 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceptionComp: A Video Benchmark for Complex Perception-Centric Reasoning
Mar 27, 2026We introduce PerceptionComp, a manually annotated benchmark for complex, long-horizon, perception-centric video reasoning. PerceptionComp is designed so that no single moment is sufficient: answering each question requires multiple temporally separated pieces of visual evidence and compositional constraints under conjunctive and sequential logic, spanning perceptual subtasks such as objects, attributes, relations, locations, actions, and events, and requiring skills including semantic recognition, visual correspondence, temporal reasoning, and spatial reasoning. The benchmark contains 1,114 highly complex questions on 279 videos from diverse domains including city walk tours, indoor villa tours, video games, and extreme outdoor sports, with 100% manual annotation. Human studies show that PerceptionComp requires substantial test-time thinking and repeated perception steps: participants take much longer than on prior benchmarks, and accuracy drops to near chance (18.97%) when rewatching is disallowed. State-of-the-art MLLMs also perform substantially worse on PerceptionComp than on existing benchmarks: the best model in our evaluation, Gemini-3-Flash, reaches only 45.96% accuracy in the five-choice setting, while open-source models remain below 40%. These results suggest that perception-centric long-horizon video reasoning remains a major bottleneck, and we hope PerceptionComp will help drive progress in perceptual reasoning.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Unified Text-Image Generation with Weakness-Targeted Post-Training
Jan 07, 2026Unified multimodal generation architectures that jointly produce text and images have recently emerged as a promising direction for text-to-image (T2I) synthesis. However, many existing systems rely on explicit modality switching, generating reasoning text before switching manually to image generation. This separate, sequential inference process limits cross-modal coupling and prohibits automatic multimodal generation. This work explores post-training to achieve fully unified text-image generation, where models autonomously transition from textual reasoning to visual synthesis within a single inference process. We examine the impact of joint text-image generation on T2I performance and the relative importance of each modality during post-training. We additionally explore different post-training data strategies, showing that a targeted dataset addressing specific limitations achieves superior results compared to broad image-caption corpora or benchmark-aligned data. Using offline, reward-weighted post-training with fully self-generated synthetic data, our approach enables improvements in multimodal image generation across four diverse T2I benchmarks, demonstrating the effectiveness of reward-weighting both modalities and strategically designed post-training data.
Multimodal RewardBench 2: Evaluating Omni Reward Models for Interleaved Text and Image
Dec 18, 2025Reward models (RMs) are essential for training large language models (LLMs), but remain underexplored for omni models that handle interleaved image and text sequences. We introduce Multimodal RewardBench 2 (MMRB2), the first comprehensive benchmark for reward models on multimodal understanding and (interleaved) generation. MMRB2 spans four tasks: text-to-image, image editing, interleaved generation, and multimodal reasoning ("thinking-with-images"), providing 1,000 expert-annotated preference pairs per task from 23 models and agents across 21 source tasks. MMRB2 is designed with: (1) practical but challenging prompts; (2) responses from state-of-the-art models and agents; and (3) preference pairs with strong human-expert consensus, curated via an ensemble filtering strategy. Using MMRB2, we study existing judges for each subtask, including multimodal LLM-as-a-judge and models trained with human preferences. The latest Gemini 3 Pro attains 75-80% accuracy. GPT-5 and Gemini 2.5 Pro reach 66-75% accuracy, compared to >90% for humans, yet surpass the widely used GPT-4o (59%). The best performing open-source model Qwen3-VL-32B achieves similar accuracies as Gemini 2.5 Flash (64%). We also show that MMRB2 performance strongly correlates with downstream task success using Best-of-N sampling and conduct an in-depth analysis that shows key areas to improve the reward models going forward.
GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation
Dec 18, 2025



Automating Text-to-Image (T2I) model evaluation is challenging; a judge model must be used to score correctness, and test prompts must be selected to be challenging for current T2I models but not the judge. We argue that satisfying these constraints can lead to benchmark drift over time, where the static benchmark judges fail to keep up with newer model capabilities. We show that benchmark drift is a significant problem for GenEval, one of the most popular T2I benchmarks. Although GenEval was well-aligned with human judgment at the time of its release, it has drifted far from human judgment over time -- resulting in an absolute error of as much as 17.7% for current models. This level of drift strongly suggests that GenEval has been saturated for some time, as we verify via a large-scale human study. To help fill this benchmarking gap, we introduce a new benchmark, GenEval 2, with improved coverage of primitive visual concepts and higher degrees of compositionality, which we show is more challenging for current models. We also introduce Soft-TIFA, an evaluation method for GenEval 2 that combines judgments for visual primitives, which we show is more well-aligned with human judgment and argue is less likely to drift from human-alignment over time (as compared to more holistic judges such as VQAScore). Although we hope GenEval 2 will provide a strong benchmark for many years, avoiding benchmark drift is far from guaranteed and our work, more generally, highlights the importance of continual audits and improvement for T2I and related automated model evaluation benchmarks.
MMMG: a Comprehensive and Reliable Evaluation Suite for Multitask Multimodal Generation
May 23, 2025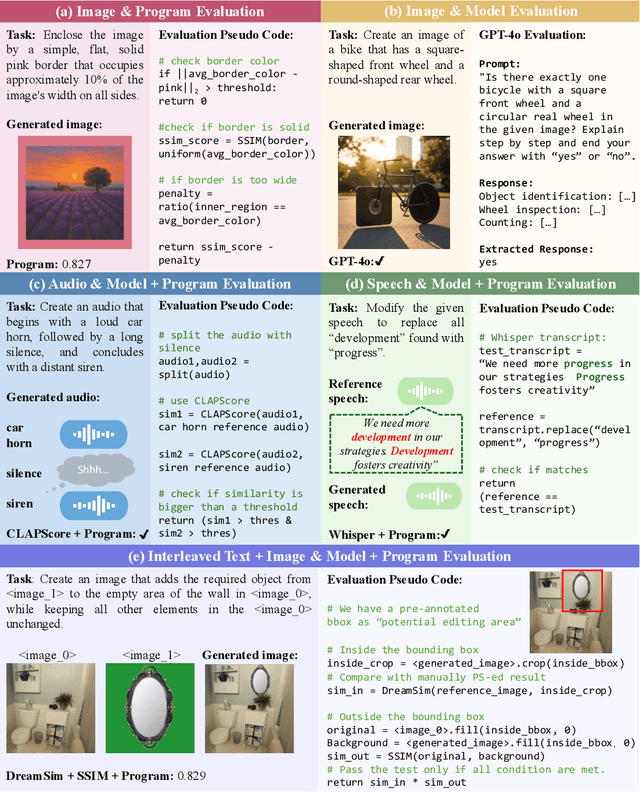
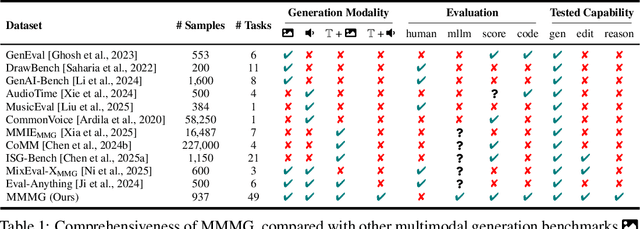
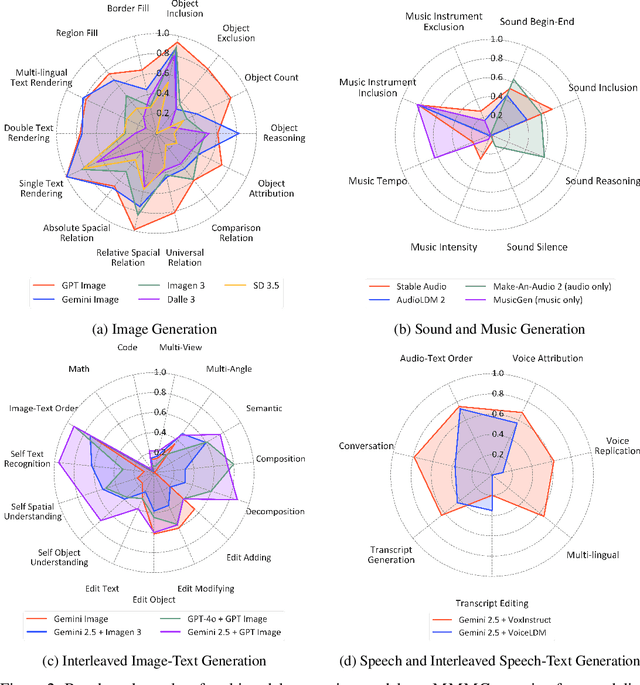
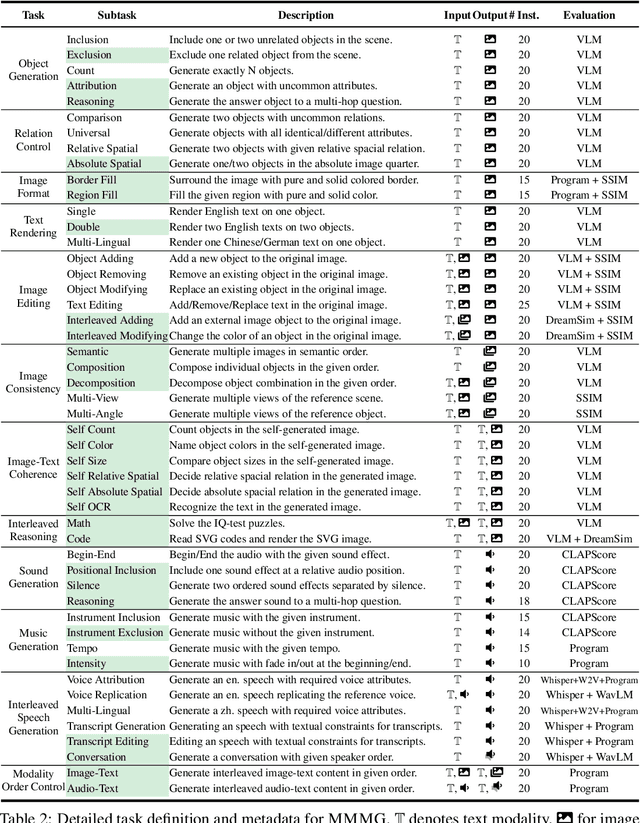
Automatically evaluating multimodal generation presents a significant challenge, as automated metrics often struggle to align reliably with human evaluation, especially for complex tasks that involve multiple modalities. To address this, we present MMMG, a comprehensive and human-aligned benchmark for multimodal generation across 4 modality combinations (image, audio, interleaved text and image, interleaved text and audio), with a focus on tasks that present significant challenges for generation models, while still enabling reliable automatic evaluation through a combination of models and programs. MMMG encompasses 49 tasks (including 29 newly developed ones), each