 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLZ Penalty: An information-theoretic repetition penalty for autoregressive language models
Apr 28, 2025


We introduce the LZ penalty, a penalty specialized for reducing degenerate repetitions in autoregressive language models without loss of capability. The penalty is based on the codelengths in the LZ77 universal lossless compression algorithm. Through the lens of the prediction-compression duality, decoding the LZ penalty has the interpretation of sampling from the residual distribution after removing the information that is highly compressible. We demonstrate the LZ penalty enables state-of-the-art open-source reasoning models to operate with greedy (temperature zero) decoding without loss of capability and without instances of degenerate repetition. Both the industry-standard frequency penalty and repetition penalty are ineffective, incurring degenerate repetition rates of up to 4%.
Asynchronous Tool Usage for Real-Time Agents
Oct 28, 2024


While frontier large language models (LLMs) are capable tool-using agents, current AI systems still operate in a strict turn-based fashion, oblivious to passage of time. This synchronous design forces user queries and tool-use to occur sequentially, preventing the systems from multitasking and reducing interactivity. To address this limitation, we introduce asynchronous AI agents capable of parallel processing and real-time tool-use. Our key contribution is an event-driven finite-state machine architecture for agent execution and prompting, integrated with automatic speech recognition and text-to-speech. Drawing inspiration from the concepts originally developed for real-time operating systems, this work presents both a conceptual framework and practical tools for creating AI agents capable of fluid, multitasking interactions.
On Convergence and Stability of GANs
Dec 10, 2017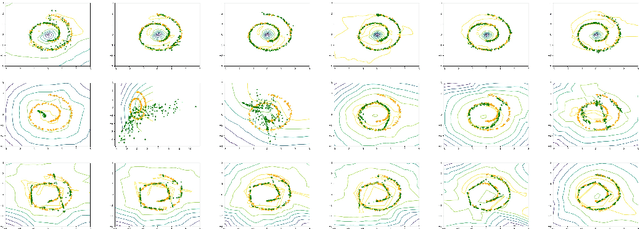
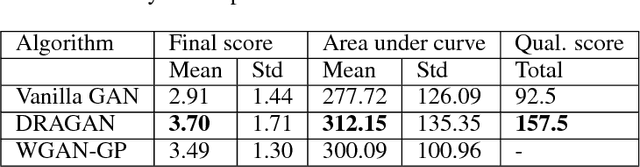
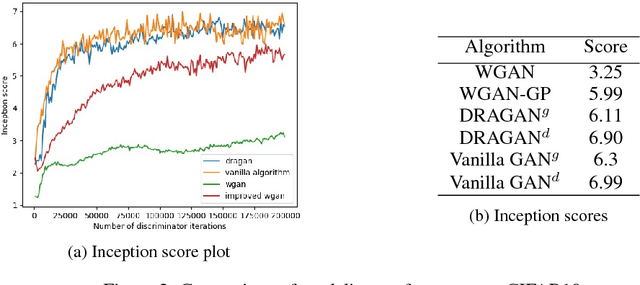
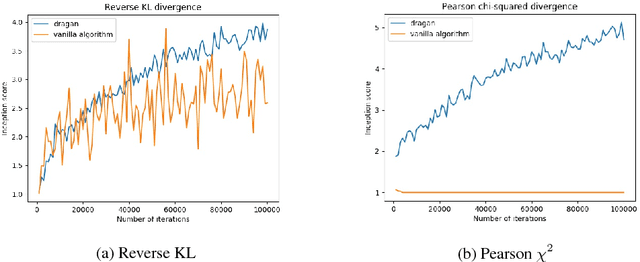
We propose studying GAN training dynamics as regret minimization, which is in contrast to the popular view that there is consistent minimization of a divergence between real and generated distributions. We analyze the convergence of GAN training from this new point of view to understand why mode collapse happens. We hypothesize the existence of undesirable local equilibria in this non-convex game to be responsible for mode collapse. We observe that these local equilibria often exhibit sharp gradients of the discriminator function around some real data points. We demonstrate that these degenerate local equilibria can be avoided with a gradient penalty scheme called DRAGAN. We show that DRAGAN enables faster training, achieves improved stability with fewer mode collapses, and leads to generator networks with better modeling performance across a variety of architectures and objective functions.