 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2021 Multi-modal Aerial View Object Classification Challenge
Jul 02, 2021
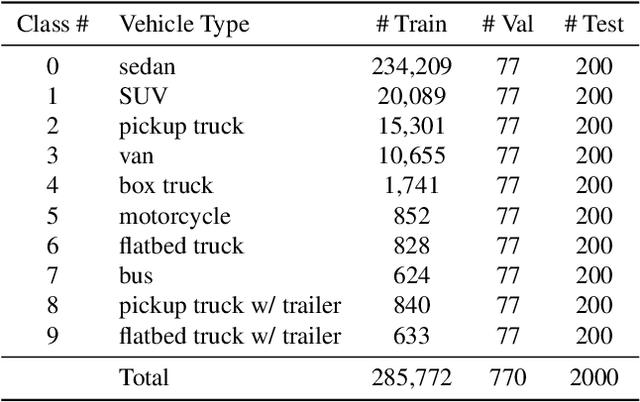
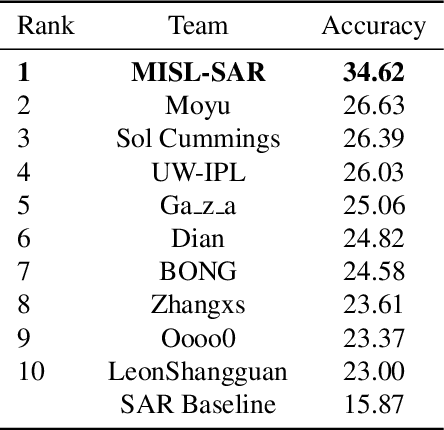
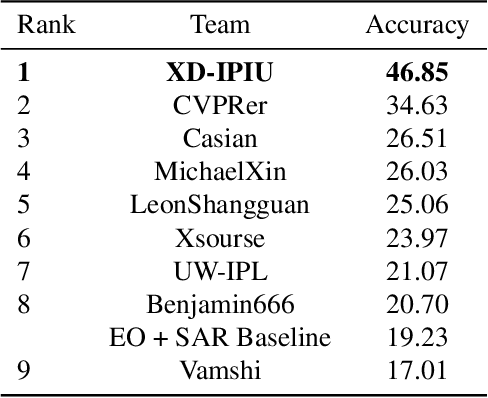
In this paper, we introduce the first Challenge on Multi-modal Aerial View Object Classification (MAVOC) in conjunction with the NTIRE 2021 workshop at CVPR. This challenge is composed of two different tracks using EO andSAR imagery. Both EO and SAR sensors possess different advantages and drawbacks. The purpose of this competition is to analyze how to use both sets of sensory information in complementary ways. We discuss the top methods submitted for this competition and evaluate their results on our blind test set. Our challenge results show significant improvement of more than 15% accuracy from our current baselines for each track of the competition
* 10 pages, 1 figure. Conference on Computer Vision and Pattern Recognition
Generative Flows with Invertible Attentions
Jun 26, 2021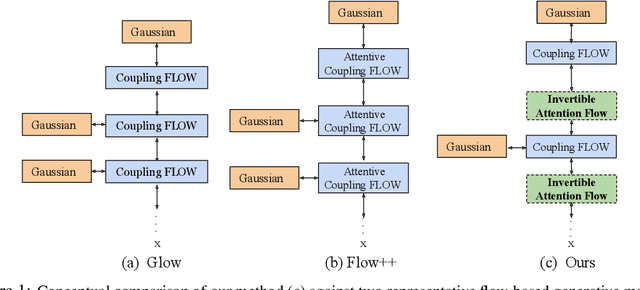
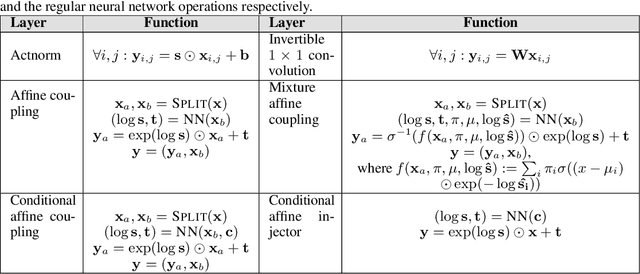
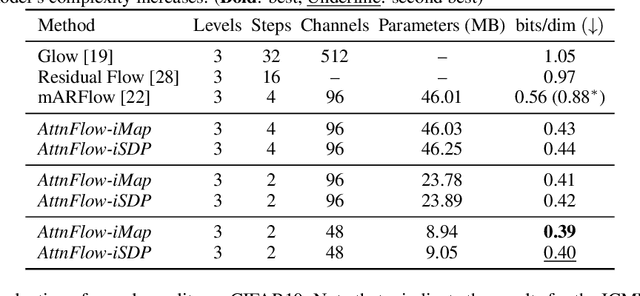
Flow-based generative models have shown excellent ability to explicitly learn the probability density function of data via a sequence of invertible transformations. Yet, modeling long-range dependencies over normalizing flows remains understudied. To fill the gap, in this paper, we introduce two types of invertible attention mechanisms for