 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSDA3D: Semi-supervised Domain Adaptation for 3D Object Detection from Point Cloud
Dec 06, 2022LiDAR-based 3D object detection is an indispensable task in advanced autonomous driving systems. Though impressive detection results have been achieved by superior 3D detectors, they suffer from significant performance degeneration when facing unseen domains, such as different LiDAR configurations, different cities, and weather conditions. The mainstream approaches tend to solve these challenges by leveraging unsupervised domain adaptation (UDA) techniques. However, these UDA solutions just yield unsatisfactory 3D detection results when there is a severe domain shift, e.g., from Waymo (64-beam) to nuScenes (32-beam). To address this, we present a novel Semi-Supervised Domain Adaptation method for 3D object detection (SSDA3D), where only a few labeled target data is available, yet can significantly improve the adaptation performance. In particular, our SSDA3D includes an Inter-domain Adaptation stage and an Intra-domain Generalization stage. In the first stage, an Inter-domain Point-CutMix module is presented to efficiently align the point cloud distribution across domains. The Point-CutMix generates mixed samples of an intermediate domain, thus encouraging to learn domain-invariant knowledge. Then, in the second stage, we further enhance the model for better generalization on the unlabeled target set. This is achieved by exploring Intra-domain Point-MixUp in semi-supervised learning, which essentially regularizes the pseudo label distribution. Experiments from Waymo to nuScenes show that, with only 10% labeled target data, our SSDA3D can surpass the fully-supervised oracle model with 100% target label. Our code is available at https://github.com/yinjunbo/SSDA3D.
Transformation-Equivariant 3D Object Detection for Autonomous Driving
Dec 01, 2022



3D object detection received increasing attention in autonomous driving recently. Objects in 3D scenes are distributed with diverse orientations. Ordinary detectors do not explicitly model the variations of rotation and reflection transformations. Consequently, large networks and extensive data augmentation are required for robust detection. Recent equivariant networks explicitly model the transformation variations by applying shared networks on multiple transformed point clouds, showing great potential in object geometry modeling. However, it is difficult to apply such networks to 3D object detection in autonomous driving due to its large computation cost and slow reasoning speed. In this work, we present TED, an efficient Transformation-Equivariant 3D Detector to overcome the computation cost and speed issues. TED first applies a sparse convolution backbone to extract multi-channel transformation-equivariant voxel features; and then aligns and aggregates these equivariant features into lightweight and compact representations for high-performance 3D object detection. On the highly competitive KITTI 3D car detection leaderboard, TED ranked 1st among all submissions with competitive efficiency.
