 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Walk in the Real World with Minimal Human Effort
Feb 27, 2020

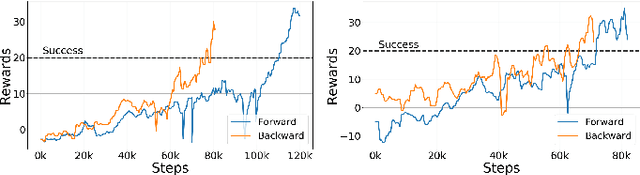
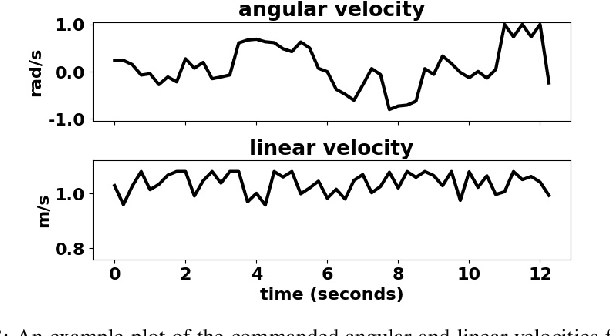
Reliable and stable locomotion has been one of the most fundamental challenges for legged robots. Deep reinforcement learning (deep RL) has emerged as a promising method for developing such control policies autonomously. In this paper, we develop a system for learning legged locomotion policies with deep RL in the real world with minimal human effort. The key difficulties for on-robot learning systems are automatic data collection and safety. We overcome these two challenges by developing a multi-task learning procedure, an automatic reset controller, and a safety-constrained RL framework. We tested our system on the task of learning to walk on three different terrains: flat ground, a soft mattress, and a doormat with crevices. Our system can automatically and efficiently learn locomotion skills on a Minitaur robot with little human intervention.
Scalable Multi-Task Imitation Learning with Autonomous Improvement
Feb 25, 2020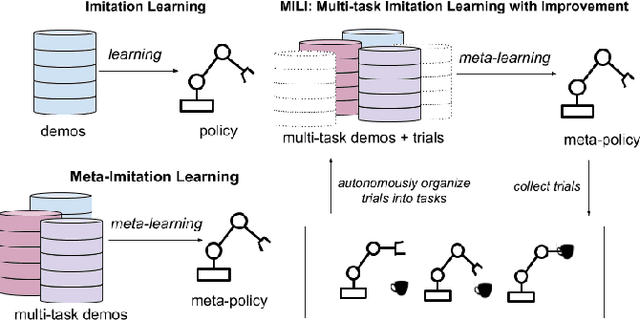
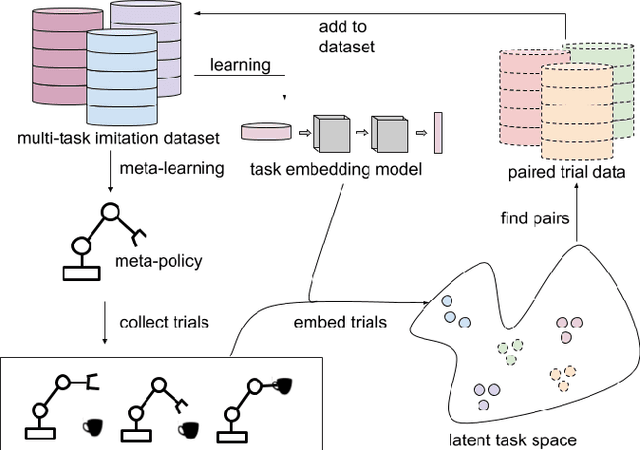
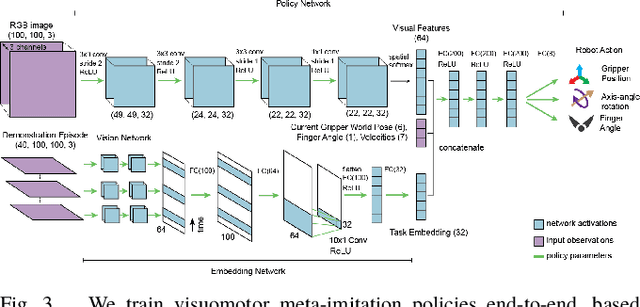

