 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRMArena-Pro: Holistic Assessment of LLM Agents Across Diverse Business Scenarios and Interactions
May 24, 2025While AI agents hold transformative potential in business, effective performance benchmarking is hindered by the scarcity of public, realistic business data on widely used platforms. Existing benchmarks often lack fidelity in their environments, data, and agent-user interactions, with limited coverage of diverse business scenarios and industries. To address these gaps, we introduce CRMArena-Pro, a novel benchmark for holistic, realistic assessment of LLM agents in diverse professional settings. CRMArena-Pro expands on CRMArena with nineteen expert-validated tasks across sales, service, and 'configure, price, and quote' processes, for both Business-to-Business and Business-to-Customer scenarios. It distinctively incorporates multi-turn interactions guided by diverse personas and robust confidentiality awareness assessments. Experiments reveal leading LLM agents achieve only around 58% single-turn success on CRMArena-Pro, with performance dropping significantly to approximately 35% in multi-turn settings. While Workflow Execution proves more tractable for top agents (over 83% single-turn success), other evaluated business skills present greater challenges. Furthermore, agents exhibit near-zero inherent confidentiality awareness; though targeted prompting can improve this, it often compromises task performance. These findings highlight a substantial gap between current LLM capabilities and enterprise demands, underscoring the need for advancements in multi-turn reasoning, confidentiality adherence, and versatile skill acquisition.
BLIP3-o: A Family of Fully Open Unified Multimodal Models-Architecture, Training and Dataset
May 14, 2025Unifying image understanding and generation has gained growing attention in recent research on multimodal models. Although design choices for image understanding have been extensively studied, the optimal model architecture and training recipe for a unified framework with image generation remain underexplored. Motivated by the strong potential of autoregressive and diffusion models for high-quality generation and scalability, we conduct a comprehensive study of their use in unified multimodal settings, with emphasis on image representations, modeling objectives, and training strategies. Grounded in these investigations, we introduce a novel approach that employs a diffusion transformer to generate semantically rich CLIP image features, in contrast to conventional VAE-based representations. This design yields both higher training efficiency and improved generative quality. Furthermore, we demonstrate that a sequential pretraining strategy for unified models-first training on image understanding and subsequently on image generation-offers practical advantages by preserving image understanding capability while developing strong image generation ability. Finally, we carefully curate a high-quality instruction-tuning dataset BLIP3o-60k for image generation by prompting GPT-4o with a diverse set of captions covering various scenes, objects, human gestures, and more. Building on our innovative model design, training recipe, and datasets, we develop BLIP3-o, a suite of state-of-the-art unified multimodal models. BLIP3-o achieves superior performance across most of the popular benchmarks spanning both image understanding and generation tasks. To facilitate future research, we fully open-source our models, including code, model weights, training scripts, and pretraining and instruction tuning datasets.
xGen-small Technical Report
May 10, 2025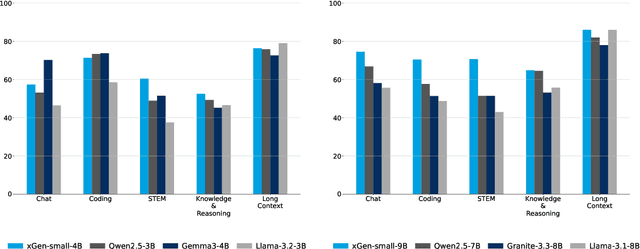
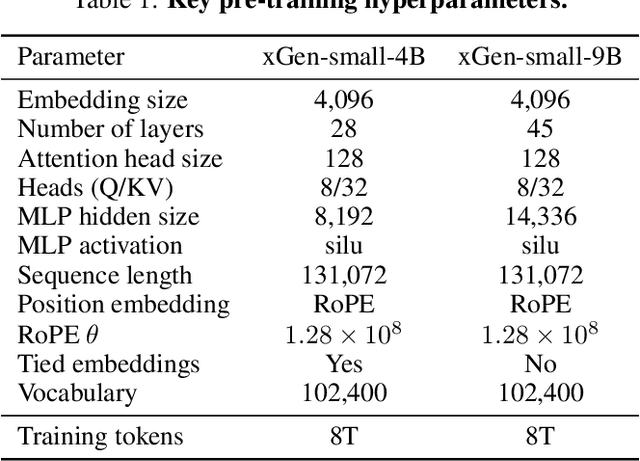
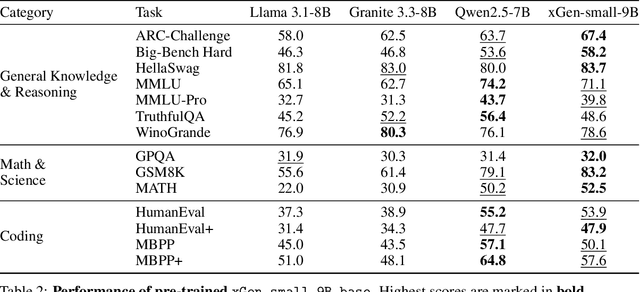
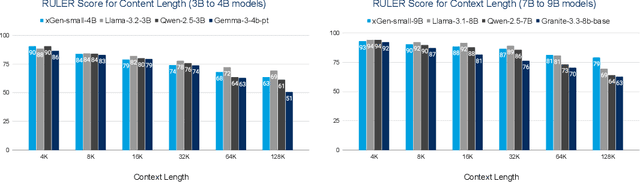
We introduce xGen-small, a family of 4B and 9B Transformer decoder models optimized for long-context applications. Our vertically integrated pipeline unites domain-balanced, frequency-aware data curation; multi-stage pre-training with quality annealing and length extension to 128k tokens; and targeted post-training via supervised fine-tuning, preference learning, and online reinforcement learning. xGen-small delivers strong performance across various tasks, especially in math and coding domains, while excelling at long context benchmarks.
LZ Penalty: An information-theoretic repetition penalty for autoregressive language models
Apr 28, 2025