generative flow models. To be precise, we propose map-based and scaled dot-product attention for unconditional and conditional generative flow models. The key idea is to exploit split-based attention mechanisms to learn the attention weights and input representations on every two splits of flow feature maps. Our method provides invertible attention modules with tractable Jacobian determinants, enabling seamless integration of it at any positions of the flow-based models. The proposed attention mechanism can model the global data dependencies, leading to more comprehensive flow models. Evaluation on multiple generation tasks demonstrates that the introduced attention flow idea results in efficient flow models and compares favorably against the state-of-the-art unconditional and conditional generative flow methods.
NTIRE 2021 Challenge on Burst Super-Resolution: Methods and Results
Jun 07, 2021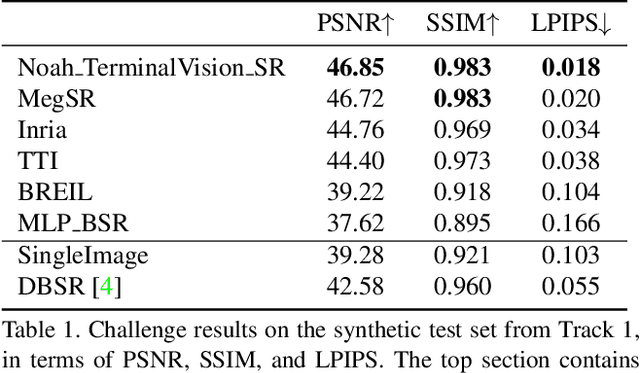

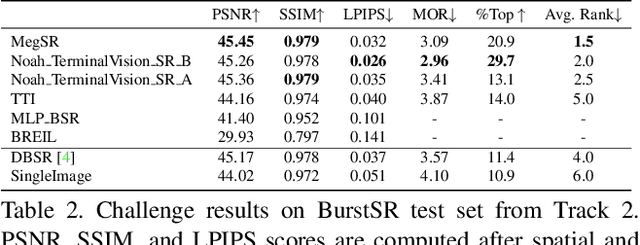

This paper reviews the NTIRE2021 challenge on burst super-resolution. Given a RAW noisy burst as input, the task in the challenge was to generate a clean RGB image with 4 times higher resolution. The challenge contained two tracks; Track 1 evaluating on synthetically generated data, and Track 2 using real-world bursts from mobile camera. In the final testing phase, 6 teams submitted results using a diverse set of solutions. The top-performing methods set a new state-of-the-art for the burst super-resolution task.