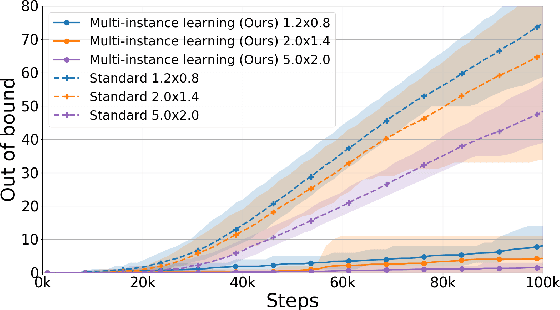
While robot learning has demonstrated promising results for enabling robots to automatically acquire new skills, a critical challenge in deploying learning-based systems is scale: acquiring enough data for the robot to effectively generalize broadly. Imitation learning, in particular, has remained a stable and powerful approach for robot learning, but critically relies on expert operators for data collection. In this work, we target this challenge, aiming to build an imitation learning system that can continuously improve through autonomous data collection, while simultaneously avoiding the explicit use of reinforcement learning, to maintain the stability, simplicity, and scalability of supervised imitation. To accomplish this, we cast the problem of imitation with autonomous improvement into a multi-task setting. We utilize the insight that, in a multi-task setting, a failed attempt at one task might represent a successful attempt at another task. This allows us to leverage the robot's own trials as demonstrations for tasks other than the one that the robot actually attempted. Using an initial dataset of multi-task demonstration data, the robot autonomously collects trials which are only sparsely labeled with a binary indication of whether the trial accomplished any useful task or not. We then embed the trials into a learned latent space of tasks, trained using only the initial demonstration dataset, to draw similarities between various trials, enabling the robot to achieve one-shot generalization to new tasks. In contrast to prior imitation learning approaches, our method can autonomously collect data with sparse supervision for continuous improvement, and in contrast to reinforcement learning algorithms, our method can effectively improve from sparse, task-agnostic reward signals.
Rewriting History with Inverse RL: Hindsight Inference for Policy Improvement
Feb 25, 2020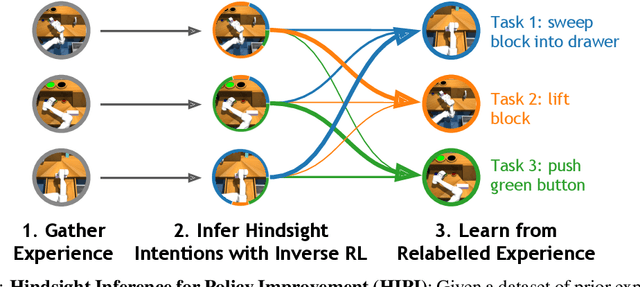
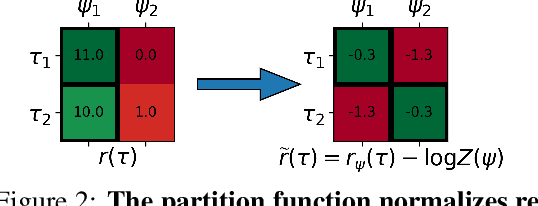

