 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobotic Table Tennis: A Case Study into a High Speed Learning System
Sep 06, 2023



We present a deep-dive into a real-world robotic learning system that, in previous work, was shown to be capable of hundreds of table tennis rallies with a human and has the ability to precisely return the ball to desired targets. This system puts together a highly optimized perception subsystem, a high-speed low-latency robot controller, a simulation paradigm that can prevent damage in the real world and also train policies for zero-shot transfer, and automated real world environment resets that enable autonomous training and evaluation on physical robots. We complement a complete system description, including numerous design decisions that are typically not widely disseminated, with a collection of studies that clarify the importance of mitigating various sources of latency, accounting for training and deployment distribution shifts, robustness of the perception system, sensitivity to policy hyper-parameters, and choice of action space. A video demonstrating the components of the system and details of experimental results can be found at https://youtu.be/uFcnWjB42I0.
PaLM-E: An Embodied Multimodal Language Model
Mar 06, 2023



Large language models excel at a wide range of complex tasks. However, enabling general inference in the real world, e.g., for robotics problems, raises the challenge of grounding. We propose embodied language models to directly incorporate real-world continuous sensor modalities into language models and thereby establish the link between words and percepts. Input to our embodied language model are multi-modal sentences that interleave visual, continuous state estimation, and textual input encodings. We train these encodings end-to-end, in conjunction with a pre-trained large language model, for multiple embodied tasks including sequential robotic manipulation planning, visual question answering, and captioning. Our evaluations show that PaLM-E, a single large embodied multimodal model, can address a variety of embodied reasoning tasks, from a variety of observation modalities, on multiple embodiments, and further, exhibits positive transfer: the model benefits from diverse joint training across internet-scale language, vision, and visual-language domains. Our largest model, PaLM-E-562B with 562B parameters, in addition to being trained on robotics tasks, is a visual-language generalist with state-of-the-art performance on OK-VQA, and retains generalist language capabilities with increasing scale.
Interactive Language: Talking to Robots in Real Time
Oct 12, 2022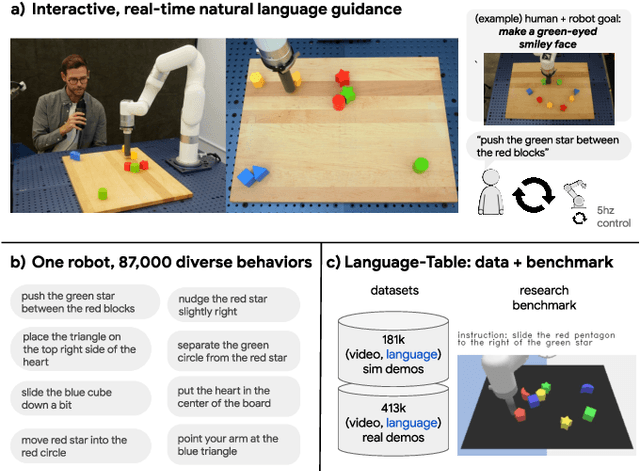
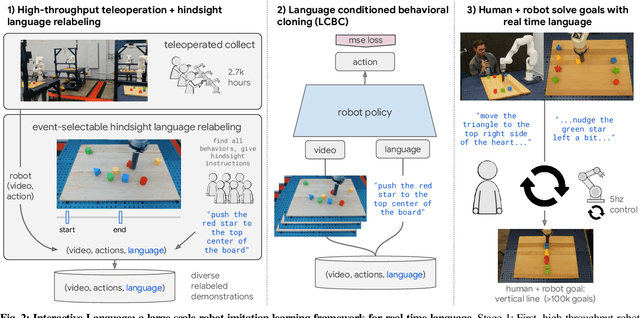
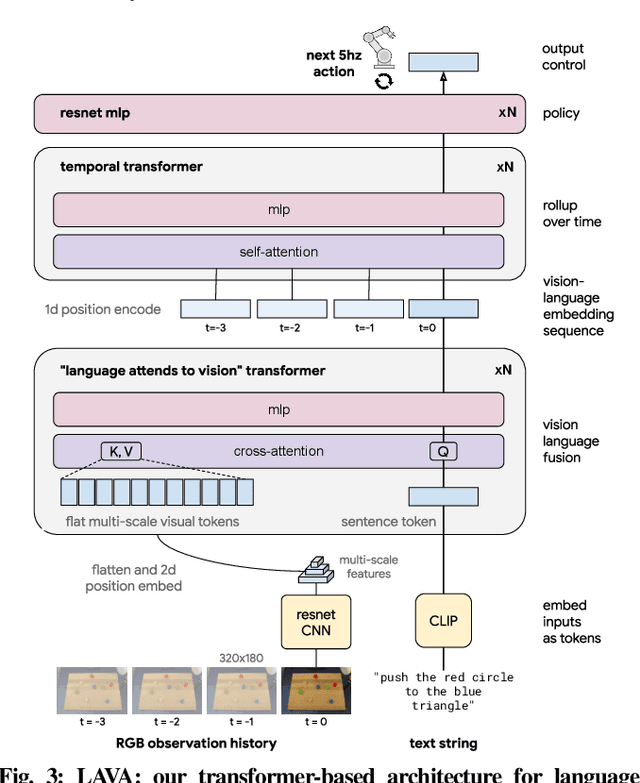

