 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Agile Soccer Skills for a Bipedal Robot with Deep Reinforcement Learning
Apr 26, 2023We investigate whether Deep Reinforcement Learning (Deep RL) is able to synthesize sophisticated and safe movement skills for a low-cost, miniature humanoid robot that can be composed into complex behavioral strategies in dynamic environments. We used Deep RL to train a humanoid robot with 20 actuated joints to play a simplified one-versus-one (1v1) soccer game. We first trained individual skills in isolation and then composed those skills end-to-end in a self-play setting. The resulting policy exhibits robust and dynamic movement skills such as rapid fall recovery, walking, turning, kicking and more; and transitions between them in a smooth, stable, and efficient manner - well beyond what is intuitively expected from the robot. The agents also developed a basic strategic understanding of the game, and learned, for instance, to anticipate ball movements and to block opponent shots. The full range of behaviors emerged from a small set of simple rewards. Our agents were trained in simulation and transferred to real robots zero-shot. We found that a combination of sufficiently high-frequency control, targeted dynamics randomization, and perturbations during training in simulation enabled good-quality transfer, despite significant unmodeled effects and variations across robot instances. Although the robots are inherently fragile, minor hardware modifications together with basic regularization of the behavior during training led the robots to learn safe and effective movements while still performing in a dynamic and agile way. Indeed, even though the agents were optimized for scoring, in experiments they walked 156% faster, took 63% less time to get up, and kicked 24% faster than a scripted baseline, while efficiently combining the skills to achieve the longer term objectives. Examples of the emergent behaviors and full 1v1 matches are available on the supplementary website.
Priors, Hierarchy, and Information Asymmetry for Skill Transfer in Reinforcement Learning
Jan 20, 2022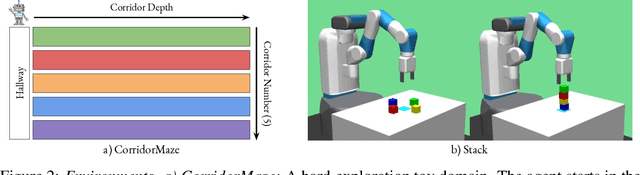
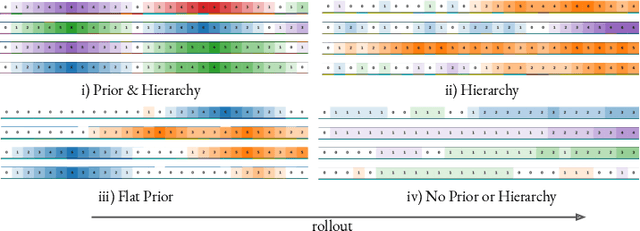
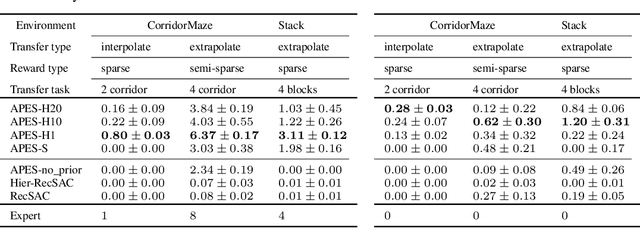
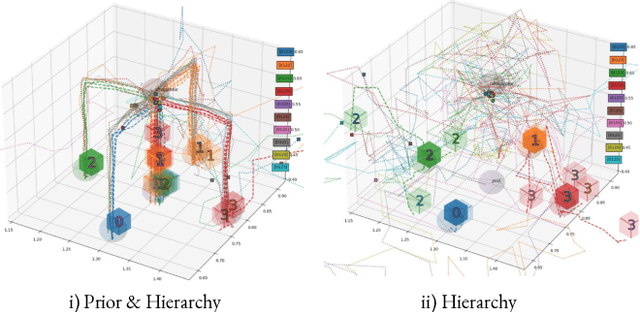
The ability to discover behaviours from past experience and transfer them to new tasks is a hallmark of intelligent agents acting sample-efficiently in the real world. Equipping embodied reinforcement learners with the same ability may be crucial for their successful deployment in robotics. While hierarchical and KL-regularized RL individually hold promise here, arguably a hybrid approach could combine their respective benefits. Key to these fields is the use of information asymmetry to bias which skills are learnt. While asymmetric choice has a large influence on transferability, prior works have explored a narrow range of asymmetries, primarily motivated by intuition. In this paper, we theoretically and empirically show the crucial trade-off, controlled by information asymmetry, between the expressivity and transferability of skills across sequential tasks. Given this insight, we provide a principled approach towards choosing asymmetry and apply our approach to a complex, robotic block stacking domain, unsolvable by baselines, demonstrating the effectiveness of hierarchical KL-regularized RL, coupled with correct asymmetric choice, for sample-efficient transfer learning.