We introduce the LZ penalty, a penalty specialized for reducing degenerate repetitions in autoregressive language models without loss of capability. The penalty is based on the codelengths in the LZ77 universal lossless compression algorithm. Through the lens of the prediction-compression duality, decoding the LZ penalty has the interpretation of sampling from the residual distribution after removing the information that is highly compressible. We demonstrate the LZ penalty enables state-of-the-art open-source reasoning models to operate with greedy (temperature zero) decoding without loss of capability and without instances of degenerate repetition. Both the industry-standard frequency penalty and repetition penalty are ineffective, incurring degenerate repetition rates of up to 4%.
DyMU: Dynamic Merging and Virtual Unmerging for Efficient VLMs
Apr 23, 2025



We present DyMU, an efficient, training-free framework that dynamically reduces the computational burden of vision-language models (VLMs) while maintaining high task performance. Our approach comprises two key components. First, Dynamic Token Merging (DToMe) reduces the number of visual token embeddings by merging similar tokens based on image complexity, addressing the inherent inefficiency of fixed-length outputs in vision transformers. Second, Virtual Token Unmerging (VTU) simulates the expected token sequence for large language models (LLMs) by efficiently reconstructing the attention dynamics of a full sequence, thus preserving the downstream performance without additional fine-tuning. Unlike previous approaches, our method dynamically adapts token compression to the content of the image and operates completely training-free, making it readily applicable to most state-of-the-art VLM architectures. Extensive experiments on image and video understanding tasks demonstrate that DyMU can reduce the average visual token count by 32%-85% while achieving comparable performance to full-length models across diverse VLM architectures, including the recently popularized AnyRes-based visual encoders. Furthermore, through qualitative analyses, we demonstrate that DToMe effectively adapts token reduction based on image complexity and, unlike existing systems, provides users more control over computational costs. Project page: https://mikewangwzhl.github.io/dymu/.
A Survey of Frontiers in LLM Reasoning: Inference Scaling, Learning to Reason, and Agentic Systems
Apr 12, 2025



