 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteract3D: Compositional 3D Generation of Interactive Objects
Mar 17, 2026Recent breakthroughs in 3D generation have enabled the synthesis of high-fidelity individual assets. However, generating 3D compositional objects from single images--particularly under occlusions--remains challenging. Existing methods often degrade geometric details in hidden regions and fail to preserve the underlying object-object spatial relationships (OOR). We present a novel framework Interact3D designed to generate physically plausible interacting 3D compositional objects. Our approach first leverages advanced generative priors to curate high-quality individual assets with a unified 3D guidance scene. To physically compose these assets, we then introduce a robust two-stage composition pipeline. Based on the 3D guidance scene, the primary object is anchored through precise global-to-local geometric alignment (registration), while subsequent geometries are integrated using a differentiable Signed Distance Field (SDF)-based optimization that explicitly penalizes geometry intersections. To reduce challenging collisions, we further deploy a closed-loop, agentic refinement strategy. A Vision-Language Model (VLM) autonomously analyzes multi-view renderings of the composed scene, formulates targeted corrective prompts, and guides an image editing module to iteratively self-correct the generation pipeline. Extensive experiments demonstrate that Interact3D successfully produces promising collsion-aware compositions with improved geometric fidelity and consistent spatial relationships.
SAP: Segment Any 4K Panorama
Mar 13, 2026Promptable instance segmentation is widely adopted in embodied and AR systems, yet the performance of foundation models trained on perspective imagery often degrades on 360° panoramas. In this paper, we introduce Segment Any 4K Panorama (SAP), a foundation model for 4K high-resolution panoramic instance-level segmentation. We reformulate panoramic segmentation as fixed-trajectory perspective video segmentation, decomposing a panorama into overlapping perspective patches sampled along a continuous spherical traversal. This memory-aligned reformulation preserves native 4K resolution while restoring the smooth viewpoint transitions required for stable cross-view propagation. To enable large-scale supervision, we synthesize 183,440 4K-resolution panoramic images with instance segmentation labels using the InfiniGen engine. Trained under this trajectory-aligned paradigm, SAP generalizes effectively to real-world 360° images, achieving +17.2 zero-shot mIoU gain over vanilla SAM2 of different sizes on real-world 4K panorama benchmark.
CoSMo3D: Open-World Promptable 3D Semantic Part Segmentation through LLM-Guided Canonical Spatial Modeling
Mar 01, 2026Open-world promptable 3D semantic segmentation remains brittle as semantics are inferred in the input sensor coordinates. Yet, humans, in contrast, interpret parts via functional roles in a canonical space -- wings extend laterally, handles protrude to the side, and legs support from below. Psychophysical evidence shows that we mentally rotate objects into canonical frames to reveal these roles. To fill this gap, we propose \methodName{}, which attains canonical space perception by inducing a latent canonical reference frame learned directly from data. By construction, we create a unified canonical dataset through LLM-guided intra- and cross-category alignment, exposing canonical spatial regularities across 200 categories. By induction, we realize canonicality inside the model through a dual-branch architecture with canonical map anchoring and canonical box calibration, collapsing pose variation and symmetry into a stable canonical embedding. This shift from input pose space to canonical embedding yields far more stable and transferable part semantics. Experimental results show that \methodName{} establishes new state of the art in open-world promptable 3D segmentation.