We present a framework for building interactive, real-time, natural language-instructable robots in the real world, and we open source related assets (dataset, environment, benchmark, and policies). Trained with behavioral cloning on a dataset of hundreds of thousands of language-annotated trajectories, a produced policy can proficiently execute an order of magnitude more commands than previous works: specifically we estimate a 93.5% success rate on a set of 87,000 unique natural language strings specifying raw end-to-end visuo-linguo-motor skills in the real world. We find that the same policy is capable of being guided by a human via real-time language to address a wide range of precise long-horizon rearrangement goals, e.g. "make a smiley face out of blocks". The dataset we release comprises nearly 600,000 language-labeled trajectories, an order of magnitude larger than prior available datasets. We hope the demonstrated results and associated assets enable further advancement of helpful, capable, natural-language-interactable robots. See videos at https://interactive-language.github.io.
Learning High Speed Precision Table Tennis on a Physical Robot
Oct 07, 2022
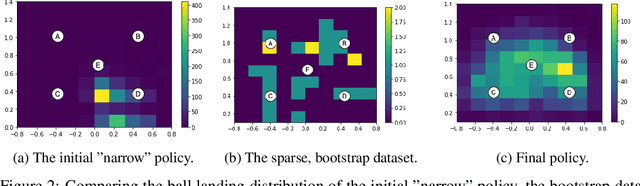
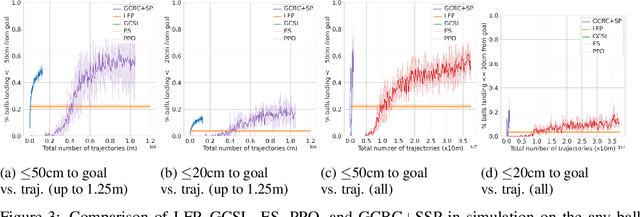
Learning goal conditioned control in the real world is a challenging open problem in robotics. Reinforcement learning systems have the potential to learn autonomously via trial-and-error, but in practice the costs of manual reward design, ensuring safe exploration, and hyperparameter tuning are often enough to preclude real world deployment. Imitation learning approaches, on the other hand, offer a simple way to learn control in the real world, but typically require costly curated demonstration data and lack a mechanism for continuous improvement. Recently, iterative imitation techniques have been shown to learn goal directed control from undirected demonstration data, and improve continuously via self-supervised goal reaching, but results thus far have been limited to simulated environments. In this work, we present evidence that iterative imitation learning can scale to goal-directed behavior on a real robot in a dynamic setting: high speed, precision table tennis (e.g. "land the ball on this particular target"). We find that this approach offers a straightforward way to do continuous on-robot learning, without complexities such as reward design or sim-to-real transfer. It is also scalable -- sample efficient enough to train on a physical robot in just a few hours. In real world evaluations, we find that the resulting policy can perform on par or better than amateur humans (with players sampled randomly from a robotics lab) at the task of returning the ball to specific targets on the table. Finally, we analyze the effect of an initial undirected bootstrap dataset size on performance, finding that a modest amount of unstructured demonstration data provided up-front drastically speeds up the convergence of a general purpose goal-reaching policy. See https://sites.google.com/view/goals-eye for videos.