NTIRE 2021 Challenge on High Dynamic Range Imaging: Dataset, Methods and Results
Jun 02, 2021
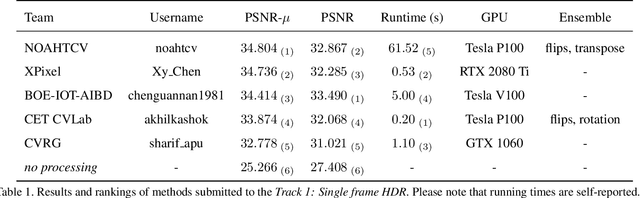
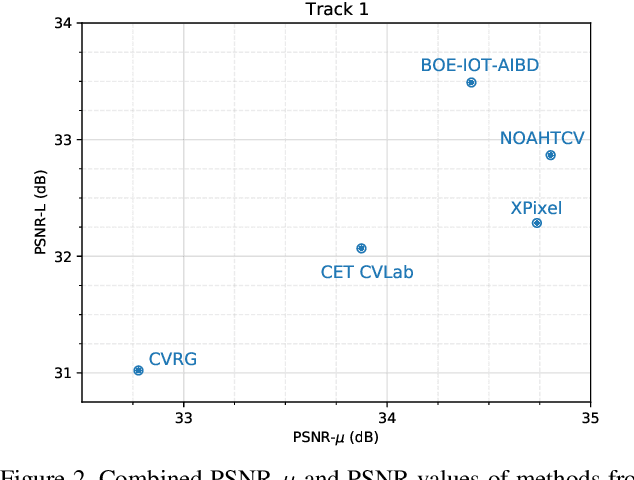
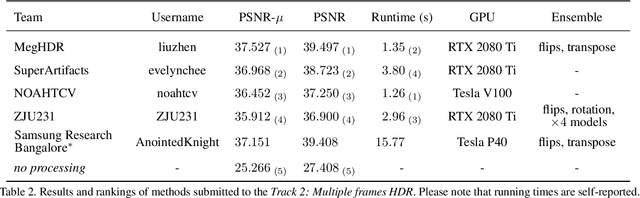
This paper reviews the first challenge on high-dynamic range (HDR) imaging that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2021. This manuscript focuses on the newly introduced dataset, the proposed methods and their results. The challenge aims at estimating a HDR image from one or multiple respective low-dynamic range (LDR) observations, which might suffer from under- or over-exposed regions and different sources of noise. The challenge is composed by two tracks: In Track 1 only a single LDR image is provided as input, whereas in Track 2 three differently-exposed LDR images with inter-frame motion are available. In both tracks, the ultimate goal is to achieve the best objective HDR reconstruction in terms of PSNR with respect to a ground-truth image, evaluated both directly and with a canonical tonemapping operation.
Fourier Space Losses for Efficient Perceptual Image Super-Resolution
Jun 01, 2021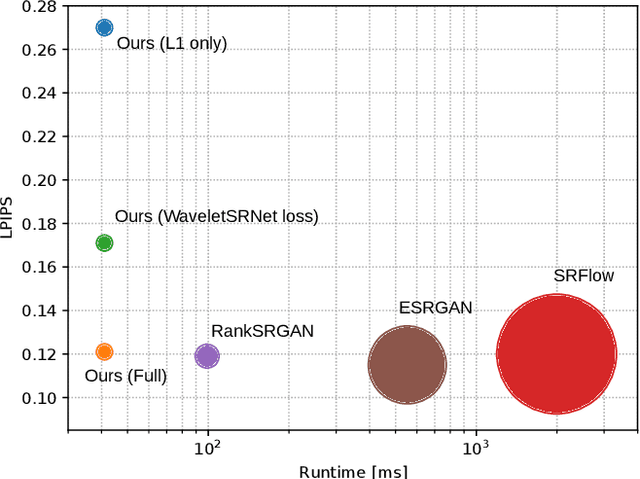

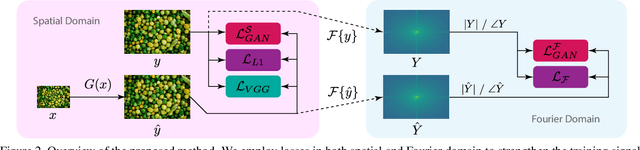
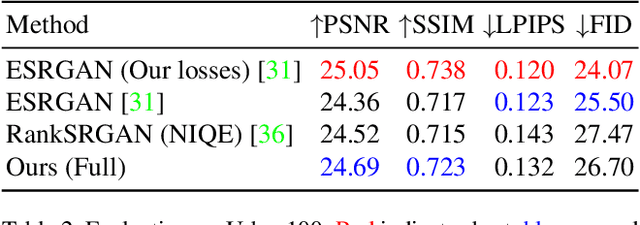
Many super-resolution (SR) models are optimized for high performance only and therefore lack efficiency due to large model complexity. As large models are often not practical in real-world applications, we investigate and propose novel loss functions, to enable SR with high perceptual quality from much more efficient models. The representative power for a given low-complexity generator network can only be fully leveraged by strong guidance towards the optimal set of parameters. We show that it is possible to improve the performance of a recently introduced efficient generator architecture solely with the application of our proposed loss functions. In