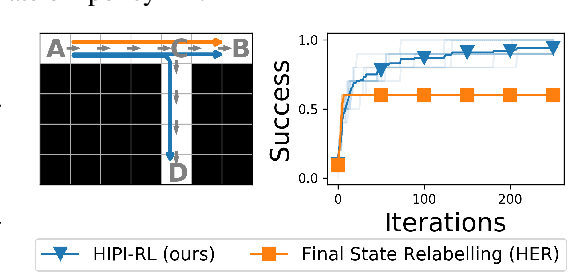
Multi-task reinforcement learning (RL) aims to simultaneously learn policies for solving many tasks. Several prior works have found that relabeling past experience with different reward functions can improve sample efficiency. Relabeling methods typically ask: if, in hindsight, we assume that our experience was optimal for some task, for what task was it optimal? In this paper, we show that hindsight relabeling is inverse RL, an observation that suggests that we can use inverse RL in tandem for RL algorithms to efficiently solve many tasks. We use this idea to generalize goal-relabeling techniques from prior work to arbitrary classes of tasks. Our experiments confirm that relabeling data using inverse RL accelerates learning in general multi-task settings, including goal-reaching, domains with discrete sets of rewards, and those with linear reward functions.
BADGR: An Autonomous Self-Supervised Learning-Based Navigation System
Feb 13, 2020


Mobile robot navigation is typically regarded as a geometric problem, in which the robot's objective is to perceive the geometry of the environment in order to plan collision-free paths towards a desired goal. However, a purely geometric view of the world can can be insufficient for many navigation problems. For example, a robot navigating based on geometry may avoid a field of tall grass because it believes it is untraversable, and will therefore fail to reach its desired goal. In this work, we investigate how to move beyond these purely geometric-based approaches using a method that learns about physical navigational affordances from experience. Our approach, which we call BADGR, is an end-to-end learning-based mobile robot navigation system that can be trained with self-supervised off-policy data gathered in real-world environments, without any simulation or human supervision. BADGR can navigate in real-world urban and off-road environments with geometrically distracting obstacles. It can also incorporate terrain preferences, generalize to novel environments, and continue to improve autonomously by gathering more data. Videos, code, and other supplemental material are available on our website https://sites.google.com/view/badgr
Gradient Surgery for Multi-Task Learning
Jan 19, 2020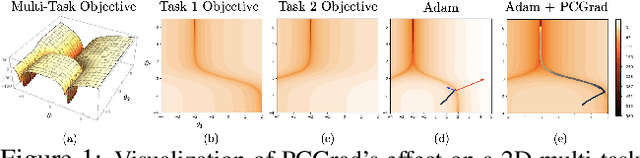
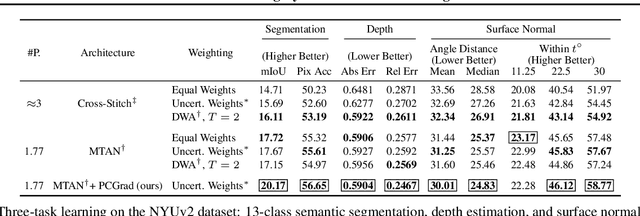
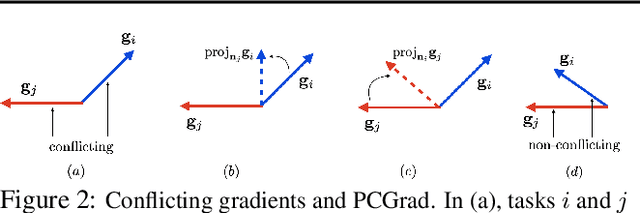
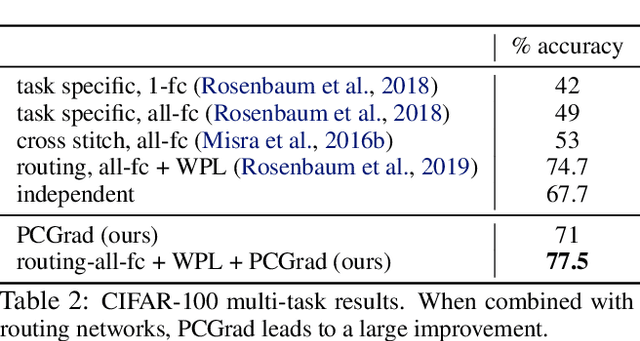
While deep learning and deep reinforcement learning (RL) systems have demonstrated impressive results in domains such as image classification, game playing, and robotic control, data efficiency remains a major challenge. Multi-task learning has emerged as a promising approach for sharing structure across multiple tasks to enable more efficient learning. However, the multi-task setting presents a number of optimization challenges, making it difficult to realize large efficiency gains compared to learning tasks independently. The reasons why multi-task learning is so challenging compared to single-task learning are not fully understood. In this work, we identify a set of three conditions of the multi-task optimization landscape that cause detrimental gradient interference, and develop a simple yet general approach for avoiding such interference between task gradients. We propose a form of gradient surgery that projects a task's gradient onto the normal plane of the gradient of any other task that has a conflicting gradient. On a series of challenging multi-task supervised and multi-task RL problems, this approach leads to substantial gains in efficiency and performance. Further, it is model-agnostic and can be combined with previously-proposed multi-task architectures for enhanced performance.
Reward-Conditioned Policies
Dec 31, 2019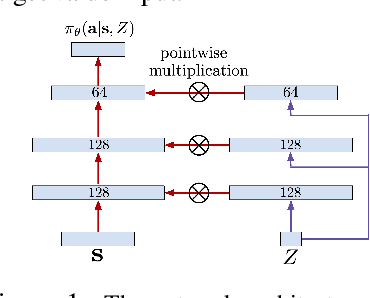
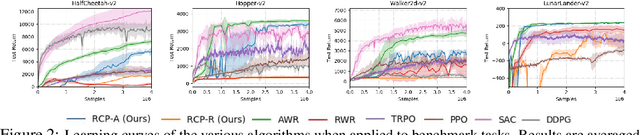