Visuomotor Control in Multi-Object Scenes Using Object-Aware Representations
May 12, 2022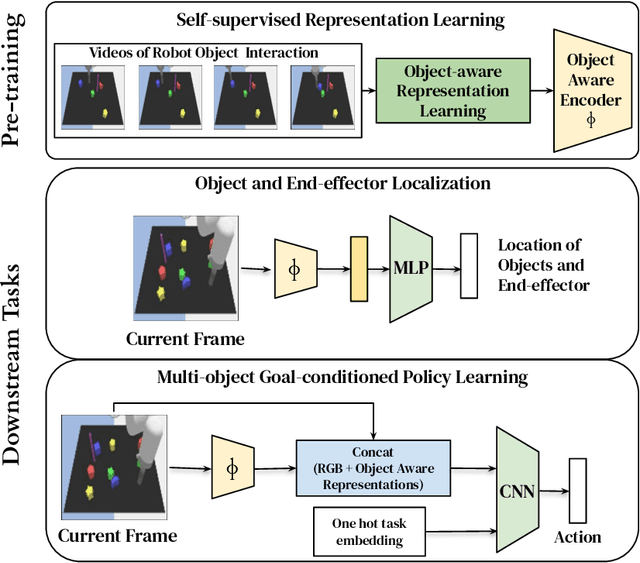
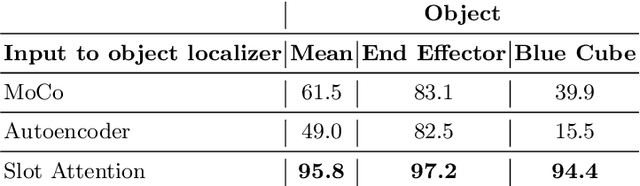

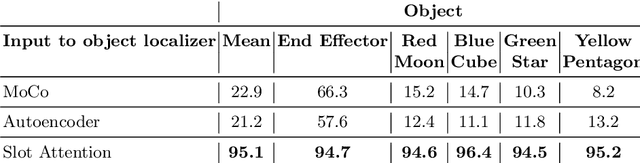
Perceptual understanding of the scene and the relationship between its different components is important for successful completion of robotic tasks. Representation learning has been shown to be a powerful technique for this, but most of the current methodologies learn task specific representations that do not necessarily transfer well to other tasks. Furthermore, representations learned by supervised methods require large labeled datasets for each task that are expensive to collect in the real world. Using self-supervised learning to obtain representations from unlabeled data can mitigate this problem. However, current self-supervised representation learning methods are mostly object agnostic, and we demonstrate that the resulting representations are insufficient for general purpose robotics tasks as they fail to capture the complexity of scenes with many components. In this paper, we explore the effectiveness of using object-aware representation learning techniques for robotic tasks. Our self-supervised representations are learned by observing the agent freely interacting with different parts of the environment and is queried in two different settings: (i) policy learning and (ii) object location prediction. We show that our model learns control policies in a sample-efficient manner and outperforms state-of-the-art object agnostic techniques as well as methods trained on raw RGB images. Our results show a 20 percent increase in performance in low data regimes (1000 trajectories) in policy training using implicit behavioral cloning (IBC). Furthermore, our method outperforms the baselines for the task of object localization in multi-object scenes.
