 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundationMotion: Auto-Labeling and Reasoning about Spatial Movement in Videos
Dec 11, 2025



Motion understanding is fundamental to physical reasoning, enabling models to infer dynamics and predict future states. However, state-of-the-art models still struggle on recent motion benchmarks, primarily due to the scarcity of large-scale, fine-grained motion datasets. Existing motion datasets are often constructed from costly manual annotation, severely limiting scalability. To address this challenge, we introduce FoundationMotion, a fully automated data curation pipeline that constructs large-scale motion datasets. Our approach first detects and tracks objects in videos to extract their trajectories, then leverages these trajectories and video frames with Large Language Models (LLMs) to generate fine-grained captions and diverse question-answer pairs about motion and spatial reasoning. Using datasets produced by this pipeline, we fine-tune open-source models including NVILA-Video-15B and Qwen2.5-7B, achieving substantial improvements in motion understanding without compromising performance on other tasks. Notably, our models outperform strong closed-source baselines like Gemini-2.5 Flash and large open-source models such as Qwen2.5-VL-72B across diverse motion understanding datasets and benchmarks. FoundationMotion thus provides a scalable solution for curating fine-grained motion datasets that enable effective fine-tuning of diverse models to enhance motion understanding and spatial reasoning capabilities.
Optimizing Mixture of Block Attention
Nov 14, 2025Mixture of Block Attention (MoBA) (Lu et al., 2025) is a promising building block for efficiently processing long contexts in LLMs by enabling queries to sparsely attend to a small subset of key-value blocks, drastically reducing computational cost. However, the design principles governing MoBA's performance are poorly understood, and it lacks an efficient GPU implementation, hindering its practical adoption. In this paper, we first develop a statistical model to analyze MoBA's underlying mechanics. Our model reveals that performance critically depends on the router's ability to accurately distinguish relevant from irrelevant blocks based on query-key affinities. We derive a signal-to-noise ratio that formally connects architectural parameters to this retrieval accuracy. Guided by our analysis, we identify two key pathways for improvement: using smaller block sizes and applying a short convolution on keys to cluster relevant signals, which enhances routing accuracy. While theoretically better, small block sizes are inefficient on GPUs. To bridge this gap, we introduce FlashMoBA, a hardware-aware CUDA kernel that enables efficient MoBA execution even with the small block sizes our theory recommends. We validate our insights by training LLMs from scratch, showing that our improved MoBA models match the performance of dense attention baselines. FlashMoBA achieves up to 14.7x speedup over FlashAttention-2 for small blocks, making our theoretically-grounded improvements practical. Code is available at: https://github.com/mit-han-lab/flash-moba.
ParoQuant: Pairwise Rotation Quantization for Efficient Reasoning LLM Inference
Nov 13, 2025Weight-only post-training quantization (PTQ) compresses the weights of Large Language Models (LLMs) into low-precision representations to reduce memory footprint and accelerate inference. However, the presence of outliers in weights and activations often leads to large quantization errors and severe accuracy degradation, especially in recent reasoning LLMs where errors accumulate across long chains of thought. Existing PTQ methods either fail to sufficiently suppress outliers or introduce significant overhead during inference. In this paper, we propose Pairwise Rotation Quantization (ParoQuant), a weight-only PTQ method that combines hardware-efficient and optimizable independent Givens rotations with channel-wise scaling to even out the magnitude across channels and narrow the dynamic range within each quantization group. We further co-design the inference kernel to fully exploit GPU parallelism and keep the rotations and scaling lightweight at runtime. ParoQuant achieves an average 2.4% accuracy improvement over AWQ on reasoning tasks with less than 10% overhead. This paves the way for more efficient and accurate deployment of reasoning LLMs.
StreamDiffusionV2: A Streaming System for Dynamic and Interactive Video Generation
Nov 10, 2025