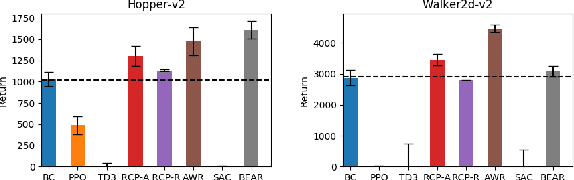
Reinforcement learning offers the promise of automating the acquisition of complex behavioral skills. However, compared to commonly used and well-understood supervised learning methods, reinforcement learning algorithms can be brittle, difficult to use and tune, and sensitive to seemingly innocuous implementation decisions. In contrast, imitation learning utilizes standard and well-understood supervised learning methods, but requires near-optimal expert data. Can we learn effective policies via supervised learning without demonstrations? The main idea that we explore in this work is that non-expert trajectories collected from sub-optimal policies can be viewed as optimal supervision, not for maximizing the reward, but for matching the reward of the given trajectory. By then conditioning the policy on the numerical value of the reward, we can obtain a policy that generalizes to larger returns. We show how such an approach can be derived as a principled method for policy search, discuss several variants, and compare the method experimentally to a variety of current reinforcement learning methods on standard benchmarks.
Model Inversion Networks for Model-Based Optimization
Dec 31, 2019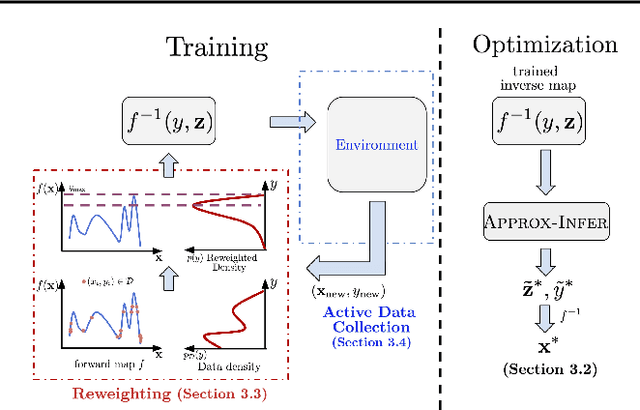


