 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysEditWorld: A Large-Scale Dataset Toward Physics-Editable World Models
Jun 25, 2026Recent game world models can synthesize visually plausible, action-conditioned rollouts. However, their interaction behaviors often remain limited to exploratory or wandering trajectories, and physical dynamics are typically learned as implicit correlations from data rather than as controllable variables. This limitation hinders their applicability to authored game environments, where physical rules are deliberately designed and require explicit manipulation. We introduce PhysEditWorld, a multimodal dataset with physical parameters, with a primary focus on gravity in this initial version. At its core, PhysEditWorld is built upon a replay paradigm implemented with a UE5 replay-and-rendering pipeline. Each scenario records a normalized action trace and replays the same initial state, character controller, action sequence, and camera policy under multiple gravity configurations, enabling controlled and attributable physical variation. PhysEditWorld contains 12 cinematic UE5 scenes, over 100 hours of gameplay interactions, and more than 60 million rendered rollout frames. Each sample provides synchronized multimodal signals, including RGB, depth, normals, audio, action traces, camera trajectory, engine states, semantic annotations, and explicit gravity labels. We further conduct initial utility studies on both generative video models and world understanding models, demonstrating that PhysEditWorld enables improved gravity-faithful dynamics modeling, enhances consistency under physical edits, and provides a scalable foundation for controllable world modeling research.
Orchestra-o1: Omnimodal Agent Orchestration
Jun 10, 2026The recent success of agent swarms has shifted the paradigm of large language model (LLM)-based agents from single-agent workflows to multi-agent systems, highlighting the importance of agent orchestration for task decomposition and collaboration. However, existing orchestration frameworks are limited to a narrow set of modalities and struggle to generalize to more complex settings where heterogeneous modalities coexist and interact. This limitation becomes particularly pronounced in omnimodal scenarios, where tasks require the unified understanding and coordination of diverse inputs such as text, image, audio, and video. In this work, we propose Orchestra-o1, an omnimodal agent orchestration framework designed to support efficient agent collaboration across multiple modalities. Orchestra-o1 introduces a unified orchestration mechanism that enables modality-aware task decomposition, online sub-agent specialization, and parallel sub-task execution. This scalable design allows agent systems to effectively tackle complex real-world tasks involving heterogeneous information sources, surpassing the second-best approach by 10.3% accuracy on the OmniGAIA benchmark. Furthermore, we introduce decision-aligned group relative policy optimization (DA-GRPO), an efficient agentic reinforcement learning approach for training Orchestra-o1-8B, which also achieves state-of-the-art performance against all existing open-source omnimodal agents.
OmniGameArena: A Unified UE5 Benchmark for VLM Game Agents with Improvement Dynamics
Jun 08, 2026Vision-language model (VLM) agents are increasingly deployed in interactive game environments. Yet game benchmarks for VLM agents typically report a single first-attempt score per (agent, game) pair, focus on single-agent Solo play, and lack unified protocols for evaluating heterogeneous agent classes (commercial VLMs, open-weight VLMs, and specialized game policies) on the same footing. We address these gaps with OmniGameArena, a real-time benchmark of twelve newly built Unreal Engine 5 games spanning Solo (7), PvP (3), and Coop (2) with unified action interfaces, and the Improvement Dynamics Curve (IDC), an agentic-reflection harness in which a tool-using reflector LLM autonomously refines a bounded skill prompt across multiple rounds. Beyond cold-start leaderboard scores, IDC exposes two additional observables for each (agent, game) pair: how the score evolves across reflection rounds, and how the learned skill behaves on held-out task variants. We report these observables for twelve VLM agents on the cold-start leaderboard and four top agents under IDC.