Zero-shot Point Cloud Segmentation by Transferring Geometric Primitives
Oct 18, 2022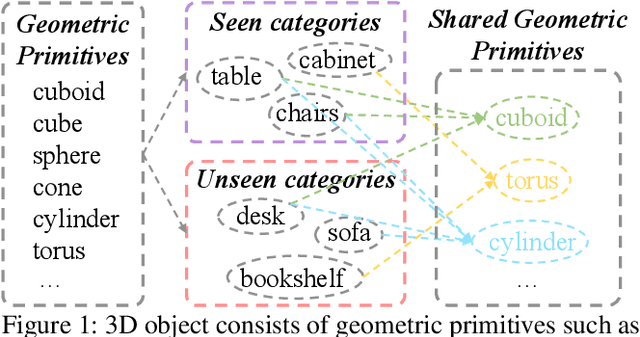
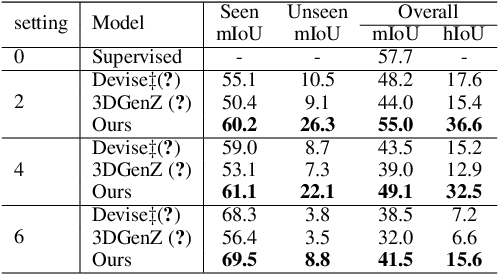

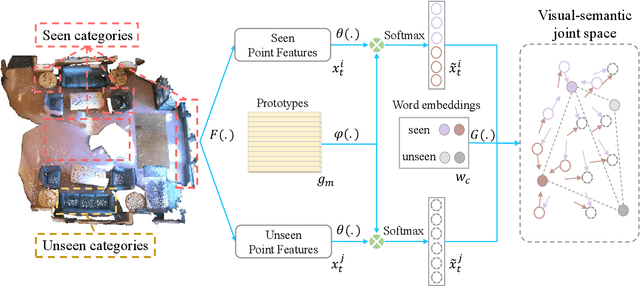
We investigate transductive zero-shot point cloud semantic segmentation in this paper, where unseen class labels are unavailable during training. Actually, the 3D geometric elements are essential cues to reason the 3D object type. If two categories share similar geometric primitives, they also have similar semantic representations. Based on this consideration, we propose a novel framework to learn the geometric primitives shared in seen and unseen categories' objects, where the learned geometric primitives are served for transferring knowledge from seen to unseen categories. Specifically, a group of learnable prototypes automatically encode geometric primitives via back-propagation. Then, the point visual representation is formulated as the similarity vector of its feature to the prototypes, which implies semantic cues for both seen and unseen categories. Besides, considering a 3D object composed of multiple geometric primitives, we formulate the semantic representation as a mixture-distributed embedding for the fine-grained match of visual representation. In the end, to effectively learn the geometric primitives and alleviate the misclassification issue, we propose a novel unknown-aware infoNCE loss to align the visual and semantic representation. As a result, guided by semantic representations, the network recognizes the novel object represented with geometric primitives. Extensive experiments show that our method significantly outperforms other state-of-the-art methods in the harmonic mean-intersection-over-union (hIoU), with the improvement of 17.8%, 30.4% and 9.2% on S3DIS, ScanNet and SemanticKITTI datasets, respectively. Codes will be released.
Vision-Centric BEV Perception: A Survey
Aug 04, 2022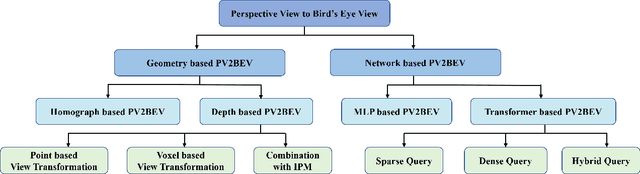

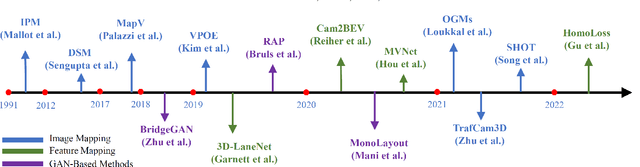
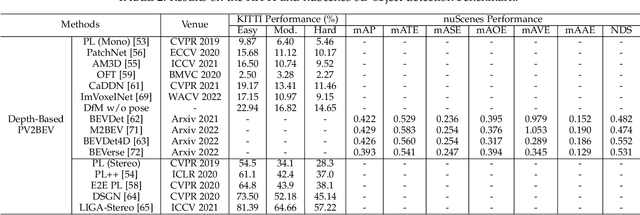
Vision-centric BEV perception has recently received increased attention from both industry and academia due to its inherent merits, including presenting a natural representation of the world and being fusion-friendly. With the rapid development of deep learning, numerous methods have been proposed to address the vision-centric BEV perception. However, there is no recent survey for this novel and growing research field. To stimulate its future research, this paper presents a comprehensive survey of recent progress of vision-centric BEV perception and its extensions. It collects and organizes the recent knowledge, and gives a systematic review and summary of commonly used algorithms. It also provides in-depth analyses and comparative results on several BEV perception tasks, facilitating the comparisons of future works and inspiring future research directions. Moreover, empirical implementation details are also discussed and shown to benefit the development of related algorithms.