with a carefully designed evaluation pipeline, and 937 instructions to systematically assess reasoning, controllability, and other key capabilities of multimodal generation models. Extensive validation demonstrates that MMMG is highly aligned with human evaluation, achieving an average agreement of 94.3%. Benchmarking results on 24 multimodal generation models reveal that even though the state-of-the-art model, GPT Image, achieves 78.3% accuracy for image generation, it falls short on multimodal reasoning and interleaved generation. Furthermore, results suggest considerable headroom for improvement in audio generation, highlighting an important direction for future research.
BLIP3-o: A Family of Fully Open Unified Multimodal Models-Architecture, Training and Dataset
May 14, 2025Unifying image understanding and generation has gained growing attention in recent research on multimodal models. Although design choices for image understanding have been extensively studied, the optimal model architecture and training recipe for a unified framework with image generation remain underexplored. Motivated by the strong potential of autoregressive and diffusion models for high-quality generation and scalability, we conduct a comprehensive study of their use in unified multimodal settings, with emphasis on image representations, modeling objectives, and training strategies. Grounded in these investigations, we introduce a novel approach that employs a diffusion transformer to generate semantically rich CLIP image features, in contrast to conventional VAE-based representations. This design yields both higher training efficiency and improved generative quality. Furthermore, we demonstrate that a sequential pretraining strategy for unified models-first training on image understanding and subsequently on image generation-offers practical advantages by preserving image understanding capability while developing strong image generation ability. Finally, we carefully curate a high-quality instruction-tuning dataset BLIP3o-60k for image generation by prompting GPT-4o with a diverse set of captions covering various scenes, objects, human gestures, and more. Building on our innovative model design, training recipe, and datasets, we develop BLIP3-o, a suite of state-of-the-art unified multimodal models. BLIP3-o achieves superior performance across most of the popular benchmarks spanning both image understanding and generation tasks. To facilitate future research, we fully open-source our models, including code, model weights, training scripts, and pretraining and instruction tuning datasets.
