 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding informative materials datasets beyond targeted objectives
May 06, 2026Materials science data collection can be expensive, making the reuse and long-term utility of datasets critical important for future discovery campaigns. In practice, researchers prioritize a subset of properties due to research interests. However, ignoring a subset of outcomes in data collection campaigns potentially generate datasets poorly suited for future learning tasks. Here, we present a framework for dataset construction that maximizes informativeness for target properties of interest while preserving performance on untargeted ones. Our approach uses diversity-aware selection to ensure broad coverage of the materials space. In noisy experimental dataset construction, we find that without our diversity-aware framework, prediction performance on untargeted properties can degrade by up to 40% relative to random sampling, whereas applying our framework yields improvements of up to 10% . For targeted properties, performance can degrade with respect to random sampling by up to 12.5% without diversity, while our framework achieves gains of up to 25%. Incorporating diversity into dataset construction not only preserves informativeness for the targeted properties, but also improves materials coverage for potential future objectives. As a result, the constructed datasets remain broadly informative across considered and unconsidered outcomes, ensuring unbiased quality entries and mitigating cold-start limitations in subsequent modeling and discovery campaigns.
From Knowledge to Action: Outcomes of the 2025 Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry
May 04, 2026Large language models (LLMs) are rapidly changing how researchers in materials science and chemistry discover, organize, and act on scientific knowledge. This paper analyzes a broad set of community-developed LLM applications in an effort to identify emerging patterns in how these systems can be used across the scientific research lifecycle. We organize the projects into two complementary categories: Knowledge Infrastructure, systems that structure, retrieve, synthesize, and validate scientific information; and Action Systems, systems that execute, coordinate, or automate scientific work across computational and experimental environments. The submissions reveal a shift from single-purpose LLM tools toward integrated, multi-agent workflows that combine retrieval, reasoning, tool use, and domain-specific validation. Prominent themes include retrieval-augmented generation as grounding infrastructure, persistent structured knowledge representations, multimodal and multilingual scientific inputs, and early progress toward laboratory-integrated closed-loop systems. Together, these results suggest that LLMs are evolving from general-purpose assistants into composable infrastructure for scientific reasoning and action. This work provides a community snapshot of that transition and a practical taxonomy for understanding emerging LLM-enabled workflows in materials science and chemistry.
SAP: Segment Any 4K Panorama
Mar 13, 2026Promptable instance segmentation is widely adopted in embodied and AR systems, yet the performance of foundation models trained on perspective imagery often degrades on 360° panoramas. In this paper, we introduce Segment Any 4K Panorama (SAP), a foundation model for 4K high-resolution panoramic instance-level segmentation. We reformulate panoramic segmentation as fixed-trajectory perspective video segmentation, decomposing a panorama into overlapping perspective patches sampled along a continuous spherical traversal. This memory-aligned reformulation preserves native 4K resolution while restoring the smooth viewpoint transitions required for stable cross-view propagation. To enable large-scale supervision, we synthesize 183,440 4K-resolution panoramic images with instance segmentation labels using the InfiniGen engine. Trained under this trajectory-aligned paradigm, SAP generalizes effectively to real-world 360° images, achieving +17.2 zero-shot mIoU gain over vanilla SAM2 of different sizes on real-world 4K panorama benchmark.
CoSMo3D: Open-World Promptable 3D Semantic Part Segmentation through LLM-Guided Canonical Spatial Modeling
Mar 01, 2026Open-world promptable 3D semantic segmentation remains brittle as semantics are inferred in the input sensor coordinates. Yet, humans, in contrast, interpret parts via functional roles in a canonical space -- wings extend laterally, handles protrude to the side, and legs support from below. Psychophysical evidence shows that we mentally rotate objects into canonical frames to reveal these roles. To fill this gap, we propose \methodName{}, which attains canonical space perception by inducing a latent canonical reference frame learned directly from data. By construction, we create a unified canonical dataset through LLM-guided intra- and cross-category alignment, exposing canonical spatial regularities across 200 categories. By induction, we realize canonicality inside the model through a dual-branch architecture with canonical map anchoring and canonical box calibration, collapsing pose variation and symmetry into a stable canonical embedding. This shift from input pose space to canonical embedding yields far more stable and transferable part semantics. Experimental results show that \methodName{} establishes new state of the art in open-world promptable 3D segmentation.