Graph Neural Network and Spatiotemporal Transformer Attention for 3D Video Object Detection from Point Clouds
Jul 26, 2022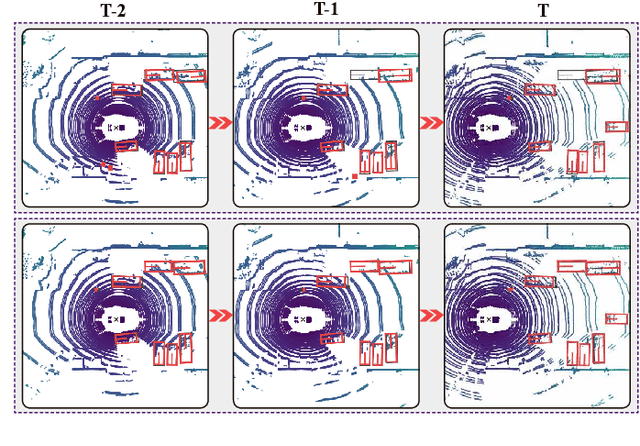
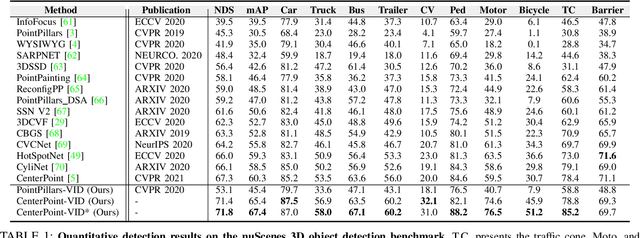
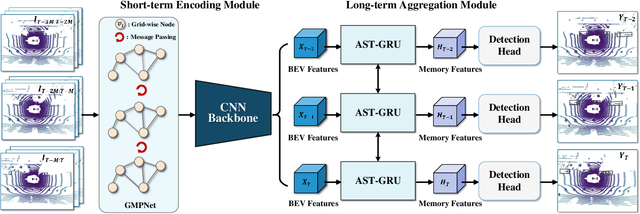

Previous works for LiDAR-based 3D object detection mainly focus on the single-frame paradigm. In this paper, we propose to detect 3D objects by exploiting temporal information in multiple frames, i.e., the point cloud videos. We empirically categorize the temporal information into short-term and long-term patterns. To encode the short-term data, we present a Grid Message Passing Network (GMPNet), which considers each grid (i.e., the grouped points) as a node and constructs a k-NN graph with the neighbor grids. To update features for a grid, GMPNet iteratively collects information from its neighbors, thus mining the motion cues in grids from nearby frames. To further aggregate the long-term frames, we propose an Attentive Spatiotemporal Transformer GRU (AST-GRU), which contains a Spatial Transformer Attention (STA) module and a Temporal Transformer Attention (TTA) module. STA and TTA enhance the vanilla GRU to focus on small objects and better align the moving objects. Our overall framework supports both online and offline video object detection in point clouds. We implement our algorithm based on prevalent anchor-based and anchor-free detectors. The evaluation results on the challenging nuScenes benchmark show the superior performance of our method, achieving the 1st on the leaderboard without any bells and whistles, by the time the paper is submitted.
STCrowd: A Multimodal Dataset for Pedestrian Perception in Crowded Scenes
Apr 03, 2022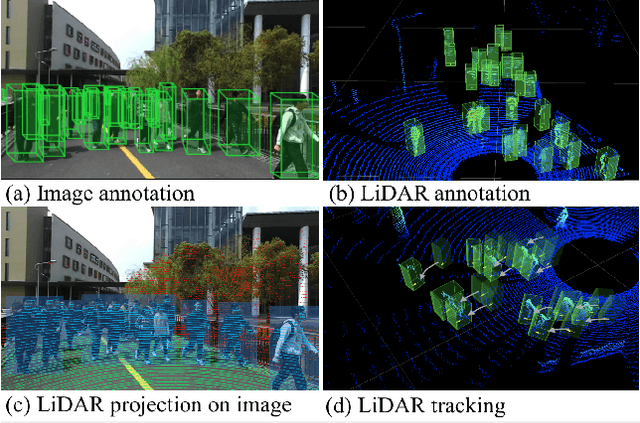
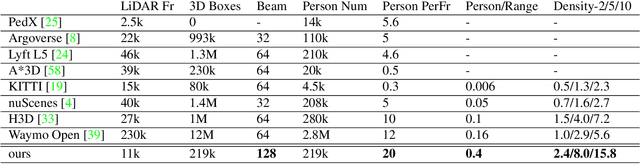

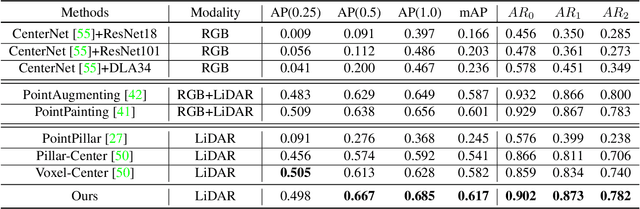
Accurately detecting and tracking pedestrians in 3D space is challenging due to large variations in rotations, poses and scales. The situation becomes even worse for dense crowds with severe occlusions. However, existing benchmarks either only provide 2D annotations, or have limited 3D annotations with low-density pedestrian distribution, making it difficult to build a reliable pedestrian perception system especially in crowded scenes. To better evaluate pedestrian perception algorithms in crowded scenarios, we introduce a large-scale multimodal dataset,STCrowd. Specifically, in STCrowd, there are a total of 219 K pedestrian instances and 20 persons per frame on average, with various levels of occlusion. We