Eval3D: Interpretable and Fine-grained Evaluation for 3D Generation
Apr 25, 2025Despite the unprecedented progress in the field of 3D generation, current systems still often fail to produce high-quality 3D assets that are visually appealing and geometrically and semantically consistent across multiple viewpoints. To effectively assess the quality of the generated 3D data, there is a need for a reliable 3D evaluation tool. Unfortunately, existing 3D evaluation metrics often overlook the geometric quality of generated assets or merely rely on black-box multimodal large language models for coarse assessment. In this paper, we introduce Eval3D, a fine-grained, interpretable evaluation tool that can faithfully evaluate the quality of generated 3D assets based on various distinct yet complementary criteria. Our key observation is that many desired properties of 3D generation, such as semantic and geometric consistency, can be effectively captured by measuring the consistency among various foundation models and tools. We thus leverage a diverse set of models and tools as probes to evaluate the inconsistency of generated 3D assets across different aspects. Compared to prior work, Eval3D provides pixel-wise measurement, enables accurate 3D spatial feedback, and aligns more closely with human judgments. We comprehensively evaluate existing 3D generation models using Eval3D and highlight the limitations and challenges of current models.
Token-Shuffle: Towards High-Resolution Image Generation with Autoregressive Models
Apr 24, 2025Autoregressive (AR) models, long dominant in language generation, are increasingly applied to image synthesis but are often considered less competitive than Diffusion-based models. A primary limitation is the substantial number of image tokens required for AR models, which constrains both training and inference efficiency, as well as image resolution. To address this, we present Token-Shuffle, a novel yet simple method that reduces the number of image tokens in Transformer. Our key insight is the dimensional redundancy of visual vocabularies in Multimodal Large Language Models (MLLMs), where low-dimensional visual codes from visual encoder are directly mapped to high-dimensional language vocabularies. Leveraging this, we consider two key operations: token-shuffle, which merges spatially local tokens along channel dimension to decrease the input token number, and token-unshuffle, which untangles the inferred tokens after Transformer blocks to restore the spatial arrangement for output. Jointly training with textual prompts, our strategy requires no additional pretrained text-encoder and enables MLLMs to support extremely high-resolution image synthesis in a unified next-token prediction way while maintaining efficient training and inference. For the first time, we push the boundary of AR text-to-image generation to a resolution of 2048x2048 with gratifying generation performance. In GenAI-benchmark, our 2.7B model achieves 0.77 overall score on hard prompts, outperforming AR models LlamaGen by 0.18 and diffusion models LDM by 0.15. Exhaustive large-scale human evaluations also demonstrate our prominent image generation ability in terms of text-alignment, visual flaw, and visual appearance. We hope that Token-Shuffle can serve as a foundational design for efficient high-resolution image generation within MLLMs.
Decoding-Time Language Model Alignment with Multiple Objectives
Jun 27, 2024



Aligning language models (LMs) to human preferences has emerged as a critical pursuit, enabling these models to better serve diverse user needs. Existing methods primarily focus on optimizing LMs for a single reward function, limiting their adaptability to varied objectives. Here, we propose $\textbf{multi-objective decoding (MOD)}$, a decoding-time algorithm that outputs the next token from a linear combination of predictions of all base models, for any given weightings over different objectives. We exploit a common form among a family of $f$-divergence regularized alignment approaches (such as PPO, DPO, and their variants) to identify a closed-form solution by Legendre transform, and derive an efficient decoding strategy. Theoretically, we show why existing approaches can be sub-optimal even in natural settings and obtain optimality guarantees for our method. Empirical results demonstrate the effectiveness of the algorithm. For example, compared to a parameter-merging baseline, MOD achieves 12.8% overall reward improvement when equally optimizing towards $3$ objectives. Moreover, we experiment with MOD on combining three fully-finetuned LLMs of different model sizes, each aimed at different objectives such as safety, coding, and general user preference. Unlike traditional methods that require careful curation of a mixture of datasets to achieve comprehensive improvement, we can quickly experiment with preference weightings using MOD to find the best combination of models. Our best combination reduces toxicity on Toxigen to nearly 0% and achieves 7.9--33.3% improvement across other three metrics ($\textit{i.e.}$, Codex@1, GSM-COT, BBH-COT).