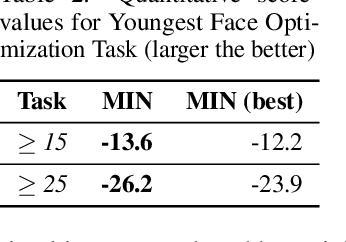
In this work, we aim to solve data-driven optimization problems, where the goal is to find an input that maximizes an unknown score function given access to a dataset of inputs with corresponding scores. When the inputs are high-dimensional and valid inputs constitute a small subset of this space (e.g., valid protein sequences or valid natural images), such model-based optimization problems become exceptionally difficult, since the optimizer must avoid out-of-distribution and invalid inputs. We propose to address such problem with model inversion networks (MINs), which learn an inverse mapping from scores to inputs. MINs can scale to high-dimensional input spaces and leverage offline logged data for both contextual and non-contextual optimization problems. MINs can also handle both purely offline data sources and active data collection. We evaluate MINs on tasks from the Bayesian optimization literature, high-dimensional model-based optimization problems over images and protein designs, and contextual bandit optimization from logged data.
Morphology-Agnostic Visual Robotic Control
Dec 31, 2019


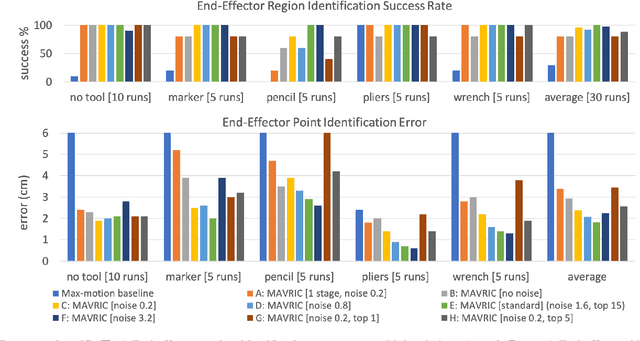
Existing approaches for visuomotor robotic control typically require characterizing the robot in advance by calibrating the camera or performing system identification. We propose MAVRIC, an approach that works with minimal prior knowledge of the robot's morphology, and requires only a camera view containing the robot and its environment and an unknown control interface. MAVRIC revolves around a mutual information-based method for self-recognition, which discovers visual "control points" on the robot body within a few seconds of exploratory interaction, and these control points in turn are then used for visual servoing. MAVRIC can control robots with imprecise actuation, no proprioceptive feedback, unknown morphologies including novel tools, unknown camera poses, and even unsteady handheld cameras. We demonstrate our method on visually-guided 3D point reaching, trajectory following, and robot-to-robot imitation.
Learning Predictive Models From Observation and Interaction
Dec 30, 2019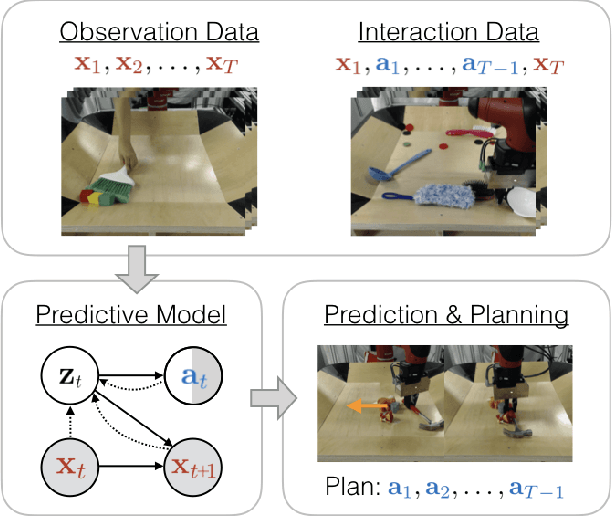