Large Material Gaussian Model for Relightable 3D Generation
Sep 26, 2025
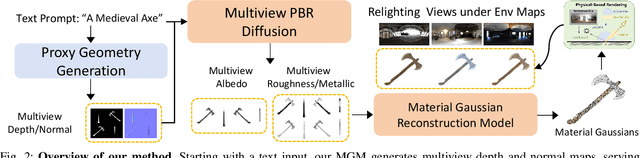
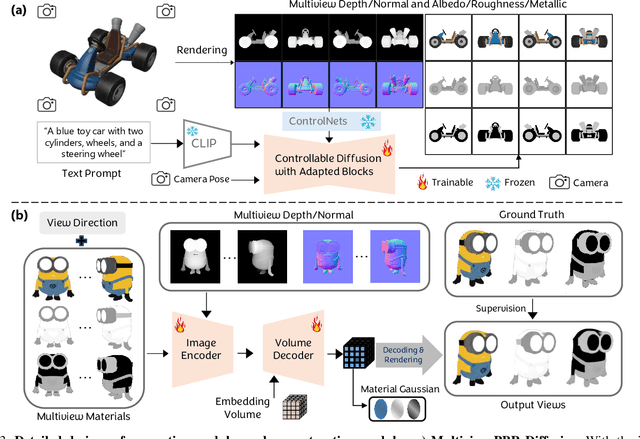

The increasing demand for 3D assets across various industries necessitates efficient and automated methods for 3D content creation. Leveraging 3D Gaussian Splatting, recent large reconstruction models (LRMs) have demonstrated the ability to efficiently achieve high-quality 3D rendering by integrating multiview diffusion for generation and scalable transformers for reconstruction. However, existing models fail to produce the material properties of assets, which is crucial for realistic rendering in diverse lighting environments. In this paper, we introduce the Large Material Gaussian Model (MGM), a novel framework designed to generate high-quality 3D content with Physically Based Rendering (PBR) materials, ie, albedo, roughness, and metallic properties, rather than merely producing RGB textures with uncontrolled light baking. Specifically, we first fine-tune a new multiview material diffusion model conditioned on input depth and normal maps. Utilizing the generated multiview PBR images, we explore a Gaussian material representation that not only aligns with 2D Gaussian Splatting but also models each channel of the PBR materials. The reconstructed point clouds can then be rendered to acquire PBR attributes, enabling dynamic relighting by applying various ambient light maps. Extensive experiments demonstrate that the materials produced by our method not only exhibit greater visual appeal compared to baseline methods but also enhance material modeling, thereby enabling practical downstream rendering applications.
UAV-Based Remote Sensing of Soil Moisture Across Diverse Land Covers: Validation and Bayesian Uncertainty Characterization
Jun 05, 2025High-resolution soil moisture (SM) observations are critical for agricultural monitoring, forestry management, and hazard prediction, yet current satellite passive microwave missions cannot directly provide retrievals at tens-of-meter spatial scales. Unmanned aerial vehicle (UAV) mounted microwave radiometry presents a promising alternative, but most evaluations to date have focused on agricultural settings, with limited exploration across other land covers and few efforts to quantify retrieval uncertainty. This study addresses both gaps by evaluating SM retrievals from a drone-based Portable L-band Radiometer (PoLRa) across shrubland, bare soil, and forest strips in Central Illinois, U.S., using a 10-day field campaign in 2024. Controlled UAV flights at altitudes of 10 m, 20 m, and 30 m were performed to generate brightness temperatures (TB) at spatial resolutions of 7 m, 14 m, and 21 m. SM retrievals were carried out using multiple tau-omega-based algorithms, including the single channel algorithm (SCA), dual channel algorithm (DCA), and multi-temporal dual channel algorithm (MTDCA). A Bayesian inference framework was then applied to provide probabilistic uncertainty characterization for both SM and vegetation optical depth (VOD). Results show that the gridded TB distributions consistently capture dry-wet gradients associated with vegetation density variations, and spatial correlations between polarized observations are largely maintained across scales. Validation against in situ measurements indicates that PoLRa derived SM retrievals from the SCAV and MTDCA algorithms achieve unbiased root-mean-square errors (ubRMSE) generally below 0.04 m3/m3 across different land covers. Bayesian posterior analyses confirm that reference SM values largely fall within the derived uncertainty intervals, with mean uncertainty ranges around 0.02 m3/m3 and 0.11 m3/m3 for SCA and DCA related retrievals.