provide synchronized LiDAR point clouds and camera images as well as their corresponding 3D labels and joint IDs. STCrowd can be used for various tasks, including LiDAR-only, image-only, and sensor-fusion based pedestrian detection and tracking. We provide baselines for most of the tasks. In addition, considering the property of sparse global distribution and density-varying local distribution of pedestrians, we further propose a novel method, Density-aware Hierarchical heatmap Aggregation (DHA), to enhance pedestrian perception in crowded scenes. Extensive experiments show that our new method achieves state-of-the-art performance for pedestrian detection on various datasets.
Towards 3D Scene Understanding by Referring Synthetic Models
Mar 20, 2022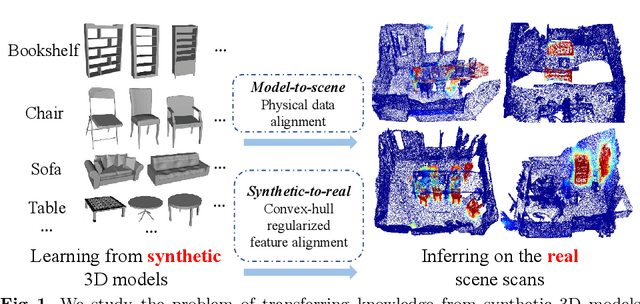
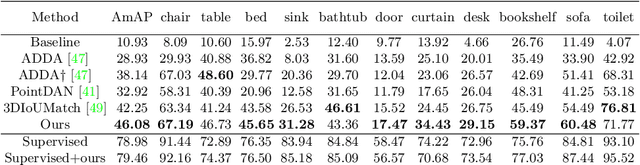
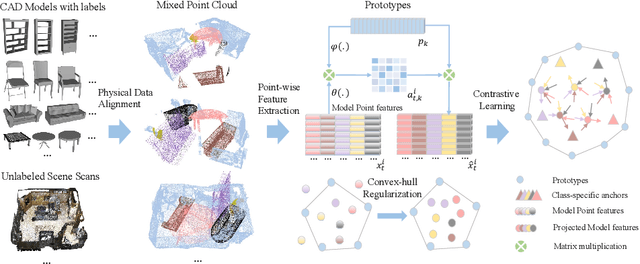
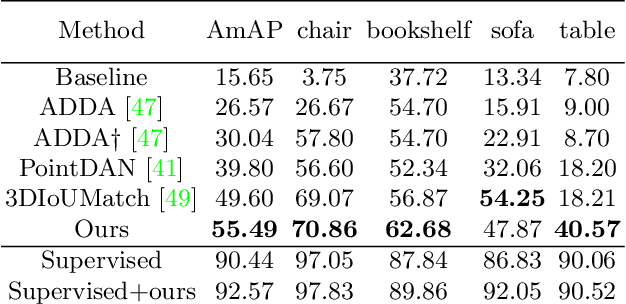
Promising performance has been achieved for visual perception on the point cloud. However, the current methods typically rely on labour-extensive annotations on the scene scans. In this paper, we explore how synthetic models alleviate the real scene annotation burden, i.e., taking the labelled 3D synthetic models as reference for supervision, the neural network aims to recognize specific categories of objects on a real scene scan (without scene annotation for supervision). The problem studies how to transfer knowledge from synthetic 3D models to real 3D scenes and is named Referring Transfer Learning (RTL). The main challenge is solving the model-to-scene (from a single model to the scene) and synthetic-to-real (from synthetic model to real scene's object) gap between the synthetic model and the real scene. To this end, we propose a simple yet effective framework to perform two alignment operations. First, physical data alignment aims to make the synthetic models cover the diversity of the scene's objects with data processing techniques. Then a novel \textbf{convex-hull regularized feature alignment} introduces learnable prototypes to project the point features of both synthetic models and real scenes to a unified feature space, which alleviates the domain gap. These operations ease the model-to-scene and synthetic-to-real difficulty for a network to recognize the target objects on a real unseen scene. Experiments show that our method achieves the average mAP of 46.08\% and 55.49\% on the ScanNet and S3DIS datasets by learning the synthetic models from the ModelNet dataset. Code will be publicly available.