Struct-Searcher: Agentic Structural Thinking Advances Multimodal Deep Information Seeking
Jun 05, 2026Deep research agents have attracted increasing attention for their ability to collect large-scale online information to acquire target knowledge, with recent efforts shifting from purely text-based information seeking to multimodal settings. However, existing agentic workflows are largely aligned with evidence accumulation models, which linearly aggregate evidence and lack principled mechanisms for handling contradictory information across heterogeneous modalities. Towards this end, we propose Struct-Searcher, a structural agentic workflow grounded in belief revision theory that explicitly maintains an evolving multimodal structural graph throughout the reasoning process, enabling effective conflict-aware multimodal deep information seeking. Extensive experiments across multiple benchmark datasets and backbone models demonstrate that Struct-Searcher is (1) plug-and-play and model-agnostic, yielding an average relative accuracy improvement of 17.2% on BrowseComp-VL across five different backbones. (2) top-performing, consistently outperforming state-of-the-art vision-language models (VLMs) and deep research agents, with relative accuracy improvements of 3.7% on MM-BrowseComp, 1.5% on HLE-VL, and 0.7% on BrowseComp-VL over the second-best competing approach.
Policy and World Modeling Co-Training for Language Agents
Jun 01, 2026Reinforcement learning (RL) improves large language model (LLM) agents by teaching them which actions lead to high rewards, but provides little supervision on what those actions do to the environment. World modeling (WM) can fill this gap, yet existing approaches often require separate simulators, extra training stages, or additional inference-time computation. We observe that on-policy RL rollouts already contain the needed signal: each transition pairs an action with its resulting next observation. Based on this observation, we propose PaW, a Policy and World modeling co-training framework that adds auxiliary WM supervision to the same policy during RL, without changing the inference paradigm. To make auxiliary WM supervision informative and stable, PaW introduces three components: action-entropy-based WM data selection, noise-tolerant WM loss, and reward-adaptive loss balancing. Experiments on three agentic task benchmarks show consistent improvements over strong RL baselines across models and RL algorithms. These results suggest that standard RL rollouts are a practical source of WM supervision for language-agent training.
On-Policy Adversarial Flow Distillation for Autoregressive Video Generation
May 25, 2026Autoregressive video generators are attractive for streaming, long-horizon, and interactive applications, but distilling strong black-box teachers into causal students remains difficult. The student must learn under its own rollout distribution, whereas practical teachers may expose only prompt-conditioned completed videos and may differ in architecture, capacity, temporal design, and sampling schedule. This interface makes supervised fine-tuning off-policy, score-based distillation inapplicable, and direct adversarial imitation too sparse for denoising-time credit assignment. We propose Adversarial Flow Distillation (AFD), an on-policy framework for heterogeneous black-box video distillation. AFD queries the teacher and rolls out the current student on the same prompts, trains a prompt-paired Bradley-Terry discriminator to estimate clean-sample teacher-student discrepancy, and converts the resulting on-policy advantage into forward-process flow-matching updates on the student's own noised states. Thus, AFD provides dense velocity-field supervision while requiring no teacher scores, latents, denoising trajectories, step alignment, or reverse-chain reinforcement learning. Experiments across two causal AR student families show that AFD consistently improves motion- and physics-sensitive generation while preserving general video quality, and ablations validate the importance of adaptive on-policy feedback and forward-process credit assignment. The method requires only clean teacher videos and student rollouts, providing a practical route for distilling proprietary or heterogeneous video generators into efficient autoregressive students.
SAP: Segment Any 4K Panorama
Mar 13, 2026Promptable instance segmentation is widely adopted in embodied and AR systems, yet the performance of foundation models trained on perspective imagery often degrades on 360° panoramas. In this paper, we introduce Segment Any 4K Panorama (SAP), a foundation model for 4K high-resolution panoramic instance-level segmentation. We reformulate panoramic segmentation as fixed-trajectory perspective video segmentation, decomposing a panorama into overlapping perspective patches sampled along a continuous spherical traversal. This memory-aligned reformulation preserves native 4K resolution while restoring the smooth viewpoint transitions required for stable cross-view propagation. To enable large-scale supervision, we synthesize 183,440 4K-resolution panoramic images with instance segmentation labels using the InfiniGen engine. Trained under this trajectory-aligned paradigm, SAP generalizes effectively to real-world 360° images, achieving +17.2 zero-shot mIoU gain over vanilla SAM2 of different sizes on real-world 4K panorama benchmark.
