 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAM: Torque Adaptation Module for Robust Motion Transfer in Manipulation
Jun 04, 2026A policy tuned for one robot often behaves differently on another, whether due to the sim-to-real gap, unknown payloads, or the differing dynamics of two instances of the same robot. In contact-rich, dynamic manipulation, even small motion discrepancies can result in failure to track reference motion, since they disrupt the timing and modes of contact. Common remedies, such as domain randomization or system identification, either produce overly conservative task policies or require data that must be recollected for each robot or payload. We introduce the Torque Adaptation Module (TAM), a learned module that adapts the torque commands sent to the robot to match the behavior of an ideal robot. TAM operates between the low-level controller that tracks the policy's actions and the robot's torque interface. It includes a history encoder that embeds proprioceptive history into a latent state and a torque adaptor that computes residual torque corrections. Because TAM depends only on proprioceptive history and not on policy observations, or the action space, the same TAM weights can be reused to adapt policies with different action spaces (joint targets, end-effector targets, or direct torques). The policies themselves do not need to be trained with domain randomization of robot parameters. Instead, we offload the need for domain randomization to TAM by training it entirely in randomized simulation, using multi-robot pretraining followed by a robot-specific fine-tuning step that still requires no real-robot data. We evaluate TAM zero-shot on a real Franka Panda robot across dynamic manipulation tasks that include a vision-based box pushing policy (from RL), a flip policy (from BC), and an MPC ball-on-plate balancing. Our experiments show that TAM improves zero-shot real-robot execution compared to online system identification and RMA baselines and enables robust dynamic manipulation performance.
ÜberWeb: Insights from Multilingual Curation for a 20-Trillion-Token Dataset
Feb 16, 2026Multilinguality is a core capability for modern foundation models, yet training high-quality multilingual models remains challenging due to uneven data availability across languages. A further challenge is the performance interference that can arise from joint multilingual training, commonly referred to as the "curse of multilinguality". We study multilingual data curation across thirteen languages and find that many reported regressions are not inherent to multilingual scaling but instead stem from correctable deficiencies in data quality and composition rather than fundamental capacity limits. In controlled bilingual experiments, improving data quality for any single language benefits others: curating English improves non-English performance in 12 of 13 languages, while curating non-English yields reciprocal improvements in English. Bespoke per-language curation produces substantially larger within-language improvements. Extending these findings to large-scale general-purpose training mixtures, we show that curated multilingual allocations comprising under 8% of total tokens remain remarkably effective. We operationalize this approach within an effort that produced a 20T-token pretraining corpus derived entirely from public sources. Models with 3B and 8B parameters trained on a 1T-token random subset achieve competitive multilingual accuracy with 4-10x fewer training FLOPs than strong public baselines, establishing a new Pareto frontier in multilingual performance versus compute. Moreover, these benefits extend to frontier model scale: the 20T-token corpus served as part of the pretraining dataset for Trinity Large (400B/A13B), which exhibits strong multilingual performance relative to its training FLOPs. These results show that targeted, per-language data curation mitigates multilingual interference and enables compute-efficient multilingual scaling.