An Intelligent Self-driving Truck System For Highway Transportation
Dec 31, 2021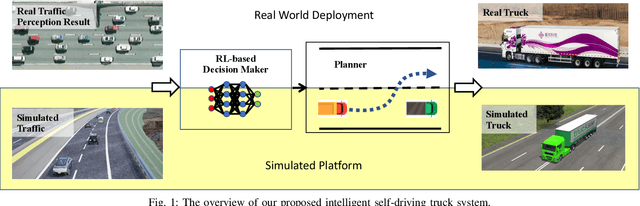
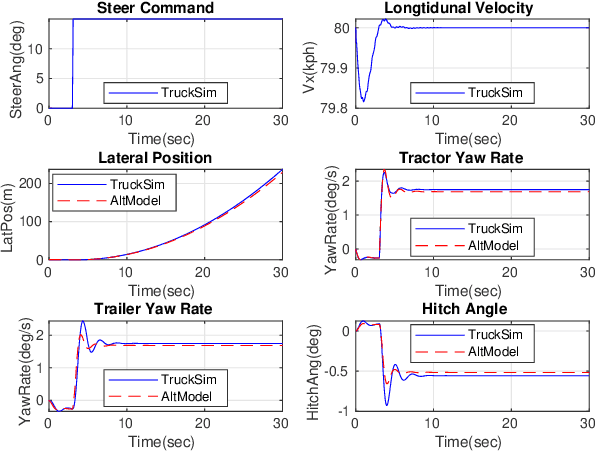
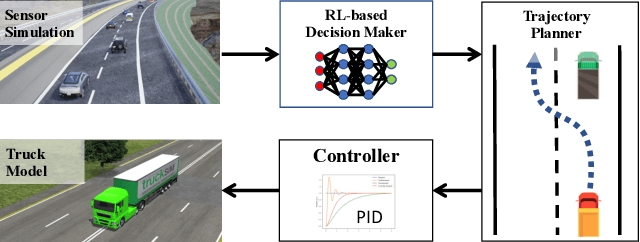
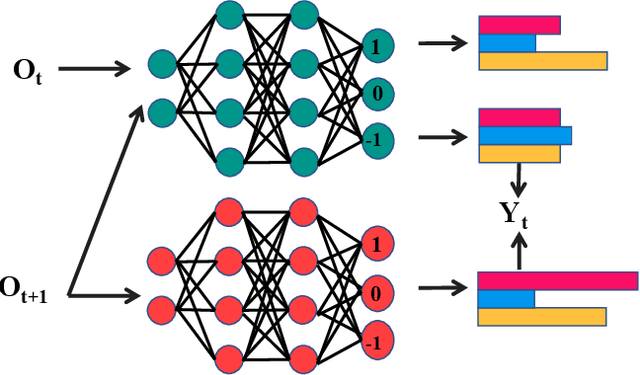
Recently, there have been many advances in autonomous driving society, attracting a lot of attention from academia and industry. However, existing works mainly focus on cars, extra development is still required for self-driving truck algorithms and models. In this paper, we introduce an intelligent self-driving truck system. Our presented system consists of three main components, 1) a realistic traffic simulation module for generating realistic traffic flow in testing scenarios, 2) a high-fidelity truck model which is designed and evaluated for mimicking real truck response in real-world deployment, 3) an intelligent planning module with learning-based decision making algorithm and multi-mode trajectory planner, taking into account the truck's constraints, road slope changes, and the surrounding traffic flow. We provide quantitative evaluations for each component individually to demonstrate the fidelity and performance of each part. We also deploy our proposed system on a real truck and conduct real world experiments which shows our system's capacity of mitigating sim-to-real gap. Our code is available at https://github.com/InceptioResearch/IITS
FaceScape: 3D Facial Dataset and Benchmark for Single-View 3D Face Reconstruction
Nov 01, 2021
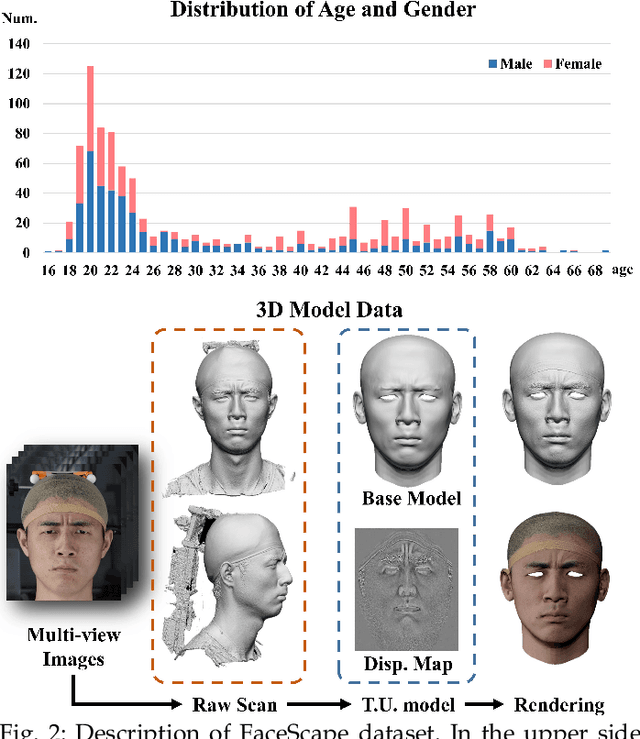