CoSMo3D: Open-World Promptable 3D Semantic Part Segmentation through LLM-Guided Canonical Spatial Modeling
Mar 01, 2026Open-world promptable 3D semantic segmentation remains brittle as semantics are inferred in the input sensor coordinates. Yet, humans, in contrast, interpret parts via functional roles in a canonical space -- wings extend laterally, handles protrude to the side, and legs support from below. Psychophysical evidence shows that we mentally rotate objects into canonical frames to reveal these roles. To fill this gap, we propose \methodName{}, which attains canonical space perception by inducing a latent canonical reference frame learned directly from data. By construction, we create a unified canonical dataset through LLM-guided intra- and cross-category alignment, exposing canonical spatial regularities across 200 categories. By induction, we realize canonicality inside the model through a dual-branch architecture with canonical map anchoring and canonical box calibration, collapsing pose variation and symmetry into a stable canonical embedding. This shift from input pose space to canonical embedding yields far more stable and transferable part semantics. Experimental results show that \methodName{} establishes new state of the art in open-world promptable 3D segmentation.
AssetFormer: Modular 3D Assets Generation with Autoregressive Transformer
Feb 12, 2026The digital industry demands high-quality, diverse modular 3D assets, especially for user-generated content~(UGC). In this work, we introduce AssetFormer, an autoregressive Transformer-based model designed to generate modular 3D assets from textual descriptions. Our pilot study leverages real-world modular assets collected from online platforms. AssetFormer tackles the challenge of creating assets composed of primitives that adhere to constrained design parameters for various applications. By innovatively adapting module sequencing and decoding techniques inspired by language models, our approach enhances asset generation quality through autoregressive modeling. Initial results indicate the effectiveness of AssetFormer in streamlining asset creation for professional development and UGC scenarios. This work presents a flexible framework extendable to various types of modular 3D assets, contributing to the broader field of 3D content generation. The code is available at https://github.com/Advocate99/AssetFormer.
StyleAR: Customizing Multimodal Autoregressive Model for Style-Aligned Text-to-Image Generation
May 26, 2025
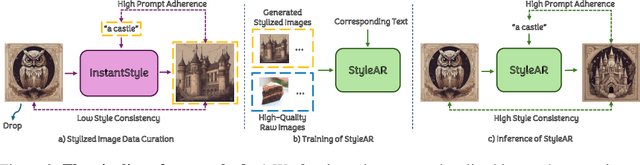

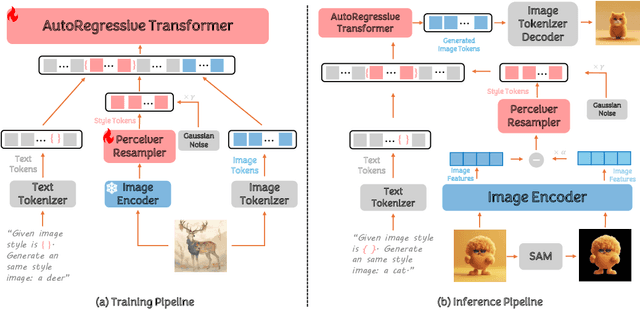
In the current research landscape, multimodal autoregressive (AR) models have shown exceptional capabilities across various domains, including visual understanding and generation. However, complex tasks such as style-aligned text-to-image generation present significant challenges, particularly in data acquisition. In analogy to instruction-following tuning for image editing of AR models, style-aligned generation requires a reference style image and prompt, resulting in a text-image-to-image triplet where the output shares the style and semantics of the input. However, acquiring large volumes of such triplet data with specific styles is considerably more challenging than obtaining conventional text-to-image data used for training generative models. To address this issue, we propose StyleAR, an innovative approach that combines a specially designed data curation method with our proposed AR models to effectively utilize text-to-image binary data for style-aligned text-to-image generation. Our method synthesizes target stylized data using a reference style image and prompt, but only incorporates the target stylized image as the image modality to create high-quality binary data. To facilitate binary data training, we introduce a CLIP image encoder with a perceiver resampler that translates the image input into style tokens aligned with multimodal tokens in AR models and implement a style-enhanced token technique to prevent content leakage which is a common issue in previous work. Furthermore, we mix raw images drawn from large-scale text-image datasets with stylized images to enhance StyleAR's ability to extract richer stylistic features and ensure style consistency. Extensive qualitative and quantitative experiments demonstrate our superior performance.