Demonstration-Bootstrapped Autonomous Practicing via Multi-Task Reinforcement Learning
Mar 29, 2022
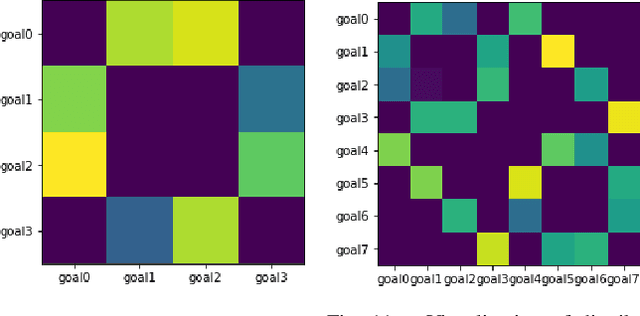
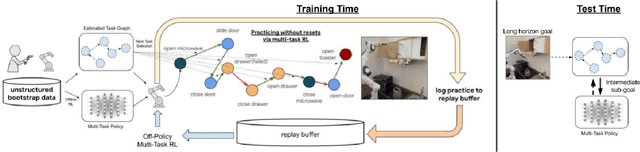
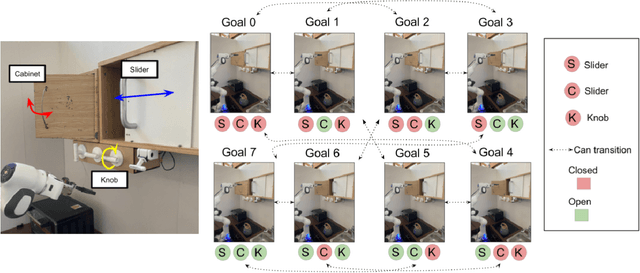
Reinforcement learning systems have the potential to enable continuous improvement in unstructured environments, leveraging data collected autonomously. However, in practice these systems require significant amounts of instrumentation or human intervention to learn in the real world. In this work, we propose a system for reinforcement learning that leverages multi-task reinforcement learning bootstrapped with prior data to enable continuous autonomous practicing, minimizing the number of resets needed while being able to learn temporally extended behaviors. We show how appropriately provided prior data can help bootstrap both low-level multi-task policies and strategies for sequencing these tasks one after another to enable learning with minimal resets. This mechanism enables our robotic system to practice with minimal human intervention at training time while being able to solve long horizon tasks at test time. We show the efficacy of the proposed system on a challenging kitchen manipulation task both in simulation and in the real world, demonstrating the ability to practice autonomously in order to solve temporally extended problems.
BC-Z: Zero-Shot Task Generalization with Robotic Imitation Learning
Feb 04, 2022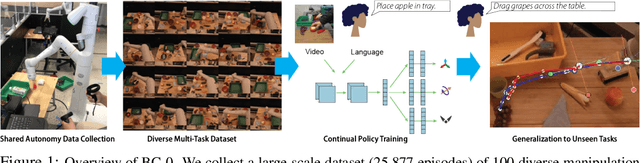
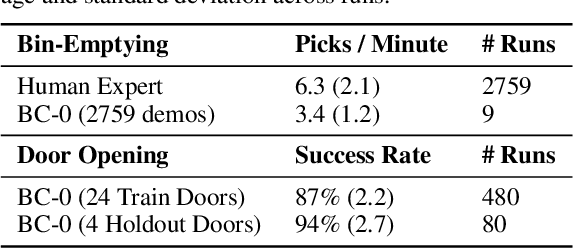

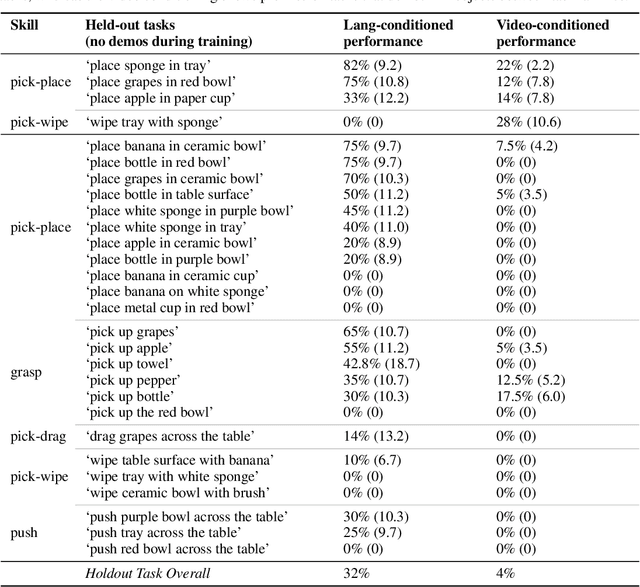
In this paper, we study the problem of enabling a vision-based robotic manipulation system to generalize to novel tasks, a long-standing challenge in robot learning. We approach the challenge from an imitation learning perspective, aiming to study how scaling and broadening the data collected can facilitate such generalization. To that end, we develop an interactive and flexible imitation learning system that can learn from both demonstrations and interventions and can be conditioned on different forms of information that convey the task, including pre-trained embeddings of natural language or videos of humans performing the task. When scaling data collection on a real robot to more than 100 distinct tasks, we find that this system can perform 24 unseen manipulation tasks with an average success rate of 44%, without any robot demonstrations for those tasks.
