 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Progress Toward AGI: A Cognitive Framework
May 27, 2026Despite widespread discussion of AGI, there is no clear framework for measuring progress toward it. This ambiguity fuels subjective claims, makes it difficult to track progress, and risks hindering responsible governance. As a starting point to address this gap, we present a framework for understanding system capabilities in relation to human cognitive abilities. Drawing from decades of research in psychology, neuroscience, and cognitive science, we introduce a Cognitive Taxonomy that deconstructs general intelligence into 10 key cognitive faculties. We then propose a rigorous evaluation protocol in which a system's performance is measured across a suite of targeted, held-out cognitive tasks, generating a 'cognitive profile' that can be used to understand a system's strengths and weaknesses. We hope this framework will provide a practical roadmap and an initial step toward more rigorous, empirical evaluation of AGI.
Can AI mediation improve democratic deliberation?
Jan 09, 2026The strength of democracy lies in the free and equal exchange of diverse viewpoints. Living up to this ideal at scale faces inherent tensions: broad participation, meaningful deliberation, and political equality often trade off with one another (Fishkin, 2011). We ask whether and how artificial intelligence (AI) could help navigate this "trilemma" by engaging with a recent example of a large language model (LLM)-based system designed to help people with diverse viewpoints find common ground (Tessler, Bakker, et al., 2024). Here, we explore the implications of the introduction of LLMs into deliberation augmentation tools, examining their potential to enhance participation through scalability, improve political equality via fair mediation, and foster meaningful deliberation by, for example, surfacing trustworthy information. We also point to key challenges that remain. Ultimately, a range of empirical, technical, and theoretical advancements are needed to fully realize the promise of AI-mediated deliberation for enhancing citizen engagement and strengthening democratic deliberation.
Meta-in-context learning in large language models
May 22, 2023Large language models have shown tremendous performance in a variety of tasks. In-context learning -- the ability to improve at a task after being provided with a number of demonstrations -- is seen as one of the main contributors to their success. In the present paper, we demonstrate that the in-context learning abilities of large language models can be recursively improved via in-context learning itself. We coin this phenomenon meta-in-context learning. Looking at two idealized domains, a one-dimensional regression task and a two-armed bandit task, we show that meta-in-context learning adaptively reshapes a large language model's priors over expected tasks. Furthermore, we find that meta-in-context learning modifies the in-context learning strategies of such models. Finally, we extend our approach to a benchmark of real-world regression problems where we observe competitive performance to traditional learning algorithms. Taken together, our work improves our understanding of in-context learning and paves the way toward adapting large language models to the environment they are applied purely through meta-in-context learning rather than traditional finetuning.
DiscoGen: Learning to Discover Gene Regulatory Networks
Apr 12, 2023Accurately inferring Gene Regulatory Networks (GRNs) is a critical and challenging task in biology. GRNs model the activatory and inhibitory interactions between genes and are inherently causal in nature. To accurately identify GRNs, perturbational data is required. However, most GRN discovery methods only operate on observational data. Recent advances in neural network-based causal discovery methods have significantly improved causal discovery, including handling interventional data, improvements in performance and scalability. However, applying state-of-the-art (SOTA) causal discovery methods in biology poses challenges, such as noisy data and a large number of samples. Thus, adapting the causal discovery methods is necessary to handle these challenges. In this paper, we introduce DiscoGen, a neural network-based GRN discovery method that can denoise gene expression measurements and handle interventional data. We demonstrate that our model outperforms SOTA neural network-based causal discovery methods.
Meta-Learned Models of Cognition
Apr 12, 2023Meta-learning is a framework for learning learning algorithms through repeated interactions with an environment as opposed to designing them by hand. In recent years, this framework has established itself as a promising tool for building models of human cognition. Yet, a coherent research program around meta-learned models of cognition is still missing. The purpose of this article is to synthesize previous work in this field and establish such a research program. We rely on three key pillars to accomplish this goal. We first point out that meta-learning can be used to construct Bayes-optimal learning algorithms. This result not only implies that any behavioral phenomenon that can be explained by a Bayesian model can also be explained by a meta-learned model but also allows us to draw strong connections to the rational analysis of cognition. We then discuss several advantages of the meta-learning framework over traditional Bayesian methods. In particular, we argue that meta-learning can be applied to situations where Bayesian inference is impossible and that it enables us to make rational models of cognition more realistic, either by incorporating limited computational resources or neuroscientific knowledge. Finally, we reexamine prior studies from psychology and neuroscience that have applied meta-learning and put them into the context of these new insights. In summary, our work highlights that meta-learning considerably extends the scope of rational analysis and thereby of cognitive theories more generally.