Bayesian Bellman Operators
Jun 15, 2021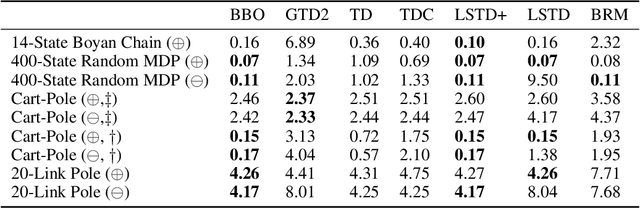
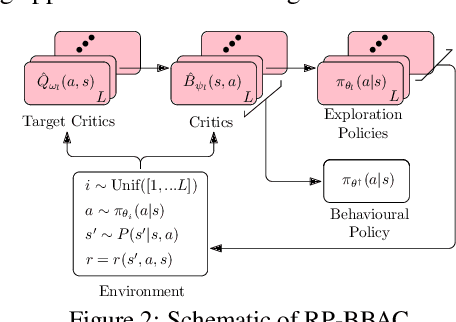
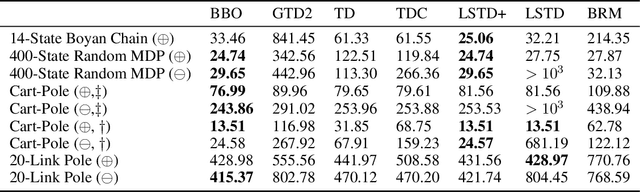
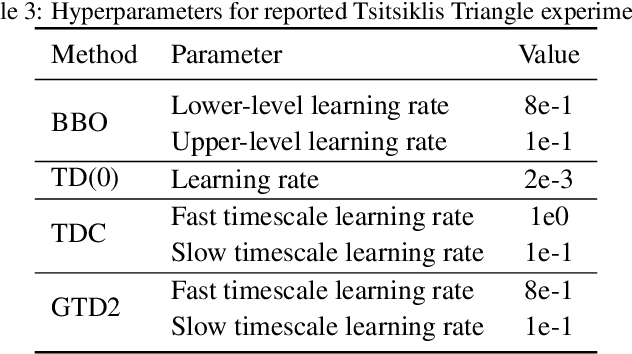
We introduce a novel perspective on Bayesian reinforcement learning (RL); whereas existing approaches infer a posterior over the transition distribution or Q-function, we characterise the uncertainty in the Bellman operator. Our Bayesian Bellman operator (BBO) framework is motivated by the insight that when bootstrapping is introduced, model-free approaches actually infer a posterior over Bellman operators, not value functions. In this paper, we use BBO to provide a rigorous theoretical analysis of model-free Bayesian RL to better understand its relationshipto established frequentist RL methodologies. We prove that Bayesian solutions are consistent with frequentist RL solutions, even when approximate inference isused, and derive conditions for which convergence properties hold. Empirically, we demonstrate that algorithms derived from the BBO framework have sophisticated deep exploration properties that enable them to solve continuous control tasks at which state-of-the-art regularised actor-critic algorithms fail catastrophically
Exploration in Approximate Hyper-State Space for Meta Reinforcement Learning
Oct 02, 2020
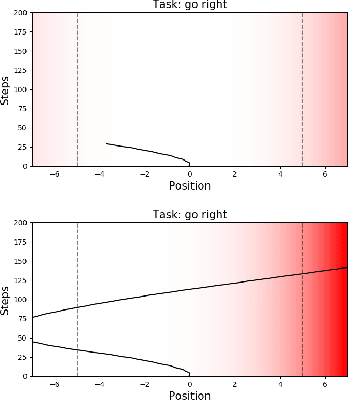

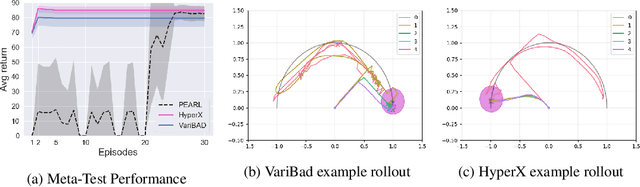
Meta-learning is a powerful tool for learning policies that can adapt efficiently when deployed in new tasks. If however the meta-training tasks have sparse rewards, the need for exploration during meta-training is exacerbated given that the agent has to explore and learn across many tasks. We show that current meta-learning methods can fail catastrophically in such environments. To address this problem, we propose HyperX, a novel method for meta-learning in sparse reward tasks. Using novel reward bonuses for meta-training, we incentivise the agent to explore in approximate hyper-state space, i.e., the joint state and approximate belief space, where the beliefs are over tasks. We show empirically that these bonuses allow an agent to successfully learn to solve sparse reward tasks where existing meta-learning methods fail.