* CoRL 2021, 23 pages
Implicit Behavioral Cloning
Sep 01, 2021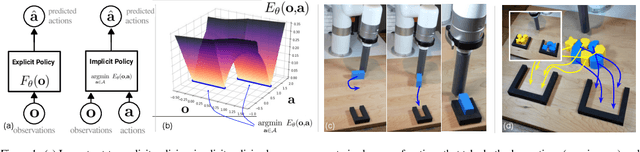

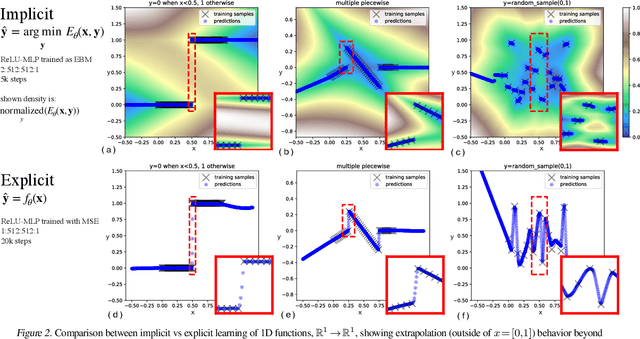
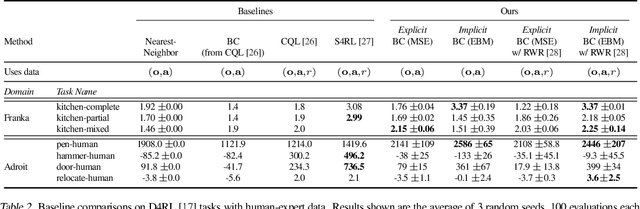
We find that across a wide range of robot policy learning scenarios, treating supervised policy learning with an implicit model generally performs better, on average, than commonly used explicit models. We present extensive experiments on this finding, and we provide both intuitive insight and theoretical arguments distinguishing the properties of implicit models compared to their explicit counterparts, particularly with respect to approximating complex, potentially discontinuous and multi-valued (set-valued) functions. On robotic policy learning tasks we show that implicit behavioral cloning policies with energy-based models (EBM) often outperform common explicit (Mean Square Error, or Mixture Density) behavioral cloning policies, including on tasks with high-dimensional action spaces and visual image inputs. We find these policies provide competitive results or outperform state-of-the-art offline reinforcement learning methods on the challenging human-expert tasks from the D4RL benchmark suite, despite using no reward information. In the real world, robots with implicit policies can learn complex and remarkably subtle behaviors on contact-rich tasks from human demonstrations, including tasks with high combinatorial complexity and tasks requiring 1mm precision.