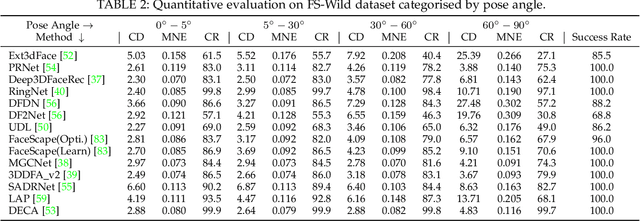
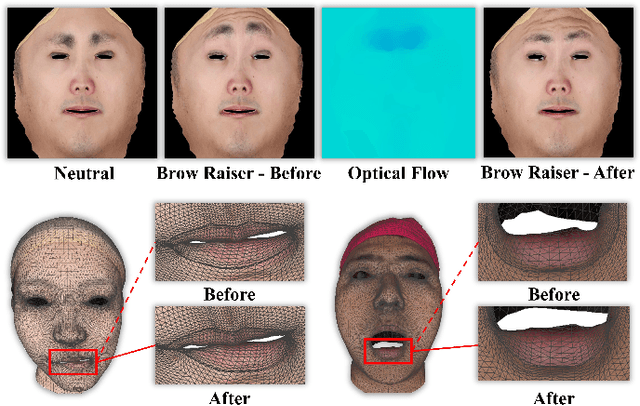
In this paper, we present a large-scale detailed 3D face dataset, FaceScape, and the corresponding benchmark to evaluate single-view facial 3D reconstruction. By training on FaceScape data, a novel algorithm is proposed to predict elaborate riggable 3D face models from a single image input. FaceScape dataset provides 18,760 textured 3D faces, captured from 938 subjects and each with 20 specific expressions. The 3D models contain the pore-level facial geometry that is also processed to be topologically uniformed. These fine 3D facial models can be represented as a 3D morphable model for rough shapes and displacement maps for detailed geometry. Taking advantage of the large-scale and high-accuracy dataset, a novel algorithm is further proposed to learn the expression-specific dynamic details using a deep neural network. The learned relationship serves as the foundation of our 3D face prediction system from a single image input. Different than the previous methods, our predicted 3D models are riggable with highly detailed geometry under different expressions. We also use FaceScape data to generate the in-the-wild and in-the-lab benchmark to evaluate recent methods of single-view face reconstruction. The accuracy is reported and analyzed on the dimensions of camera pose and focal length, which provides a faithful and comprehensive evaluation and reveals new challenges. The unprecedented dataset, benchmark, and code have been released to the public for research purpose.