The Ingredients of Real-World Robotic Reinforcement Learning
Apr 27, 2020
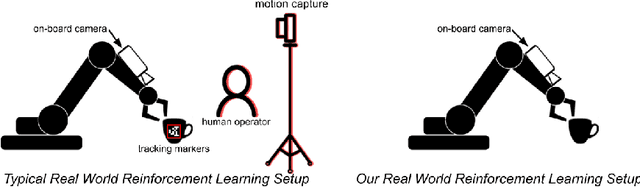
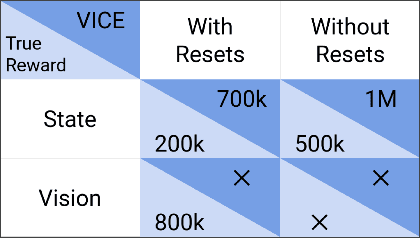
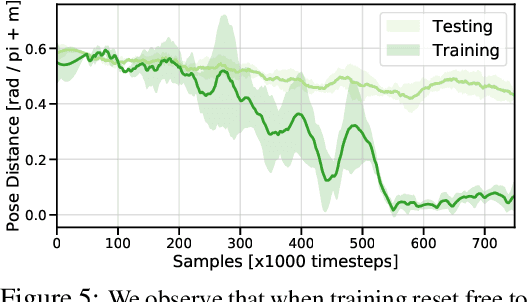
The success of reinforcement learning for real world robotics has been, in many cases limited to instrumented laboratory scenarios, often requiring arduous human effort and oversight to enable continuous learning. In this work, we discuss the elements that are needed for a robotic learning system that can continually and autonomously improve with data collected in the real world. We propose a particular instantiation of such a system, using dexterous manipulation as our case study. Subsequently, we investigate a number of challenges that come up when learning without instrumentation. In such settings, learning must be feasible without manually designed resets, using only on-board perception, and without hand-engineered reward functions. We propose simple and scalable solutions to these challenges, and then demonstrate the efficacy of our proposed system on a set of dexterous robotic manipulation tasks, providing an in-depth analysis of the challenges associated with this learning paradigm. We demonstrate that our complete system can learn without any human intervention, acquiring a variety of vision-based skills with a real-world three-fingered hand. Results and videos can be found at https://sites.google.com/view/realworld-rl/
ROBEL: Robotics Benchmarks for Learning with Low-Cost Robots
Sep 25, 2019
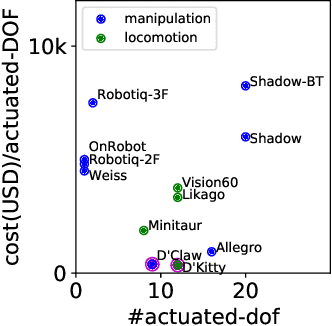
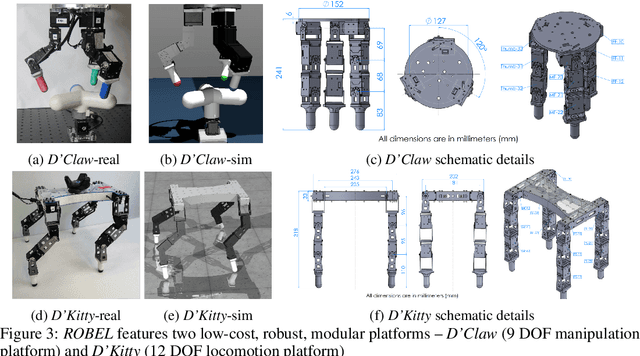
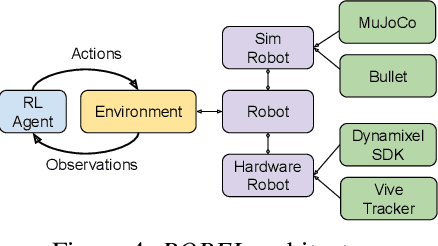
ROBEL is an open-source platform of cost-effective robots designed for reinforcement learning in the real world. ROBEL introduces two robots, each aimed to accelerate reinforcement learning research in different task domains: D'Claw is a three-fingered hand robot that facilitates learning dexterous manipulation tasks, and D'Kitty is a four-legged robot that facilitates learning agile legged locomotion tasks. These low-cost, modular robots are easy to maintain and are robust enough to sustain on-hardware reinforcement learning from scratch with over 14000 