Broadly-Exploring, Local-Policy Trees for Long-Horizon Task Planning
Oct 13, 2020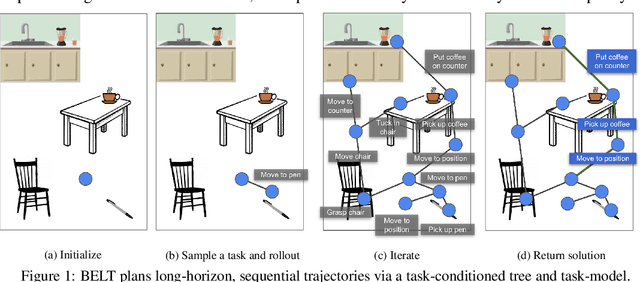
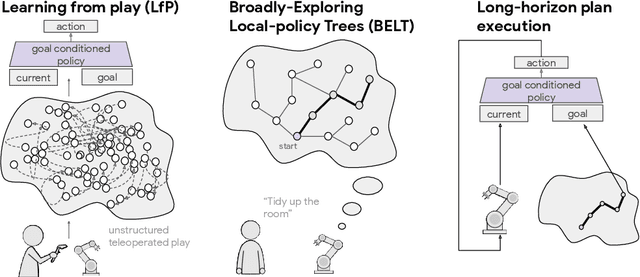
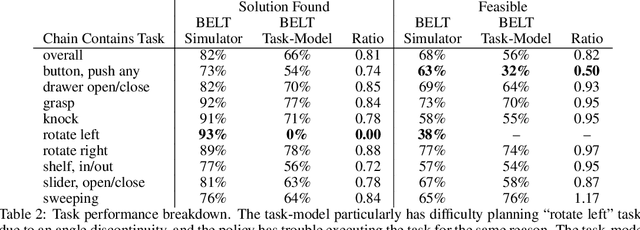
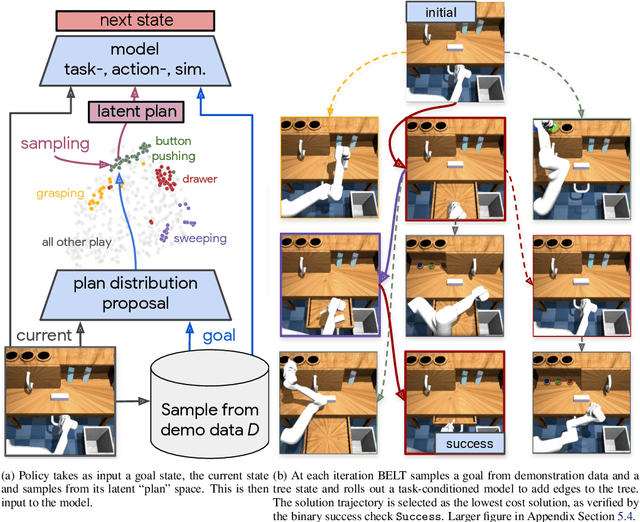
Long-horizon planning in realistic environments requires the ability to reason over sequential tasks in high-dimensional state spaces with complex dynamics. Classical motion planning algorithms, such as rapidly-exploring random trees, are capable of efficiently exploring large state spaces and computing long-horizon, sequential plans. However, these algorithms are generally challenged with complex, stochastic, and high-dimensional state spaces as well as in the presence of narrow passages, which naturally emerge in tasks that interact with the environment. Machine learning offers a promising solution for its ability to learn general policies that can handle complex interactions and high-dimensional observations. However, these policies are generally limited in horizon length. Our approach, Broadly-Exploring, Local-policy Trees (BELT), merges these two approaches to leverage the strengths of both through a task-conditioned, model-based tree search. BELT uses an RRT-inspired tree search to efficiently explore the state space. Locally, the exploration is guided by a task-conditioned, learned policy capable of performing general short-horizon tasks. This task space can be quite general and abstract; its only requirements are to be sampleable and to well-cover the space of useful tasks. This search is aided by a task-conditioned model that temporally extends dynamics propagation to allow long-horizon search and sequential reasoning over tasks. BELT is demonstrated experimentally to be able to plan long-horizon, sequential trajectories with a goal conditioned policy and generate plans that are robust.