Cylindrical and Asymmetrical 3D Convolution Networks for LiDAR-based Perception
Sep 12, 2021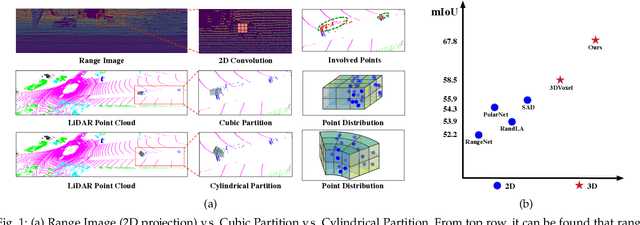
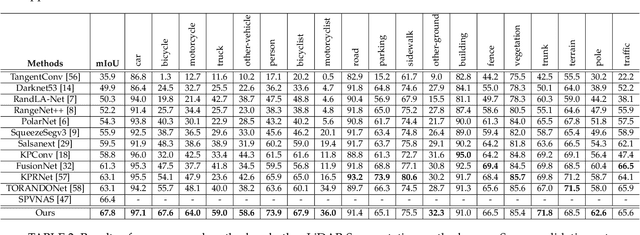
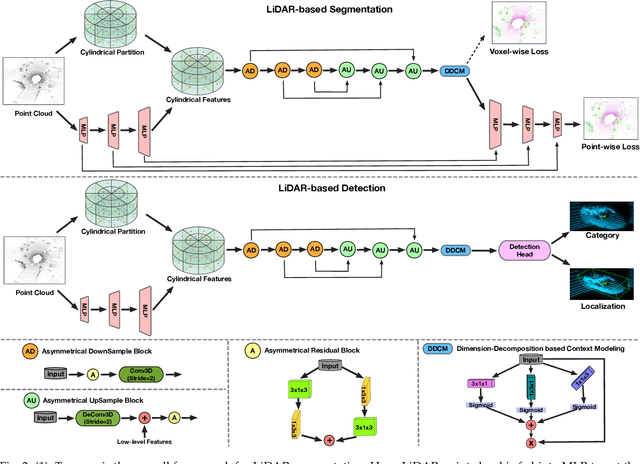
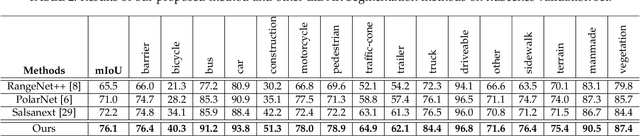
State-of-the-art methods for driving-scene LiDAR-based perception (including point cloud semantic segmentation, panoptic segmentation and 3D detection, \etc) often project the point clouds to 2D space and then process them via 2D convolution. Although this cooperation shows the competitiveness in the point cloud, it inevitably alters and abandons the 3D topology and geometric relations. A natural remedy is to utilize the 3D voxelization and 3D convolution network. However, we found that in the outdoor point cloud, the improvement obtained in this way is quite limited. An important reason is the property of the outdoor point cloud, namely sparsity and varying density. Motivated by this investigation, we propose a new framework for the outdoor LiDAR segmentation, where cylindrical partition and asymmetrical 3D convolution networks are designed to explore the 3D geometric pattern while maintaining these inherent properties. The proposed model acts as a backbone and the learned features from this model can be used for downstream tasks such as point cloud semantic and panoptic segmentation or 3D detection. In this paper, we benchmark our model on these three tasks. For semantic segmentation, we evaluate the proposed model on several large-scale datasets, \ie, SemanticKITTI, nuScenes and A2D2. Our method achieves the state-of-the-art on the leaderboard of SemanticKITTI (both single-scan and multi-scan challenge), and significantly outperforms existing methods on nuScenes and A2D2 dataset. Furthermore, the proposed 3D framework also shows strong performance and good generalization on LiDAR panoptic segmentation and LiDAR 3D detection.