training hours registered on them to date. To leverage this platform, we propose an extensible set of continuous control benchmark tasks for each robot. These tasks feature dense and sparse task objectives, and additionally introduce score metrics as hardware-safety. We provide benchmark scores on an initial set of tasks using a variety of learning-based methods. Furthermore, we show that these results can be replicated across copies of the robots located in different institutions. Code, documentation, design files, detailed assembly instructions, final policies, baseline details, task videos, and all supplementary materials required to reproduce the results are available at www.roboticsbenchmarks.org.
* Accepted for CoRL2019. For details visit - www.roboticsbenchmarks.org
Dynamical Distance Learning for Unsupervised and Semi-Supervised Skill Discovery
Jul 18, 2019
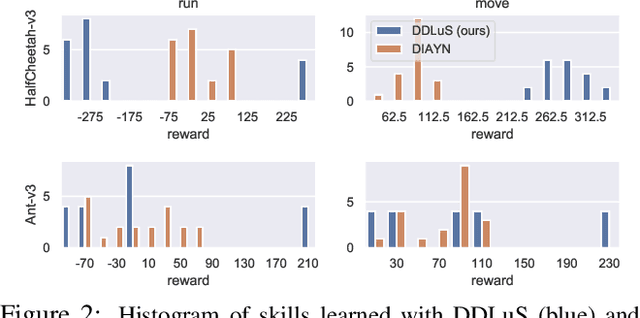
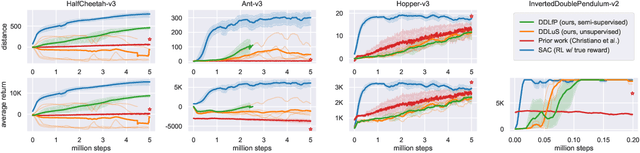
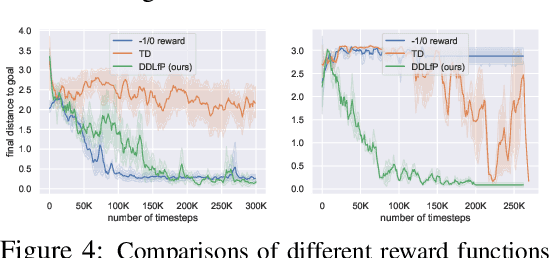
Reinforcement learning requires manual specification of a reward function to learn a task. While in principle this reward function only needs to specify the task goal, in practice reinforcement learning can be very time-consuming or even infeasible unless the reward function is shaped so as to provide a smooth gradient towards a successful outcome. This shaping is difficult to specify by hand, particularly when the task is learned from raw observations, such as images. In this paper, we study how we can automatically learn dynamical distances: a measure of the expected number of time steps to reach a given goal state from any other state. These dynamical distances can be used to provide well-shaped reward functions for reaching new goals, making it possible to learn complex tasks efficiently. We also show that dynamical distances can be used in a semi-supervised regime, where unsupervised interaction with the environment is used to learn the dynamical distances, while a small amount of preference supervision is used to determine the task goal, without any manually engineered reward function or goal examples. We evaluate our method both in simulation and on a real-world robot. We show that our method can learn