Look, Cast and Mold: Learning 3D Shape Manifold from Single-view Synthetic Data
Mar 18, 2021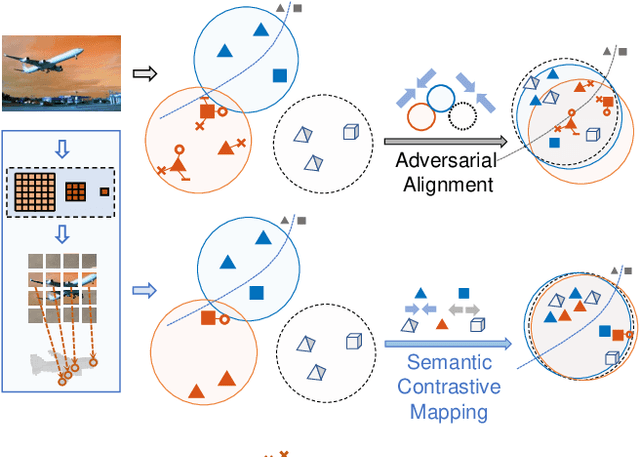
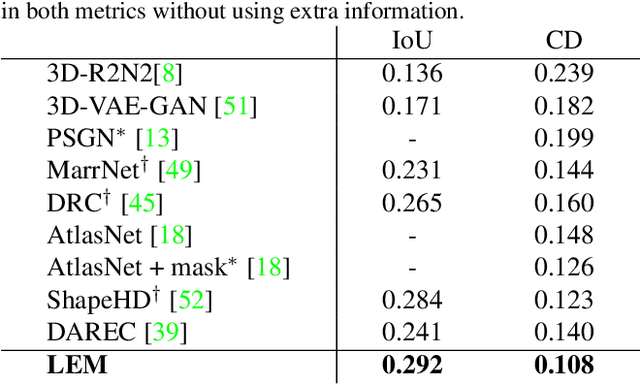
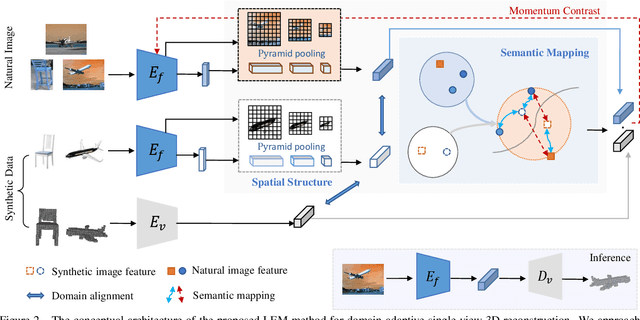
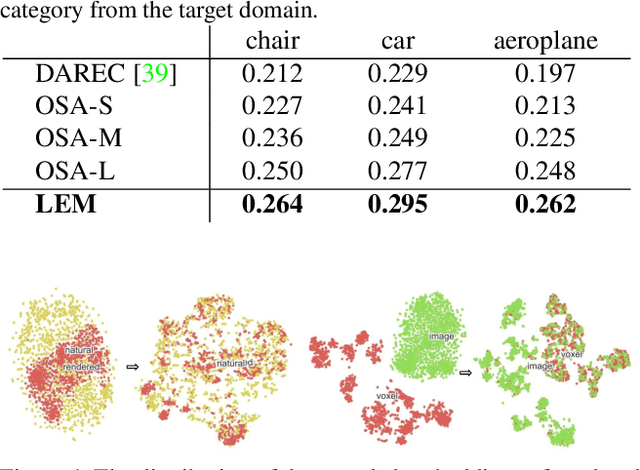
Inferring the stereo structure of objects in the real world is a challenging yet practical task. To equip deep models with this ability usually requires abundant 3D supervision which is hard to acquire. It is promising that we can simply benefit from synthetic data, where pairwise ground-truth is easy to access. Nevertheless, the domain gaps are nontrivial considering the variant texture, shape and context. To overcome these difficulties, we propose a Visio-Perceptual Adaptive Network for single-view 3D reconstruction, dubbed VPAN. To generalize the model towards a real scenario, we propose to fulfill several aspects: (1) Look: visually incorporate spatial structure from the single view to enhance the expressiveness of representation; (2) Cast: perceptually align the 2D image features to the 3D shape priors with cross-modal semantic contrastive mapping; (3) Mold: reconstruct stereo-shape of target by transforming embeddings into the desired manifold. Extensive experiments on several benchmarks demonstrate the effectiveness and robustness of the proposed method in learning the 3D shape manifold from synthetic data via a single-view. The proposed method outperforms state-of-the-arts on Pix3D dataset with IoU 0.292 and CD 0.108, and reaches IoU 0.329 and CD 0.104 on Pascal 3D+.