Toward Next-Generation Artificial Intelligence: Catalyzing the NeuroAI Revolution
Oct 15, 2022Neuroscience has long been an important driver of progress in artificial intelligence (AI). We propose that to accelerate progress in AI, we must invest in fundamental research in NeuroAI.
HCMD-zero: Learning Value Aligned Mechanisms from Data
Feb 21, 2022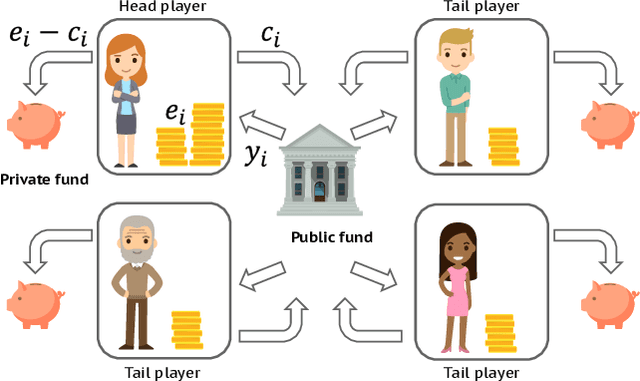

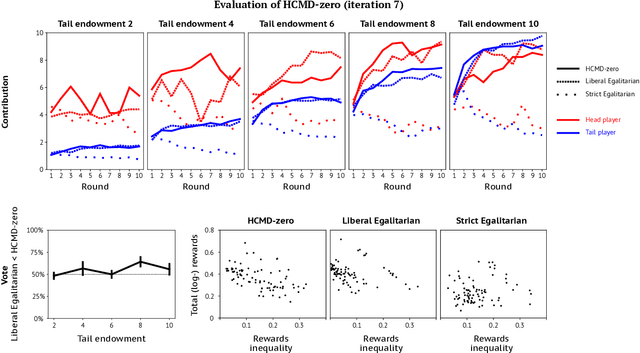
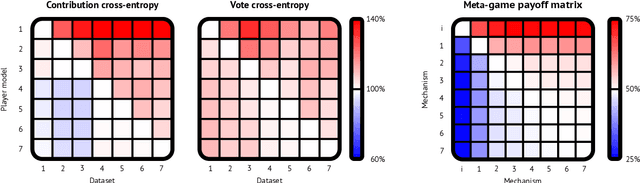
Artificial learning agents are mediating a larger and larger number of interactions among humans, firms, and organizations, and the intersection between mechanism design and machine learning has been heavily investigated in recent years. However, mechanism design methods make strong assumptions on how participants behave (e.g. rationality), or on the kind of knowledge designers have access to a priori (e.g. access to strong baseline mechanisms). Here we introduce HCMD-zero, a general purpose method to construct mechanism agents. HCMD-zero learns by mediating interactions among participants, while remaining engaged in an electoral contest with copies of itself, thereby accessing direct feedback from participants. Our results on the Public Investment Game, a stylized resource allocation game that highlights the tension between productivity, equality and the temptation to free-ride, show that HCMD-zero produces competitive mechanism agents that are consistently preferred by human participants over baseline alternatives, and does so automatically, without requiring human knowledge, and by using human data sparingly and effectively Our detailed analysis shows HCMD-zero elicits consistent improvements over the course of training, and that it results in a mechanism with an interpretable and intuitive policy.