locomotion skills in simulation without any supervision. We also show that it can learn to turn a valve with a real-world 9-DoF hand, using raw image observations and ten preference labels, without any other supervision. Videos of the learned skills can be found on the project website: https://sites.google.com/view/skills-via-distance-learning.
End-to-End Robotic Reinforcement Learning without Reward Engineering
May 16, 2019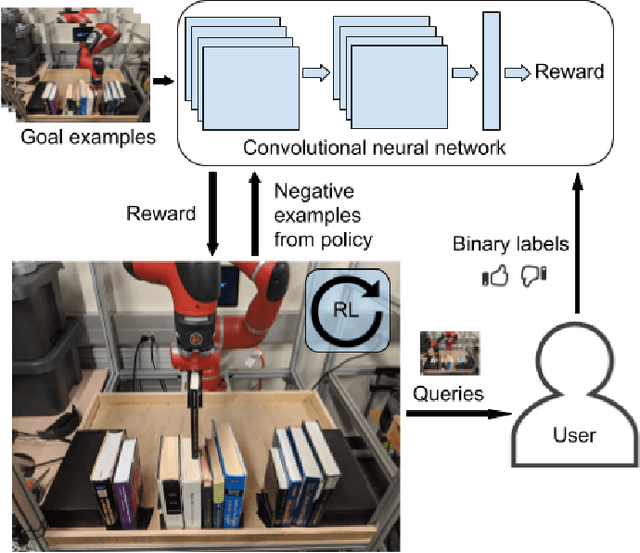
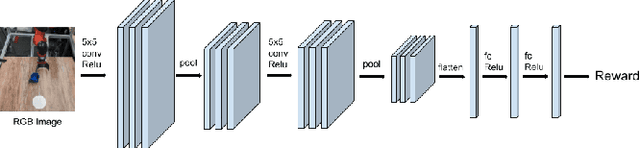

The combination of deep neural network models and reinforcement learning algorithms can make it possible to learn policies for robotic behaviors that directly read in raw sensory inputs, such as camera images, effectively subsuming both estimation and control into one model. However, real-world applications of reinforcement learning must specify the goal of the task by means of a manually programmed reward function, which in practice requires either designing the very same perception pipeline that end-to-end reinforcement learning promises to avoid, or else instrumenting the environment with additional sensors to determine if the task has been performed successfully. In this paper, we propose an approach for removing the need for manual engineering of reward specifications by enabling a robot to learn from a modest number of examples of successful outcomes, followed by actively solicited queries, where the robot shows the user a state and asks for a label to determine whether that state represents successful completion of the task. While requesting labels for every single state would amount to asking the user to manually provide the reward signal, our method requires labels for only a tiny fraction of the states seen during training, making it an efficient and practical approach for learning skills without manually engineered rewards. We evaluate our method on real-world robotic manipulation tasks where the observations consist of images viewed by the robot's camera. In our experiments, our method effectively learns to arrange objects, place books, and drape cloth, directly from images and without any manually specified reward functions, and with only 1-4 hours of interaction with the real world.