DatBench: Discriminative, Faithful, and Efficient VLM Evaluations
Jan 05, 2026Empirical evaluation serves as the primary compass guiding research progress in foundation models. Despite a large body of work focused on training frontier vision-language models (VLMs), approaches to their evaluation remain nascent. To guide their maturation, we propose three desiderata that evaluations should satisfy: (1) faithfulness to the modality and application, (2) discriminability between models of varying quality, and (3) efficiency in compute. Through this lens, we identify critical failure modes that violate faithfulness and discriminability, misrepresenting model capabilities: (i) multiple-choice formats reward guessing, poorly reflect downstream use cases, and saturate early as models improve; (ii) blindly solvable questions, which can be answered without images, constitute up to 70% of some evaluations; and (iii) mislabeled or ambiguous samples compromise up to 42% of examples in certain datasets. Regarding efficiency, the computational burden of evaluating frontier models has become prohibitive: by some accounts, nearly 20% of development compute is devoted to evaluation alone. Rather than discarding existing benchmarks, we curate them via transformation and filtering to maximize fidelity and discriminability. We find that converting multiple-choice questions to generative tasks reveals sharp capability drops of up to 35%. In addition, filtering blindly solvable and mislabeled samples improves discriminative power while simultaneously reducing computational cost. We release DatBench-Full, a cleaned evaluation suite of 33 datasets spanning nine VLM capabilities, and DatBench, a discriminative subset that achieves 13x average speedup (up to 50x) while closely matching the discriminative power of the original datasets. Our work outlines a path toward evaluation practices that are both rigorous and sustainable as VLMs continue to scale.
Luxical: High-Speed Lexical-Dense Text Embeddings
Dec 11, 2025Frontier language model quality increasingly hinges on our ability to organize web-scale text corpora for training. Today's dominant tools trade off speed and flexibility: lexical classifiers (e.g., FastText) are fast but limited to producing classification output scores, while the vector-valued outputs of transformer text embedding models flexibly support numerous workflows (e.g., clustering, classification, and retrieval) but are computationally expensive to produce. We introduce Luxical, a library for high-speed "lexical-dense" text embeddings that aims to recover the best properties of both approaches for web-scale text organization. Luxical combines sparse TF--IDF features, a small ReLU network, and a knowledge distillation training regimen to approximate large transformer embedding models at a fraction of their operational cost. In this technical report, we describe the Luxical architecture and training objective and evaluate a concrete Luxical model in two disparate applications: a targeted webcrawl document retrieval test and an end-to-end language model data curation task grounded in text classification. In these tasks we demonstrate speedups ranging from 3x to 100x over varying-sized neural baselines, and comparable to FastText model inference during the data curation task. On these evaluations, the tested Luxical model illustrates favorable compute/quality trade-offs for large-scale text organization, matching the quality of neural baselines. Luxical is available as open-source software at https://github.com/datologyai/luxical.
MolmoAct: Action Reasoning Models that can Reason in Space
Aug 12, 2025



