 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyleAR: Customizing Multimodal Autoregressive Model for Style-Aligned Text-to-Image Generation
Paper and Code

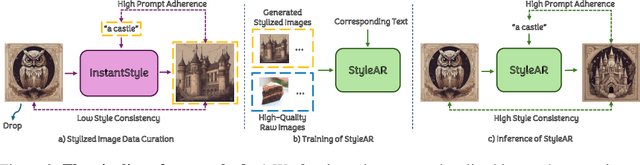

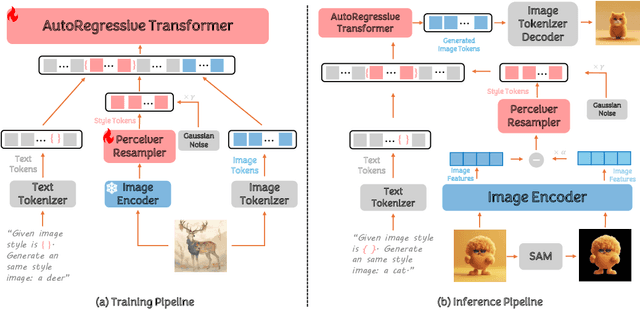
In the current research landscape, multimodal autoregressive (AR) models have shown exceptional capabilities across various domains, including visual understanding and generation. However, complex tasks such as style-aligned text-to-image generation present significant challenges, particularly in data acquisition. In analogy to instruction-following tuning for image editing of AR models, style-aligned generation requires a reference style image and prompt, resulting in a text-image-to-image triplet where the output shares the style and semantics of the input. However, acquiring large volumes of such triplet data with specific styles is considerably more challenging than obtaining conventional text-to-image data used for training generative models. To address this issue, we propose StyleAR, an innovative approach that combines a specially designed data curation method with our proposed AR models to effectively utilize text-to-image binary data for style-aligned text-to-image generation. Our method synthesizes target stylized data using a reference style image and prompt, but only incorporates the target stylized image as the image modality to create high-quality binary data. To facilitate binary data training, we introduce a CLIP image encoder with a perceiver resampler that translates the image input into style tokens aligned with multimodal tokens in AR models and implement a style-enhanced token technique to prevent content leakage which is a common issue in previous work. Furthermore, we mix raw images drawn from large-scale text-image datasets with stylized images to enhance StyleAR's ability to extract richer stylistic features and ensure style consistency. Extensive qualitative and quantitative experiments demonstrate our superior performance.