particular, we use a Fourier space supervision loss for improved restoration of missing high-frequency (HF) content from the ground truth image and design a discriminator architecture working directly in the Fourier domain to better match the target HF distribution. We show that our losses' direct emphasis on the frequencies in Fourier-space significantly boosts the perceptual image quality, while at the same time retaining high restoration quality in comparison to previously proposed loss functions for this task. The performance is further improved by utilizing a combination of spatial and frequency domain losses, as both representations provide complementary information during training. On top of that, the trained generator achieves comparable results with and is 2.4x and 48x faster than state-of-the-art perceptual SR methods RankSRGAN and SRFlow respectively.
Fast and Accurate Camera Scene Detection on Smartphones
May 17, 2021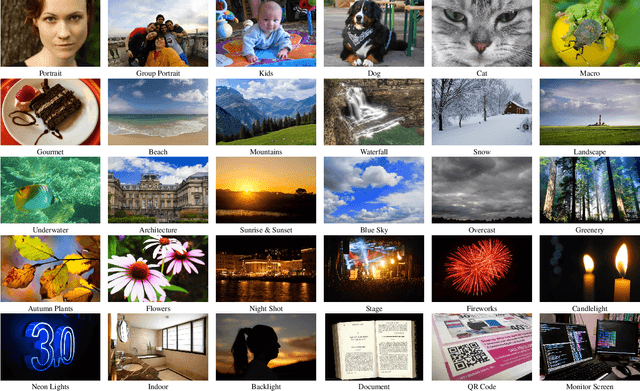
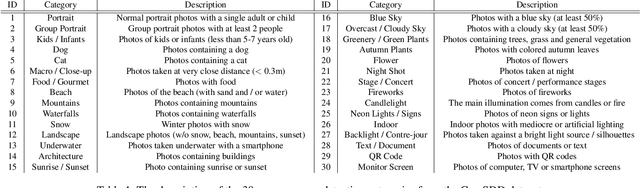

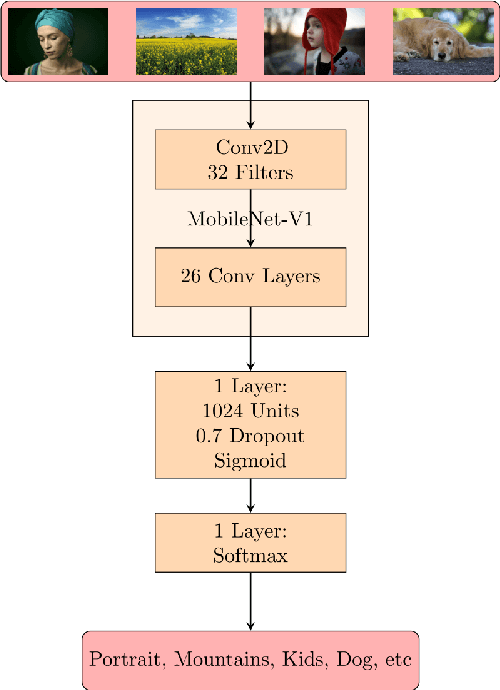
AI-powered automatic camera scene detection mode is nowadays available in nearly any modern smartphone, though the problem of accurate scene prediction has not yet been addressed by the research community. This paper for the first time carefully defines this problem and proposes a novel Camera Scene Detection Dataset (CamSDD) containing more than 11K manually crawled images belonging to 30 different scene categories. We propose an efficient and NPU-friendly CNN model for this task that demonstrates a top-3 accuracy of 99.5% on this dataset and achieves more than 200 FPS on the recent mobile SoCs. An additional in-the-wild evaluation of the obtained solution is performed to analyze its performance and limitation in the real-world scenarios. The dataset and pre-trained models used in this paper are available on the project website.