Reasoning is central to purposeful action, yet most robotic foundation models map perception and instructions directly to control, which limits adaptability, generalization, and semantic grounding. We introduce Action Reasoning Models (ARMs), a class of robotic foundation models that integrate perception, planning, and control through a structured three-stage pipeline. Our model, MolmoAct, encodes observations and instructions into depth-aware perception tokens, generates mid-level spatial plans as editable trajectory traces, and predicts precise low-level actions, enabling explainable and steerable behavior. MolmoAct-7B-D achieves strong performance across simulation and real-world settings: 70.5% zero-shot accuracy on SimplerEnv Visual Matching tasks, surpassing closed-source Pi-0 and GR00T N1; 86.6% average success on LIBERO, including an additional 6.3% gain over ThinkAct on long-horizon tasks; and in real-world fine-tuning, an additional 10% (single-arm) and an additional 22.7% (bimanual) task progression over Pi-0-FAST. It also outperforms baselines by an additional 23.3% on out-of-distribution generalization and achieves top human-preference scores for open-ended instruction following and trajectory steering. Furthermore, we release, for the first time, the MolmoAct Dataset -- a mid-training robot dataset comprising over 10,000 high quality robot trajectories across diverse scenarios and tasks. Training with this dataset yields an average 5.5% improvement in general performance over the base model. We release all model weights, training code, our collected dataset, and our action reasoning dataset, establishing MolmoAct as both a state-of-the-art robotics foundation model and an open blueprint for building ARMs that transform perception into purposeful action through structured reasoning. Blogpost: https://allenai.org/blog/molmoact
PointArena: Probing Multimodal Grounding Through Language-Guided Pointing
May 15, 2025Pointing serves as a fundamental and intuitive mechanism for grounding language within visual contexts, with applications spanning robotics, assistive technologies, and interactive AI systems. While recent multimodal models have started to support pointing capabilities, existing benchmarks typically focus only on referential object localization tasks. We introduce PointArena, a comprehensive platform for evaluating multimodal pointing across diverse reasoning scenarios. PointArena comprises three components: (1) Point-Bench, a curated dataset containing approximately 1,000 pointing tasks across five reasoning categories; (2) Point-Battle, an interactive, web-based arena facilitating blind, pairwise model comparisons, which has already gathered over 4,500 anonymized votes; and (3) Point-Act, a real-world robotic manipulation system allowing users to directly evaluate multimodal model pointing capabilities in practical settings. We conducted extensive evaluations of both state-of-the-art open-source and proprietary multimodal models. Results indicate that Molmo-72B consistently outperforms other models, though proprietary models increasingly demonstrate comparable performance. Additionally, we find that supervised training specifically targeting pointing tasks significantly enhances model performance. Across our multi-stage evaluation pipeline, we also observe strong correlations, underscoring the critical role of precise pointing capabilities in enabling multimodal models to effectively bridge abstract reasoning with concrete, real-world actions. Project page: https://pointarena.github.io/
LZ Penalty: An information-theoretic repetition penalty for autoregressive language models
Apr 28, 2025


We introduce the LZ penalty, a penalty specialized for reducing degenerate repetitions in autoregressive language models without loss of capability. The penalty is based on the codelengths in the LZ77 universal lossless compression algorithm. Through the lens of the prediction-compression duality, decoding the LZ penalty has the interpretation of sampling from the residual distribution after removing the information that is highly compressible. We demonstrate the LZ penalty enables state-of-the-art open-source reasoning models to operate with greedy (temperature zero) decoding without loss of capability and without instances of degenerate repetition. Both the industry-standard frequency penalty and repetition penalty are ineffective, incurring degenerate repetition rates of up to 4%.
Cross-Modal State-Space Graph Reasoning for Structured Summarization
Mar 26, 2025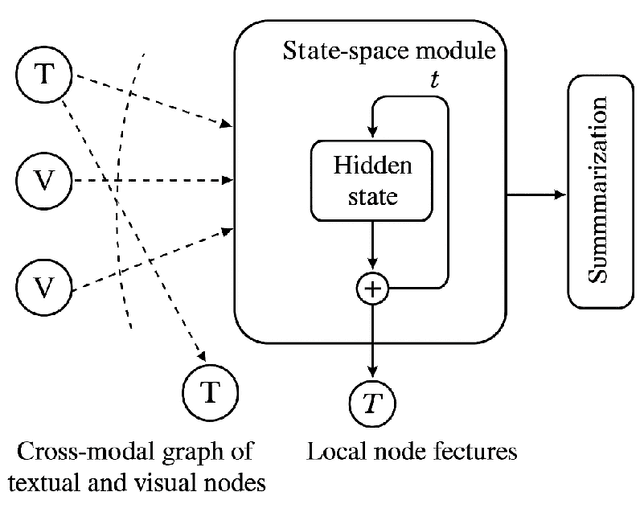
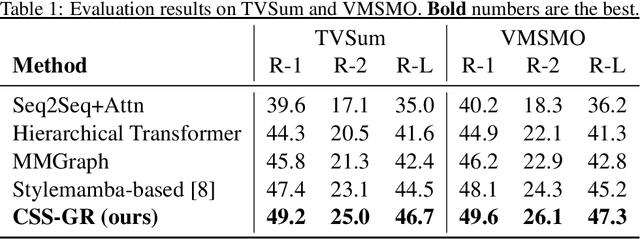
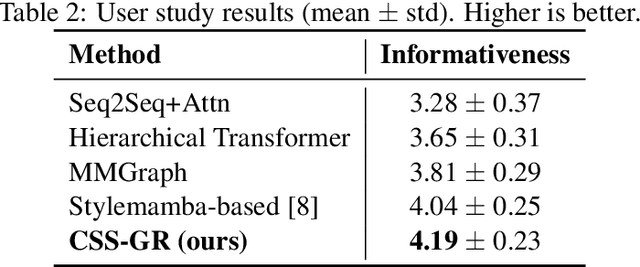