Generative models are reshaping the live-streaming industry by redefining how content is created, styled, and delivered. Previous image-based streaming diffusion models have powered efficient and creative live streaming products but have hit limits on temporal consistency due to the foundation of image-based designs. Recent advances in video diffusion have markedly improved temporal consistency and sampling efficiency for offline generation. However, offline generation systems primarily optimize throughput by batching large workloads. In contrast, live online streaming operates under strict service-level objectives (SLOs): time-to-first-frame must be minimal, and every frame must meet a per-frame deadline with low jitter. Besides, scalable multi-GPU serving for real-time streams remains largely unresolved so far. To address this, we present StreamDiffusionV2, a training-free pipeline for interactive live streaming with video diffusion models. StreamDiffusionV2 integrates an SLO-aware batching scheduler and a block scheduler, together with a sink-token--guided rolling KV cache, a motion-aware noise controller, and other system-level optimizations. Moreover, we introduce a scalable pipeline orchestration that parallelizes the diffusion process across denoising steps and network layers, achieving near-linear FPS scaling without violating latency guarantees. The system scales seamlessly across heterogeneous GPU environments and supports flexible denoising steps (e.g., 1--4), enabling both ultra-low-latency and higher-quality modes. Without TensorRT or quantization, StreamDiffusionV2 renders the first frame within 0.5s and attains 58.28 FPS with a 14B-parameter model and 64.52 FPS with a 1.3B-parameter model on four H100 GPUs, making state-of-the-art generative live streaming practical and accessible--from individual creators to enterprise-scale platforms.
NVIDIA Nemotron Nano V2 VL
Nov 07, 2025We introduce Nemotron Nano V2 VL, the latest model of the Nemotron vision-language series designed for strong real-world document understanding, long video comprehension, and reasoning tasks. Nemotron Nano V2 VL delivers significant improvements over our previous model, Llama-3.1-Nemotron-Nano-VL-8B, across all vision and text domains through major enhancements in model architecture, datasets, and training recipes. Nemotron Nano V2 VL builds on Nemotron Nano V2, a hybrid Mamba-Transformer LLM, and innovative token reduction techniques to achieve higher inference throughput in long document and video scenarios. We are releasing model checkpoints in BF16, FP8, and FP4 formats and sharing large parts of our datasets, recipes and training code.
OckBench: Measuring the Efficiency of LLM Reasoning
Nov 07, 2025Large language models such as GPT-4, Claude 3, and the Gemini series have improved automated reasoning and code generation. However, existing benchmarks mainly focus on accuracy and output quality, and they ignore an important factor: decoding token efficiency. In real systems, generating 10,000 tokens versus 100,000 tokens leads to large differences in latency, cost, and energy. In this work, we introduce OckBench, a model-agnostic and hardware-agnostic benchmark that evaluates both accuracy and token count for reasoning and coding tasks. Through experiments comparing multiple open- and closed-source models, we uncover that many models with comparable accuracy differ wildly in token consumption, revealing that efficiency variance is a neglected but significant axis of differentiation. We further demonstrate Pareto frontiers over the accuracy-efficiency plane and argue for an evaluation paradigm shift: we should no longer treat tokens as "free" to multiply. OckBench provides a unified platform for measuring, comparing, and guiding research in token-efficient reasoning. Our benchmarks are available at https://ockbench.github.io/ .
StreamingVLM: Real-Time Understanding for Infinite Video Streams
Oct 10, 2025Vision-language models (VLMs) could power real-time assistants and autonomous agents, but they face a critical challenge: understanding near-infinite video streams without escalating latency and memory usage. Processing entire videos with full attention leads to quadratic computational costs and poor performance on long videos. Meanwhile, simple sliding window methods are also flawed, as they either break coherence or suffer from high latency due to redundant recomputation. In this paper, we introduce StreamingVLM, a model designed for real-time, stable understanding of infinite visual input. Our approach is a unified framework that aligns training with streaming inference. During inference, we maintain a compact KV cache by reusing states of attention sinks, a short window of recent vision tokens, and a long window of recent text tokens. This streaming ability is instilled via a simple supervised fine-tuning (SFT) strategy that applies full attention on short, overlapped video chunks, which effectively mimics the inference-time attention pattern without training on prohibitively long contexts. For evaluation, we build Inf-Streams-Eval, a new benchmark with videos averaging over two hours that requires dense, per-second alignment between frames and text. On Inf-Streams-Eval, StreamingVLM achieves a 66.18% win rate against GPT-4O mini and maintains stable, real-time performance at up to 8 FPS on a single NVIDIA H100. Notably, our SFT strategy also enhances general VQA abilities without any VQA-specific fine-tuning, improving performance on LongVideoBench by +4.30 and OVOBench Realtime by +5.96. Code is available at https://github.com/mit-han-lab/streaming-vlm.
LongLive: Real-time Interactive Long Video Generation
Sep 26, 2025We present LongLive, a frame-level autoregressive (AR) framework for real-time and interactive long video generation. Long video generation presents challenges in both efficiency and quality. Diffusion and Diffusion-Forcing models can produce high-quality videos but suffer from low efficiency due to bidirectional attention. Causal attention AR models support KV caching for faster inference, but often degrade in quality on long videos due to memory challenges during long-video training. In addition, beyond static prompt-based generation, interactive capabilities, such as streaming prompt inputs, are critical for dynamic content creation, enabling users to guide narratives in real time. This interactive requirement significantly increases complexity, especially in ensuring visual consistency and semantic coherence during prompt transitions. To address these challenges, LongLive adopts a causal, frame-level AR design that integrates a KV-recache mechanism that refreshes cached states with new prompts for smooth, adherent switches; streaming long tuning to enable long video training and to align training and inference (train-long-test-long); and short window attention paired with a frame-level attention sink, shorten as frame sink, preserving long-range consistency while enabling faster generation. With these key designs, LongLive fine-tunes a 1.3B-parameter short-clip model to minute-long generation in just 32 GPU-days. At inference, LongLive sustains 20.7 FPS on a single NVIDIA H100, achieves strong performance on VBench in both short and long videos. LongLive supports up to 240-second videos on a single H100 GPU. LongLive further supports INT8-quantized inference with only marginal quality loss.
3D Aware Region Prompted Vision Language Model
Sep 16, 2025