Learning to Play by Imitating Humans
Jun 11, 2020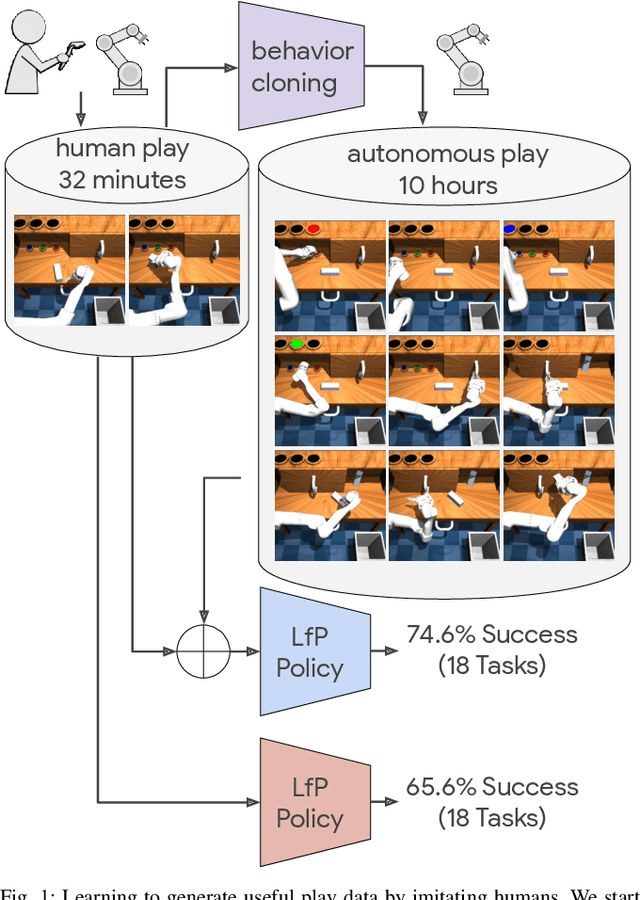

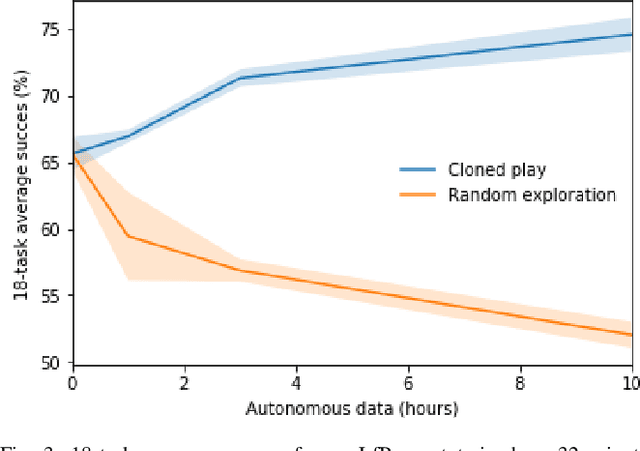
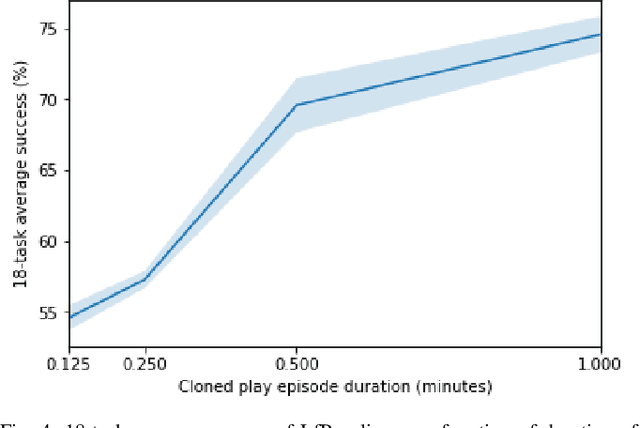
Acquiring multiple skills has commonly involved collecting a large number of expert demonstrations per task or engineering custom reward functions. Recently it has been shown that it is possible to acquire a diverse set of skills by self-supervising control on top of human teleoperated play data. Play is rich in state space coverage and a policy trained on this data can generalize to specific tasks at test time outperforming policies trained on individual expert task demonstrations. In this work, we explore the question of whether robots can learn to play to autonomously generate play data that can ultimately enhance performance. By training a behavioral cloning policy on a relatively small quantity of human play, we autonomously generate a large quantity of cloned play data that can be used as additional training. We demonstrate that a general purpose goal-conditioned policy trained on this augmented dataset substantially outperforms one trained only with the original human data on 18 difficult user-specified manipulation tasks in a simulated robotic tabletop environment. A video example of a robot imitating human play can be seen here: https://learning-to-play.github.io/videos/undirected_play1.mp4