General-purpose, long-context autoregressive modeling with Perceiver AR
Feb 15, 2022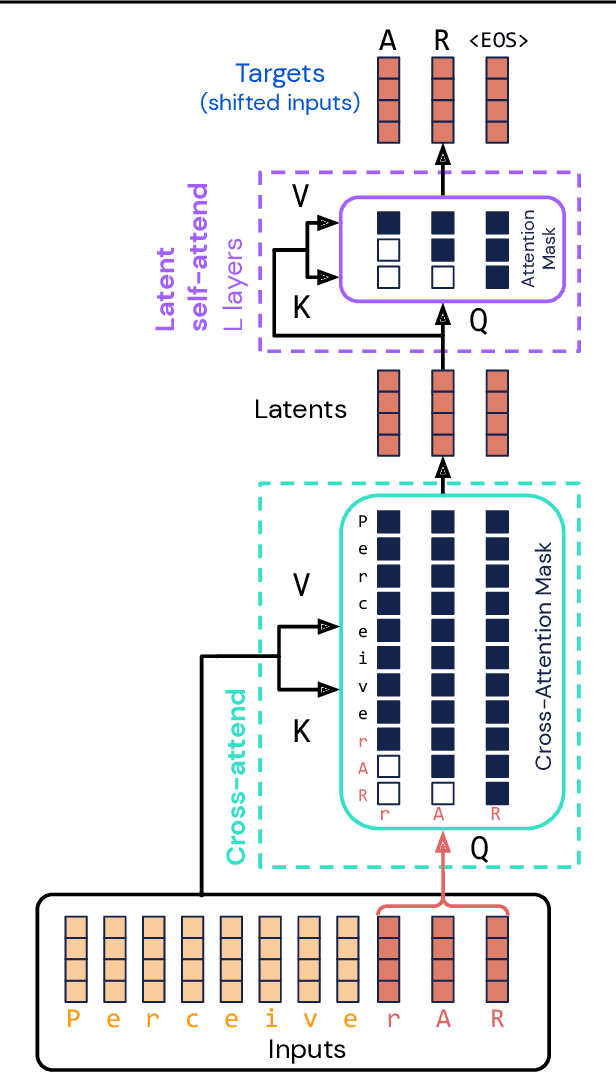
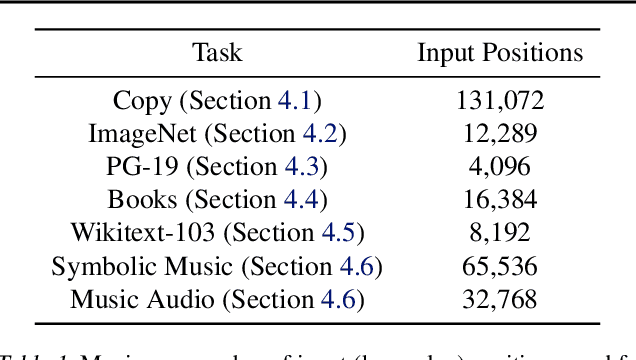
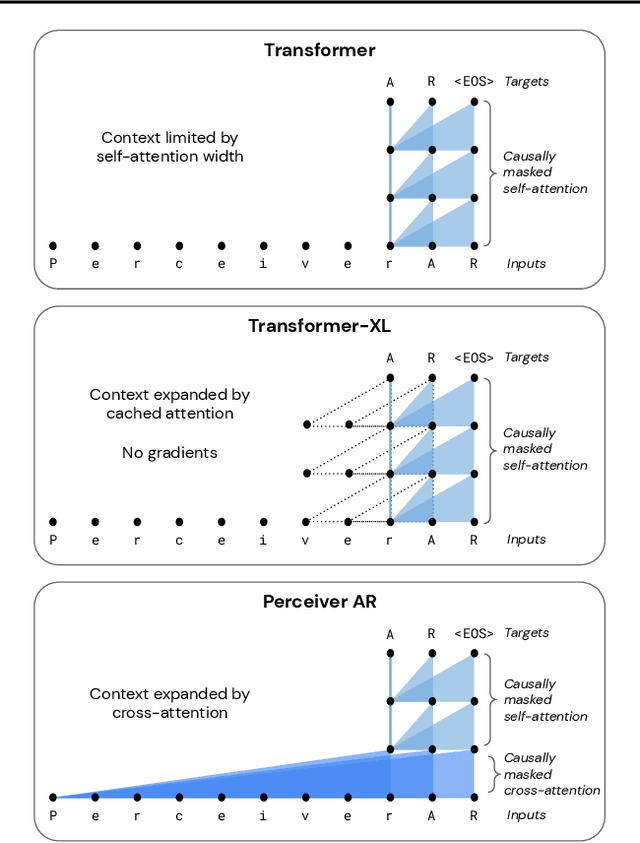
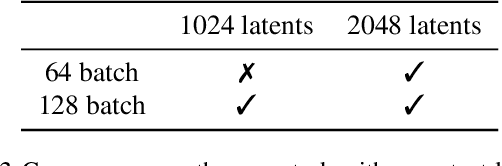
Real-world data is high-dimensional: a book, image, or musical performance can easily contain hundreds of thousands of elements even after compression. However, the most commonly used autoregressive models, Transformers, are prohibitively expensive to scale to the number of inputs and layers needed to capture this long-range structure. We develop Perceiver AR, an autoregressive, modality-agnostic architecture which uses cross-attention to map long-range inputs to a small number of latents while also maintaining end-to-end causal masking. Perceiver AR can directly attend to over a hundred thousand tokens, enabling practical long-context density estimation without the need for hand-crafted sparsity patterns or memory mechanisms. When trained on images or music, Perceiver AR generates outputs with clear long-term coherence and structure. Our architecture also obtains state-of-the-art likelihood on long-sequence benchmarks, including 64 x 64 ImageNet images and PG-19 books.