Reasoning is a fundamental cognitive process that enables logical inference, problem-solving, and decision-making. With the rapid advancement of large language models (LLMs), reasoning has emerged as a key capability that distinguishes advanced AI systems from conventional models that empower chatbots. In this survey, we categorize existing methods along two orthogonal dimensions: (1) Regimes, which define the stage at which reasoning is achieved (either at inference time or through dedicated training); and (2) Architectures, which determine the components involved in the reasoning process, distinguishing between standalone LLMs and agentic compound systems that incorporate external tools, and multi-agent collaborations. Within each dimension, we analyze two key perspectives: (1) Input level, which focuses on techniques that construct high-quality prompts that the LLM condition on; and (2) Output level, which methods that refine multiple sampled candidates to enhance reasoning quality. This categorization provides a systematic understanding of the evolving landscape of LLM reasoning, highlighting emerging trends such as the shift from inference-scaling to learning-to-reason (e.g., DeepSeek-R1), and the transition to agentic workflows (e.g., OpenAI Deep Research, Manus Agent). Additionally, we cover a broad spectrum of learning algorithms, from supervised fine-tuning to reinforcement learning such as PPO and GRPO, and the training of reasoners and verifiers. We also examine key designs of agentic workflows, from established patterns like generator-evaluator and LLM debate to recent innovations. ...
APIGen-MT: Agentic Pipeline for Multi-Turn Data Generation via Simulated Agent-Human Interplay
Apr 08, 2025Training effective AI agents for multi-turn interactions requires high-quality data that captures realistic human-agent dynamics, yet such data is scarce and expensive to collect manually. We introduce APIGen-MT, a two-phase framework that generates verifiable and diverse multi-turn agent data. In the first phase, our agentic pipeline produces detailed task blueprints with ground-truth actions, leveraging a committee of LLM reviewers and iterative feedback loops. These blueprints are then transformed into complete interaction trajectories through simulated human-agent interplay. We train a family of models -- the xLAM-2-fc-r series with sizes ranging from 1B to 70B parameters. Our models outperform frontier models such as GPT-4o and Claude 3.5 on $\tau$-bench and BFCL benchmarks, with the smaller models surpassing their larger counterparts, particularly in multi-turn settings, while maintaining superior consistency across multiple trials. Comprehensive experiments demonstrate that our verified blueprint-to-details approach yields high-quality training data, enabling the development of more reliable, efficient, and capable agents. We open-source both the synthetic data collected and the trained xLAM-2-fc-r models to advance research in AI agents. Models are available on HuggingFace at https://huggingface.co/collections/Salesforce/xlam-2-67ef5be12949d8dcdae354c4 and project website is https://apigen-mt.github.io
Entropy-Based Block Pruning for Efficient Large Language Models
Apr 04, 2025



As large language models continue to scale, their growing computational and storage demands pose significant challenges for real-world deployment. In this work, we investigate redundancy within Transformer-based models and propose an entropy-based pruning strategy to enhance efficiency while maintaining performance. Empirical analysis reveals that the entropy of hidden representations decreases in the early blocks but progressively increases across most subsequent blocks. This trend suggests that entropy serves as a more effective measure of information richness within computation blocks. Unlike cosine similarity, which primarily captures geometric relationships, entropy directly quantifies uncertainty and information content, making it a more reliable criterion for pruning. Extensive experiments demonstrate that our entropy-based pruning approach surpasses cosine similarity-based methods in reducing model size while preserving accuracy, offering a promising direction for efficient model deployment.
ActionStudio: A Lightweight Framework for Data and Training of Large Action Models
Mar 31, 2025Action models are essential for enabling autonomous agents to perform complex tasks. However, training large action models remains challenging due to the diversity of agent environments and the complexity of agentic data. Despite growing interest, existing infrastructure provides limited support for scalable, agent-specific fine-tuning. We present ActionStudio, a lightweight and extensible data and training framework designed for large action models. ActionStudio unifies heterogeneous agent trajectories through a standardized format, supports diverse training paradigms including LoRA, full fine-tuning, and distributed setups, and integrates robust preprocessing and verification tools. We validate its effectiveness across both public and realistic industry benchmarks, demonstrating strong performance and practical scalability. We open-sourced code and data at https://github.com/SalesforceAIResearch/xLAM to facilitate research in the community.
Empowering Time Series Analysis with Synthetic Data: A Survey and Outlook in the Era of Foundation Models
Mar 14, 2025



Time series analysis is crucial for understanding dynamics of complex systems. Recent advances in foundation models have led to task-agnostic Time Series Foundation Models (TSFMs) and Large Language Model-based Time Series Models (TSLLMs), enabling generalized learning and integrating contextual information. However, their success depends on large, diverse, and high-quality datasets, which are challenging to build due to regulatory, diversity, quality, and quantity constraints. Synthetic data emerge as a viable solution, addressing these challenges by offering scalable, unbiased, and high-quality alternatives. This survey provides a comprehensive review of synthetic data for TSFMs and TSLLMs, analyzing data generation strategies, their role in model pretraining, fine-tuning, and evaluation, and identifying future research directions.