DropletVideo: A Dataset and Approach to Explore Integral Spatio-Temporal Consistent Video Generation
Mar 08, 2025Spatio-temporal consistency is a critical research topic in video generation. A qualified generated video segment must ensure plot plausibility and coherence while maintaining visual consistency of objects and scenes across varying viewpoints. Prior research, especially in open-source projects, primarily focuses on either temporal or spatial consistency, or their basic combination, such as appending a description of a camera movement after a prompt without constraining the outcomes of this movement. However, camera movement may introduce new objects to the scene or eliminate existing ones, thereby overlaying and affecting the preceding narrative. Especially in videos with numerous camera movements, the interplay between multiple plots becomes increasingly complex. This paper introduces and examines integral spatio-temporal consistency, considering the synergy between plot progression and camera techniques, and the long-term impact of prior content on subsequent generation. Our research encompasses dataset construction through to the development of the model. Initially, we constructed a DropletVideo-10M dataset, which comprises 10 million videos featuring dynamic camera motion and object actions. Each video is annotated with an average caption of 206 words, detailing various camera movements and plot developments. Following this, we developed and trained the DropletVideo model, which excels in preserving spatio-temporal coherence during video generation. The DropletVideo dataset and model are accessible at https://dropletx.github.io.
ArcPro: Architectural Programs for Structured 3D Abstraction of Sparse Points
Mar 05, 2025We introduce ArcPro, a novel learning framework built on architectural programs to recover structured 3D abstractions from highly sparse and low-quality point clouds. Specifically, we design a domain-specific language (DSL) to hierarchically represent building structures as a program, which can be efficiently converted into a mesh. We bridge feedforward and inverse procedural modeling by using a feedforward process for training data synthesis, allowing the network to make reverse predictions. We train an encoder-decoder on the points-program pairs to establish a mapping from unstructured point clouds to architectural programs, where a 3D convolutional encoder extracts point cloud features and a transformer decoder autoregressively predicts the programs in a tokenized form. Inference by our method is highly efficient and produces plausible and faithful 3D abstractions. Comprehensive experiments demonstrate that ArcPro outperforms both traditional architectural proxy reconstruction and learning-based abstraction methods. We further explore its potential to work with multi-view image and natural language inputs.
Sub-Meter Remote Sensing of Soil Moisture Using Portable L-band Microwave Radiometer
Sep 25, 2024Spaceborne microwave passive soil moisture products are known for their accuracy but are often limited by coarse spatial resolutions. This limits their ability to capture finer soil moisture gradients and hinders their applications. The Portable L band radiometer (PoLRa) offers soil moisture measurements from submeter to tens of meters depending on the altitude of measurement. Given that the assessments of soil moisture derived from this sensor are notably lacking, this study aims to evaluate the performance of submeter soil moisture retrieved from PoLRa mounted on poles at four different locations in central Illinois, USA. The evaluation focuses on the consistency of PoLRa measured brightness temperatures from different directions relative to the same area, and the accuracy of PoLRa derived soil moisture. As PoLRa shares many aspects of the L band radiometer onboard the NASA Soil Moisture Active Passive (SMAP) mission, two SMAP operational algorithms and the conventional dual channel algorithm were applied to calculate soil moisture from the measured brightness temperatures. The vertically polarized brightness temperatures from the PoLRa are typically more stable than their horizontally polarized counterparts. In each test period, the standard deviations of observed dual polarization brightness temperatures are generally less than 5 K. By comparing PoLRa based soil moisture retrievals against the moisture values obtained by handheld time domain reflectometry, the unbiased root mean square error and the Pearson correlation coefficient are mostly below 0.04 and above 0.75, confirming the high accuracy of PoLRa derived soil moisture retrievals and the feasibility of utilizing SMAP algorithms for PoLRa data. These findings highlight the significant potential of ground or drone based PoLRa measurements as a standalone reference for future spaceborne L band sensors.
DreamMat: High-quality PBR Material Generation with Geometry- and Light-aware Diffusion Models
May 27, 20242D diffusion model, which often contains unwanted baked-in shading effects and results in unrealistic rendering effects in the downstream applications. Generating Physically Based Rendering (PBR) materials instead of just RGB textures would be a promising solution. However, directly distilling the PBR material parameters from 2D diffusion models still suffers from incorrect material decomposition, such as baked-in shading effects in albedo. We introduce DreamMat, an innovative approach to resolve the aforementioned problem, to generate high-quality PBR materials from text descriptions. We find out that the main reason for the incorrect material distillation is that large-scale 2D diffusion models are only trained to generate final shading colors, resulting in insufficient constraints on material decomposition during distillation. To tackle this problem, we first finetune a new light-aware 2D diffusion model to condition on a given lighting environment and generate the shading results on this specific lighting condition. Then, by applying the same environment lights in the material distillation, DreamMat can generate high-quality PBR materials that are not only consistent with the given geometry but also free from any baked-in shading effects in albedo. Extensive experiments demonstrate that the materials produced through our methods exhibit greater visual appeal to users and achieve significantly superior rendering quality compared to baseline methods, which are preferable for downstream tasks such as game and film production.