Fast and Accurate Quantized Camera Scene Detection on Smartphones, Mobile AI 2021 Challenge: Report
May 17, 2021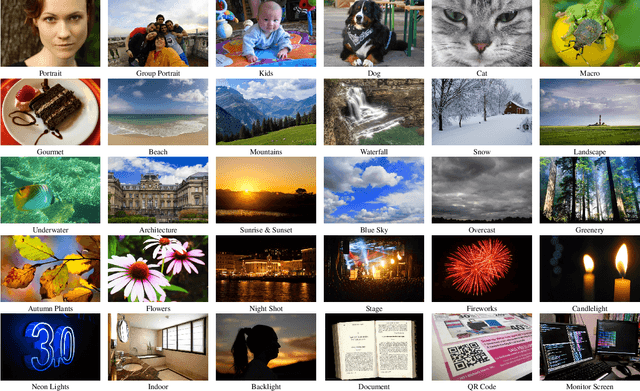
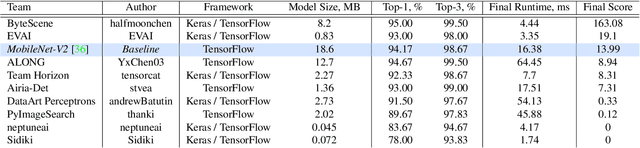

Camera scene detection is among the most popular computer vision problem on smartphones. While many custom solutions were developed for this task by phone vendors, none of the designed models were available publicly up until now. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop quantized deep learning-based camera scene classification solutions that can demonstrate a real-time performance on smartphones and IoT platforms. For this, the participants were provided with a large-scale CamSDD dataset consisting of more than 11K images belonging to the 30 most important scene categories. The runtime of all models was evaluated on the popular Apple Bionic A11 platform that can be found in many iOS devices. The proposed solutions are fully compatible with all major mobile AI accelerators and can demonstrate more than 100-200 FPS on the majority of recent smartphone platforms while achieving a top-3 accuracy of more than 98%. A detailed description of all models developed in the challenge is provided in this paper.
Fast and Accurate Single-Image Depth Estimation on Mobile Devices, Mobile AI 2021 Challenge: Report
May 17, 2021


Depth estimation is an important computer vision problem with many practical applications to mobile devices. While many solutions have been proposed for this task, they are usually very computationally expensive and thus are not applicable for on-device inference. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based depth estimation solutions that can demonstrate a nearly real-time performance on smartphones and IoT platforms. For this, the participants were provided with a new large-scale dataset containing RGB-depth image pairs obtained with a dedicated stereo ZED camera producing high-resolution depth maps for objects located at up to 50 meters. The runtime of all models was evaluated on the popular Raspberry Pi 4 platform with a mobile ARM-based Broadcom chipset. The proposed solutions can generate VGA resolution depth maps at up to 10 FPS on the Raspberry Pi 4 while achieving high fidelity results, and are compatible with any Android or Linux-based mobile devices. A detailed description of all models developed in the challenge is provided in this paper.
