 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssetFormer: Modular 3D Assets Generation with Autoregressive Transformer
Feb 12, 2026The digital industry demands high-quality, diverse modular 3D assets, especially for user-generated content~(UGC). In this work, we introduce AssetFormer, an autoregressive Transformer-based model designed to generate modular 3D assets from textual descriptions. Our pilot study leverages real-world modular assets collected from online platforms. AssetFormer tackles the challenge of creating assets composed of primitives that adhere to constrained design parameters for various applications. By innovatively adapting module sequencing and decoding techniques inspired by language models, our approach enhances asset generation quality through autoregressive modeling. Initial results indicate the effectiveness of AssetFormer in streamlining asset creation for professional development and UGC scenarios. This work presents a flexible framework extendable to various types of modular 3D assets, contributing to the broader field of 3D content generation. The code is available at https://github.com/Advocate99/AssetFormer.
VMNet: Voxel-Mesh Network for Geodesic-Aware 3D Semantic Segmentation
Jul 29, 2021
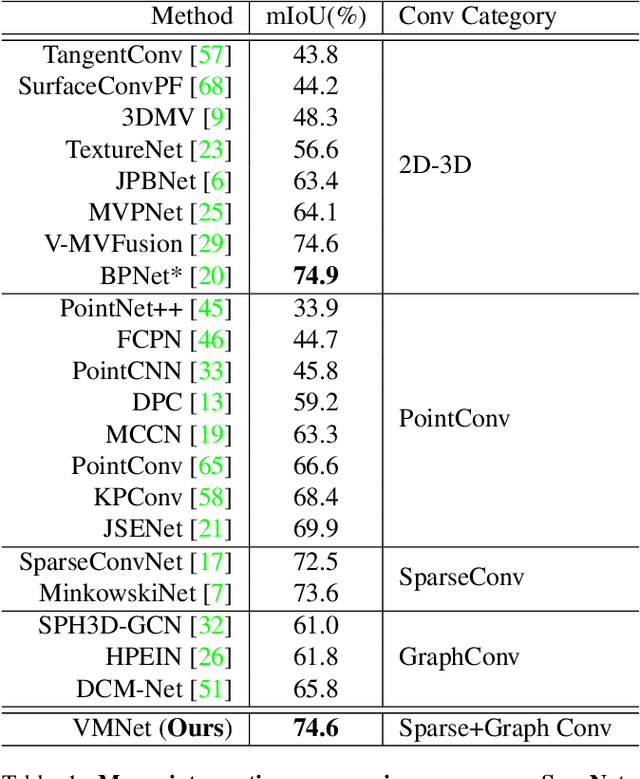
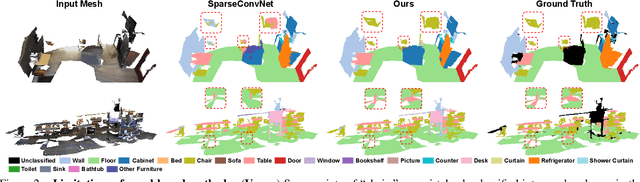

In recent years, sparse voxel-based methods have become the state-of-the-arts for 3D semantic segmentation of indoor scenes, thanks to the powerful 3D CNNs. Nevertheless, being oblivious to the underlying geometry, voxel-based methods suffer from ambiguous features on spatially close objects and struggle with handling complex and irregular geometries due to the lack of geodesic information. In view of this, we present Voxel-Mesh Network (VMNet), a novel 3D deep architecture that operates on the voxel and mesh representations leveraging both the Euclidean and geodesic information. Intuitively, the Euclidean information extracted from voxels can offer contextual cues representing interactions between nearby objects, while the geodesic information extracted from meshes can help separate objects that are spatially close but have disconnected surfaces. To incorporate such information from the two domains, we design an intra-domain attentive module for effective feature aggregation and an inter-domain attentive module for adaptive feature fusion. Experimental results validate the effectiveness of VMNet: specifically, on the challenging ScanNet dataset for large-scale segmentation of indoor scenes, it outperforms the state-of-the-art SparseConvNet and MinkowskiNet (74.6% vs 72.5% and 73.6% in mIoU) with a simpler network structure (17M vs 30M and 38M parameters). Code release: https://github.com/hzykent/VMNet