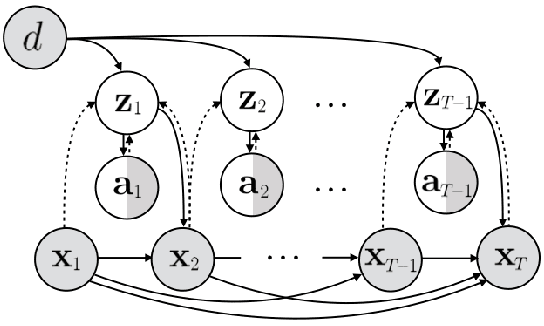

Learning predictive models from interaction with the world allows an agent, such as a robot, to learn about how the world works, and then use this learned model to plan coordinated sequences of actions to bring about desired outcomes. However, learning a model that captures the dynamics of complex skills represents a major challenge: if the agent needs a good model to perform these skills, it might never be able to collect the experience on its own that is required to learn these delicate and complex behaviors. Instead, we can imagine augmenting the training set with observational data of other agents, such as humans. Such data is likely more plentiful, but represents a different embodiment. For example, videos of humans might show a robot how to use a tool, but (i) are not annotated with suitable robot actions, and (ii) contain a systematic distributional shift due to the embodiment differences between humans and robots. We address the first challenge by formulating the corresponding graphical model and treating the action as an observed variable for the interaction data and an unobserved variable for the observation data, and the second challenge by using a domain-dependent prior. In addition to interaction data, our method is able to leverage videos of passive observations in a driving dataset and a dataset of robotic manipulation videos. A robotic planning agent equipped with our method can learn to use tools in a tabletop robotic manipulation setting by observing humans without ever seeing a robotic video of tool use.
Meta-Learning without Memorization
Dec 24, 2019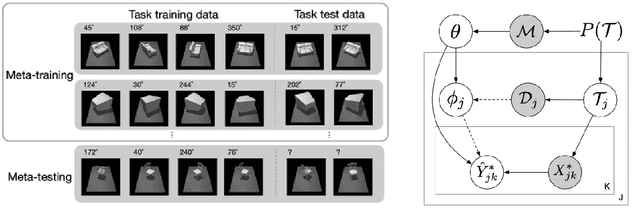

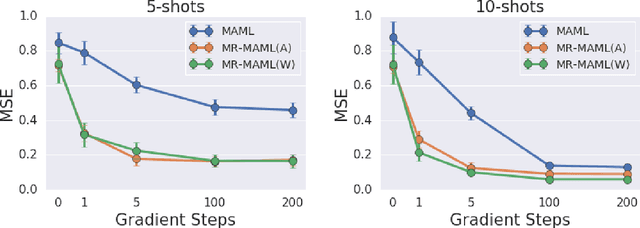

The ability to learn new concepts with small amounts of data is a critical aspect of intelligence that has proven challenging for deep learning methods. Meta-learning has emerged as a promising technique for leveraging data from previous tasks to enable efficient learning of new tasks. However, most meta-learning algorithms implicitly require that the meta-training tasks be mutually-exclusive, such that no single model can solve all of the tasks at once. For example, when creating tasks for few-shot image classification, prior work uses a per-task random assignment of image classes to N-way classification labels. If this is not done, the meta-learner can ignore the task training data and learn a single model that performs all of the meta-training tasks zero-shot, but does not adapt effectively to new image classes. This requirement means that the user must take great care in designing the tasks, for example by shuffling labels or removing task identifying information from the inputs. In some domains, this makes meta-learning entirely inapplicable. In this paper, we address this challenge by designing a meta-regularization objective using information theory that places precedence on data-driven adaptation. This causes the meta-learner to decide what must be learned from the task training data and what should be inferred from the task testing input. By doing so, our algorithm can successfully use data from non-mutually-exclusive tasks to efficiently adapt to novel tasks. We demonstrate its applicability to both contextual and gradient-based meta-learning algorithms, and apply it in practical settings where applying standard meta-learning has been difficult. Our approach substantially outperforms standard meta-learning algorithms in these settings.