The ability to extract compact, meaningful summaries from large-scale and multimodal data is critical for numerous applications, ranging from video analytics to medical reports. Prior methods in cross-modal summarization have often suffered from high computational overheads and limited interpretability. In this paper, we propose a \textit{Cross-Modal State-Space Graph Reasoning} (\textbf{CSS-GR}) framework that incorporates a state-space model with graph-based message passing, inspired by prior work on efficient state-space models. Unlike existing approaches relying on purely sequential models, our method constructs a graph that captures inter- and intra-modal relationships, allowing more holistic reasoning over both textual and visual streams. We demonstrate that our approach significantly improves summarization quality and interpretability while maintaining computational efficiency, as validated on standard multimodal summarization benchmarks. We also provide a thorough ablation study to highlight the contributions of each component.
Shifting Attention to You: Personalized Brain-Inspired AI Models
Feb 07, 2025The integration of human and artificial intelligence represents a scientific opportunity to advance our understanding of information processing, as each system offers unique computational insights that can enhance and inform the other. The synthesis of human cognitive principles with artificial intelligence has the potential to produce more interpretable and functionally aligned computational models, while simultaneously providing a formal framework for investigating the neural mechanisms underlying perception, learning, and decision-making through systematic model comparisons and representational analyses. In this study, we introduce personalized brain-inspired modeling that integrates human behavioral embeddings and neural data to align with cognitive processes. We took a stepwise approach, fine-tuning the Contrastive Language-Image Pre-training (CLIP) model with large-scale behavioral decisions, group-level neural data, and finally, participant-level neural data within a broader framework that we have named CLIP-Human-Based Analysis (CLIP-HBA). We found that fine-tuning on behavioral data enhances its ability to predict human similarity judgments while indirectly aligning it with dynamic representations captured via MEG. To further gain mechanistic insights into the temporal evolution of cognitive processes, we introduced a model specifically fine-tuned on millisecond-level MEG neural dynamics (CLIP-HBA-MEG). This model resulted in enhanced temporal alignment with human neural processing while still showing improvement on behavioral alignment. Finally, we trained individualized models on participant-specific neural data, effectively capturing individualized neural dynamics and highlighting the potential for personalized AI systems. These personalized systems have far-reaching implications for the fields of medicine, cognitive research, human-computer interfaces, and AI development.
Metastable Dynamics of Chain-of-Thought Reasoning: Provable Benefits of Search, RL and Distillation
Feb 02, 2025A key paradigm to improve the reasoning capabilities of large language models (LLMs) is to allocate more inference-time compute to search against a verifier or reward model. This process can then be utilized to refine the pretrained model or distill its reasoning patterns into more efficient models. In this paper, we study inference-time compute by viewing chain-of-thought (CoT) generation as a metastable Markov process: easy reasoning steps (e.g., algebraic manipulations) form densely connected clusters, while hard reasoning steps (e.g., applying a relevant theorem) create sparse, low-probability edges between clusters, leading to phase transitions at longer timescales. Under this framework, we prove that implementing a search protocol that rewards sparse edges improves CoT by decreasing the expected number of steps to reach different clusters. In contrast, we establish a limit on reasoning capability when the model is restricted to local information of the pretrained graph. We also show that the information gained by search can be utilized to obtain a better reasoning model: (1) the pretrained model can be directly finetuned to favor sparse edges via policy gradient methods, and moreover (2) a compressed metastable representation of the reasoning dynamics can be distilled into a smaller, more efficient model.