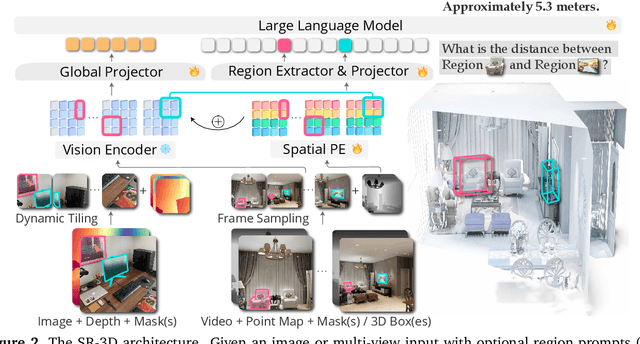

We present Spatial Region 3D (SR-3D) aware vision-language model that connects single-view 2D images and multi-view 3D data through a shared visual token space. SR-3D supports flexible region prompting, allowing users to annotate regions with bounding boxes, segmentation masks on any frame, or directly in 3D, without the need for exhaustive multi-frame labeling. We achieve this by enriching 2D visual features with 3D positional embeddings, which allows the 3D model to draw upon strong 2D priors for more accurate spatial reasoning across frames, even when objects of interest do not co-occur within the same view. Extensive experiments on both general 2D vision language and specialized 3D spatial benchmarks demonstrate that SR-3D achieves state-of-the-art performance, underscoring its effectiveness for unifying 2D and 3D representation space on scene understanding. Moreover, we observe applicability to in-the-wild videos without sensory 3D inputs or ground-truth 3D annotations, where SR-3D accurately infers spatial relationships and metric measurements.
Artificial Intelligence-Based Multiscale Temporal Modeling for Anomaly Detection in Cloud Services
Aug 20, 2025



This study proposes an anomaly detection method based on the Transformer architecture with integrated multiscale feature perception, aiming to address the limitations of temporal modeling and scale-aware feature representation in cloud service environments. The method first employs an improved Transformer module to perform temporal modeling on high-dimensional monitoring data, using a self-attention mechanism to capture long-range dependencies and contextual semantics. Then, a multiscale feature construction path is introduced to extract temporal features at different granularities through downsampling and parallel encoding. An attention-weighted fusion module is designed to dynamically adjust the contribution of each scale to the final decision, enhancing the model's robustness in anomaly pattern modeling. In the input modeling stage, standardized multidimensional time series are constructed, covering core signals such as CPU utilization, memory usage, and task scheduling states, while positional encoding is used to strengthen the model's temporal awareness. A systematic experimental setup is designed to evaluate performance, including comparative experiments and hyperparameter sensitivity analysis, focusing on the impact of optimizers, learning rates, anomaly ratios, and noise levels. Experimental results show that the proposed method outperforms mainstream baseline models in key metrics, including precision, recall, AUC, and F1-score, and maintains strong stability and detection performance under various perturbation conditions, demonstrating its superior capability in complex cloud environments.