Real-Time Video Super-Resolution on Smartphones with Deep Learning, Mobile AI 2021 Challenge: Report
May 17, 2021

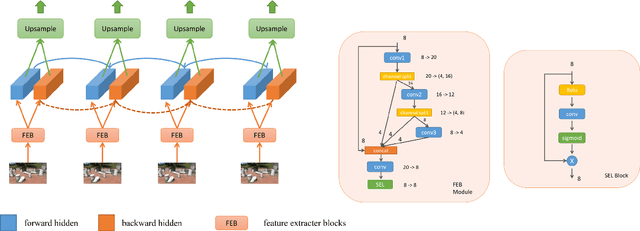
Video super-resolution has recently become one of the most important mobile-related problems due to the rise of video communication and streaming services. While many solutions have been proposed for this task, the majority of them are too computationally expensive to run on portable devices with limited hardware resources. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based video super-resolution solutions that can achieve a real-time performance on mobile GPUs. The participants were provided with the REDS dataset and trained their models to do an efficient 4X video upscaling. The runtime of all models was evaluated on the OPPO Find X2 smartphone with the Snapdragon 865 SoC capable of accelerating floating-point networks on its Adreno GPU. The proposed solutions are fully compatible with any mobile GPU and can upscale videos to HD resolution at up to 80 FPS while demonstrating high fidelity results. A detailed description of all models developed in the challenge is provided in this paper.
Real-Time Quantized Image Super-Resolution on Mobile NPUs, Mobile AI 2021 Challenge: Report
May 17, 2021
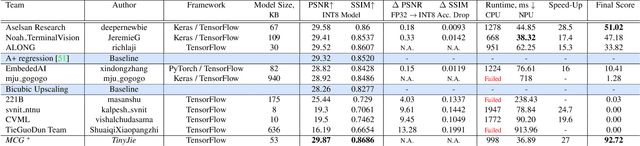
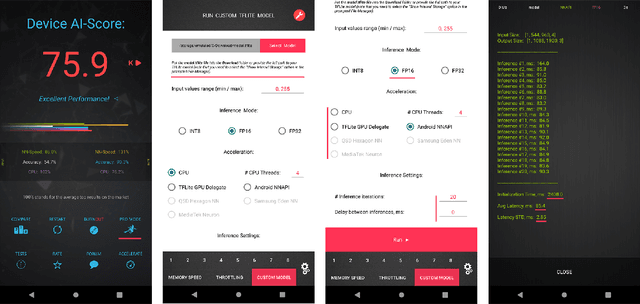
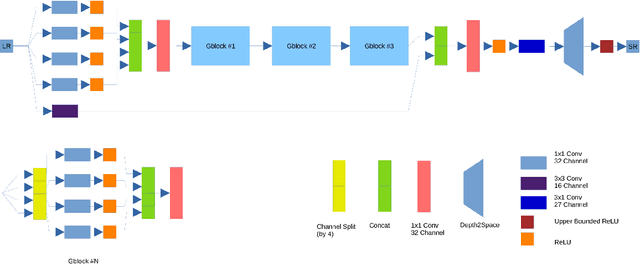
Image super-resolution is one of the most popular computer vision problems with many important applications to mobile devices. While many solutions have been proposed for this task, they are usually not optimized even for common smartphone AI hardware, not to mention more constrained smart TV platforms that are often supporting INT8 inference only. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based image super-resolution solutions that can demonstrate a real-time performance on mobile or edge NPUs. For this, the participants were provided with the DIV2K dataset and trained quantized models to do an efficient 3X image upscaling. The runtime of all models was evaluated on the Synaptics VS680 Smart Home board with a dedicated NPU capable of accelerating quantized neural networks. The proposed solutions are fully compatible with all major mobile AI accelerators and are capable of reconstructing Full HD images under 40-60 ms while achieving high fidelity results. A detailed description of all models developed in the challenge is provided in this paper.