Human-centered mechanism design with Democratic AI
Jan 27, 2022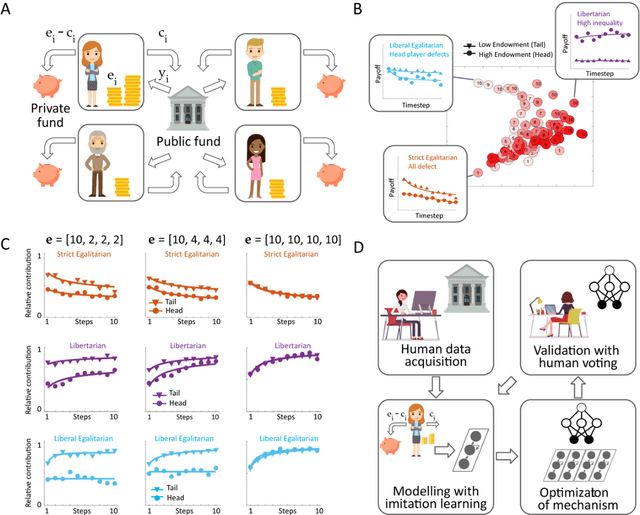
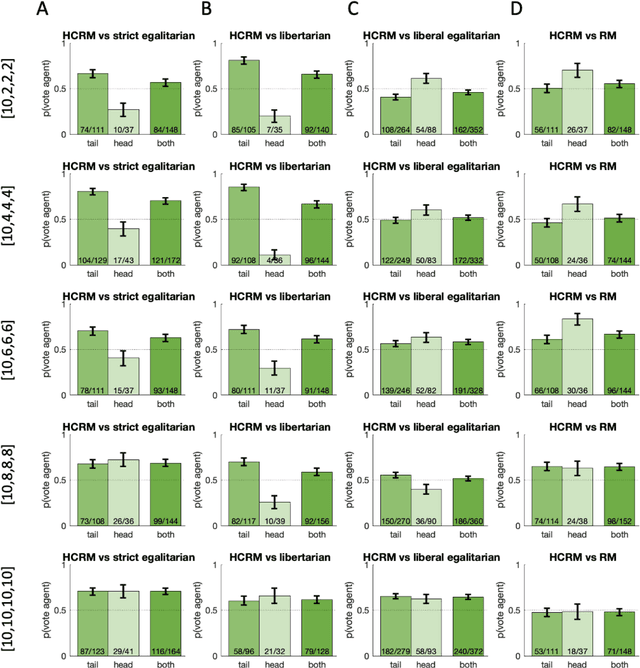
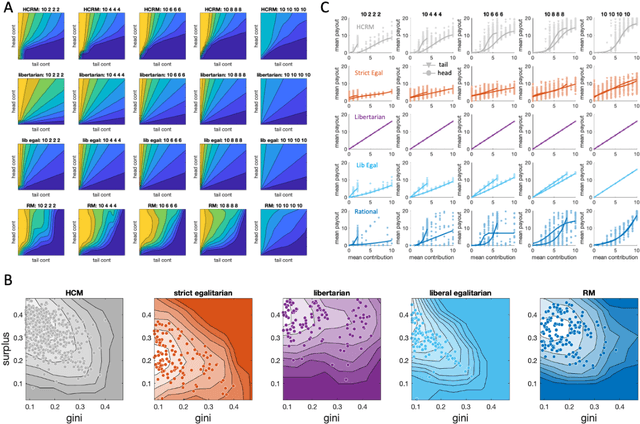
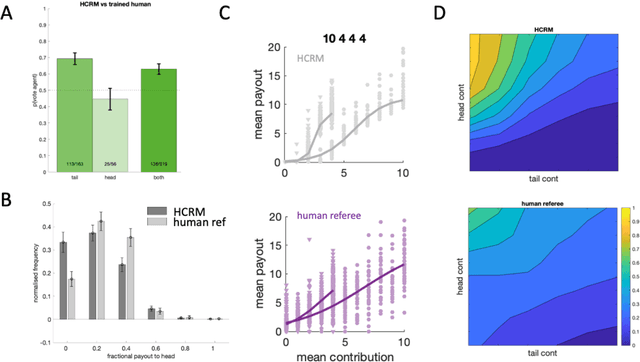
Building artificial intelligence (AI) that aligns with human values is an unsolved problem. Here, we developed a human-in-the-loop research pipeline called Democratic AI, in which reinforcement learning is used to design a social mechanism that humans prefer by majority. A large group of humans played an online investment game that involved deciding whether to keep a monetary endowment or to share it with others for collective benefit. Shared revenue was returned to players under two different redistribution mechanisms, one designed by the AI and the other by humans. The AI discovered a mechanism that redressed initial wealth imbalance, sanctioned free riders, and successfully won the majority vote. By optimizing for human preferences, Democratic AI may be a promising method for value-aligned policy innovation.
SIMONe: View-Invariant, Temporally-Abstracted Object Representations via Unsupervised Video Decomposition
Jun 07, 2021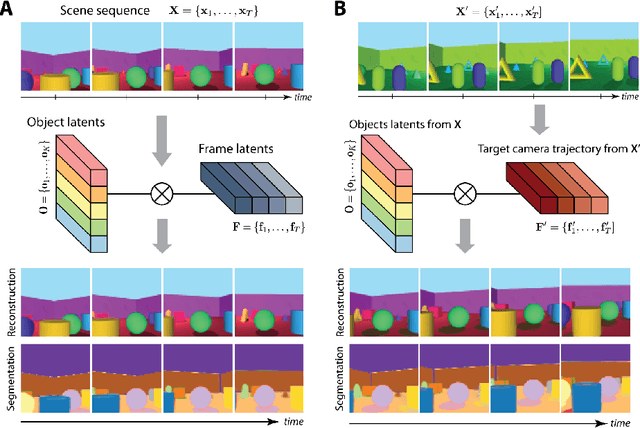
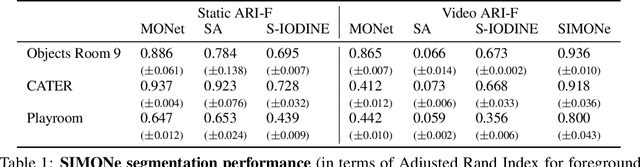
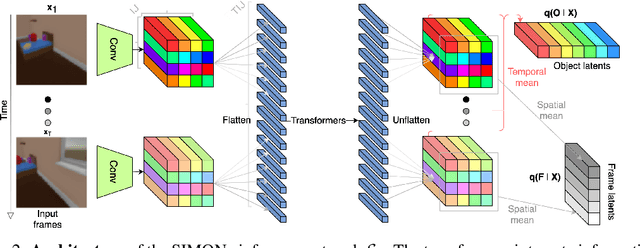

To help agents reason about scenes in terms of their building blocks, we wish to extract the compositional structure of any given scene (in particular, the configuration and characteristics of objects comprising the scene). This problem is especially difficult when scene structure needs to be inferred while also estimating the agent's location/viewpoint, as the two variables jointly give rise to the agent's observations. We present an unsupervised variational approach to this problem. Leveraging the shared structure that exists across different scenes, our model learns to infer two sets of latent representations from RGB video input alone: a set of "object" latents, corresponding to the time-invariant, object-level contents of the scene, as well as a set of "frame" latents, corresponding to global time-varying elements such as viewpoint. This factorization of latents allows our model, SIMONe, to represent object attributes in an allocentric manner which does not depend on viewpoint. Moreover, it allows us to disentangle object dynamics and summarize their trajectories as time-abstracted, view-invariant, per-object properties. We demonstrate these capabilities, as well as the model's performance in terms of view synthesis and instance segmentation, across three procedurally generated video datasets.