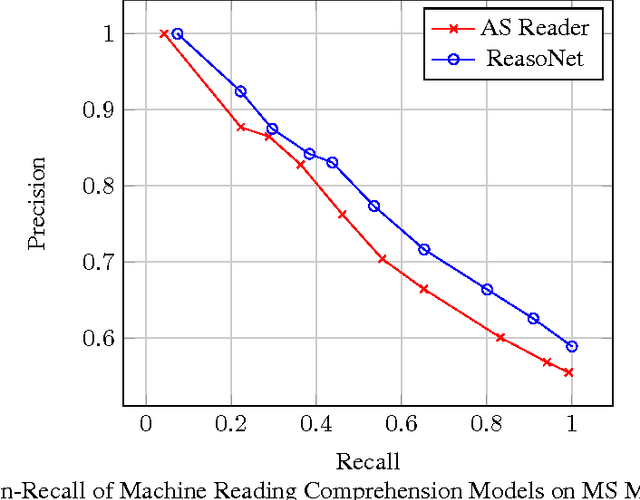

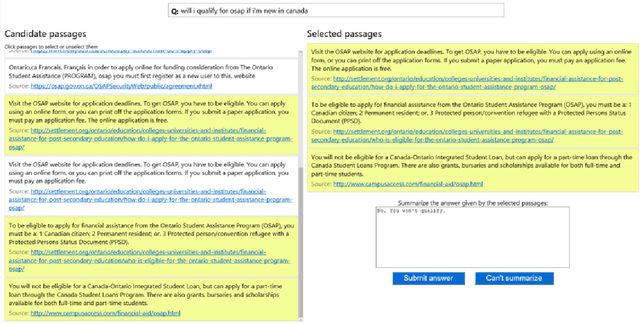
We introduce a large scale MAchine Reading COmprehension dataset, which we name MS MARCO. The dataset comprises of 1,010,916 anonymized questions---sampled from Bing's search query logs---each with a human generated answer and 182,669 completely human rewritten generated answers. In addition, the dataset contains 8,841,823 passages---extracted from 3,563,535 web documents retrieved by Bing---that provide the information necessary for curating the natural language answers. A question in the MS MARCO dataset may have multiple answers or no answers at all. Using this dataset, we propose three different tasks with varying levels of difficulty: (i) predict if a question is answerable given a set of context passages, and extract and synthesize the answer as a human would (ii) generate a well-formed answer (if possible) based on the context passages that can be understood with the question and passage context, and finally (iii) rank a set of retrieved passages given a question. The size of the dataset and the fact that the questions are derived from real user search queries distinguishes MS MARCO from other well-known publicly available datasets for machine reading comprehension and question-answering. We believe that the scale and the real-world nature of this dataset makes it attractive for benchmarking machine reading comprehension and question-answering models.