Soft Actor-Critic Algorithms and Applications
Jan 29, 2019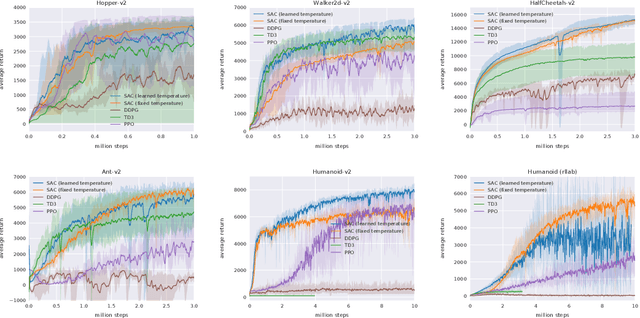



Model-free deep reinforcement learning (RL) algorithms have been successfully applied to a range of challenging sequential decision making and control tasks. However, these methods typically suffer from two major challenges: high sample complexity and brittleness to hyperparameters. Both of these challenges limit the applicability of such methods to real-world domains. In this paper, we describe Soft Actor-Critic (SAC), our recently introduced off-policy actor-critic algorithm based on the maximum entropy RL framework. In this framework, the actor aims to simultaneously maximize expected return and entropy. That is, to succeed at the task while acting as randomly as possible. We extend SAC to incorporate a number of modifications that accelerate training and improve stability with respect to the hyperparameters, including a constrained formulation that automatically tunes the temperature hyperparameter. We systematically evaluate SAC on a range of benchmark tasks, as well as real-world challenging tasks such as locomotion for a quadrupedal robot and robotic manipulation with a dexterous hand. With these improvements, SAC achieves state-of-the-art performance, outperforming prior on-policy and off-policy methods in sample-efficiency and asymptotic performance. Furthermore, we demonstrate that, in contrast to other off-policy algorithms, our approach is very stable, achieving similar performance across different random seeds. These results suggest that SAC is a promising candidate for learning in real-world robotics tasks.
Latent Space Policies for Hierarchical Reinforcement Learning
Sep 03, 2018

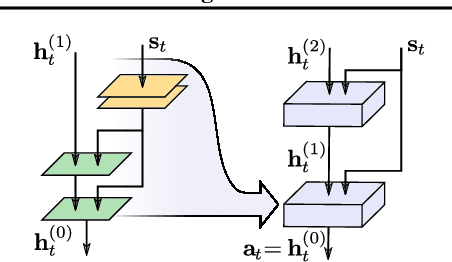
We address the problem of learning hierarchical deep neural network policies for reinforcement learning. In contrast to methods that explicitly restrict or cripple lower layers of a hierarchy to force them to use higher-level modulating signals, each layer in our framework is trained to directly solve the task, but acquires a range of diverse strategies via a maximum entropy reinforcement learning objective. Each layer is also augmented with latent random variables, which are sampled from a prior distribution during the training of that layer. The maximum entropy objective causes these latent variables to be incorporated into the layer's policy, and the higher level layer can directly control the behavior of the lower layer through this latent space. Furthermore, by constraining the mapping from latent variables to actions to be invertible, higher layers retain full expressivity: neither the higher layers nor the lower layers are constrained in their behavior. Our experimental evaluation demonstrates that we can improve on the performance of single-layer policies on standard benchmark tasks simply by adding additional layers, and that our method can solve more complex sparse-reward tasks by learning higher-level policies on top of high-entropy skills optimized for simple low-level objectives.