 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWidening and Squeezing: Towards Accurate and Efficient QNNs
Feb 12, 2020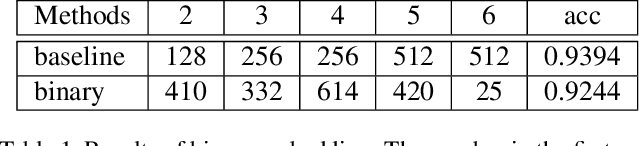
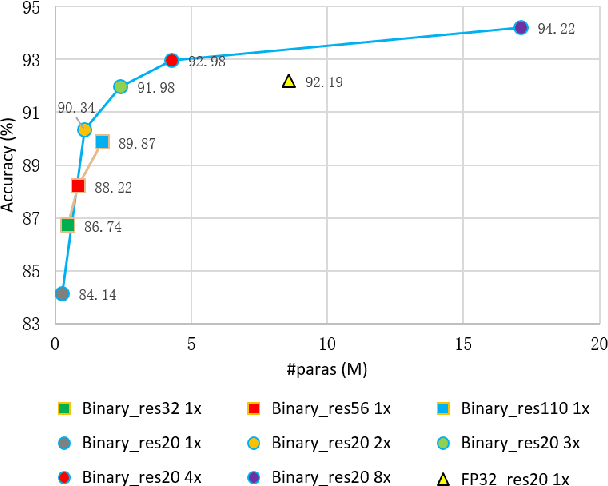
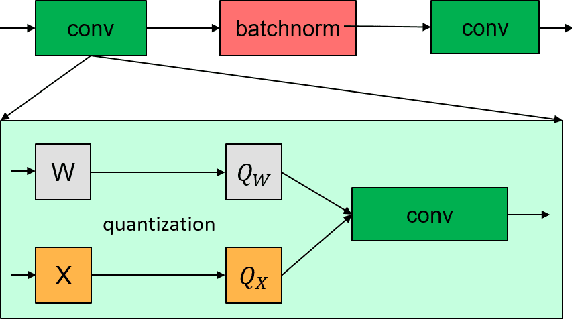
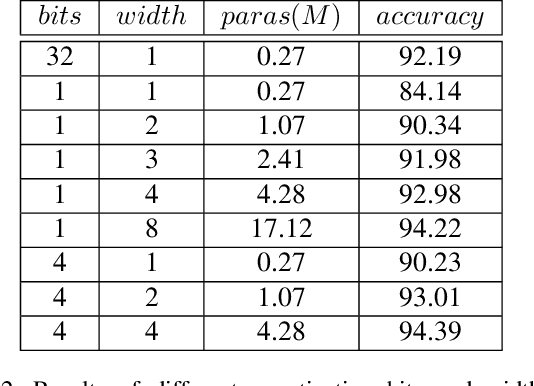
Quantization neural networks (QNNs) are very attractive to the industry because their extremely cheap calculation and storage overhead, but their performance is still worse than that of networks with full-precision parameters. Most of existing methods aim to enhance performance of QNNs especially binary neural networks by exploiting more effective training techniques. However, we find the representation capability of quantization features is far weaker than full-precision features by experiments. We address this problem by projecting features in original full-precision networks to high-dimensional quantization features. Simultaneously, redundant quantization features will be eliminated in order to avoid unrestricted growth of dimensions for some datasets. Then, a compact quantization neural network but with sufficient representation ability will be established. Experimental results on benchmark datasets demonstrate that the proposed method is able to establish QNNs with much less parameters and calculations but almost the same performance as that of full-precision baseline models, e.g. $29.9\%$ top-1 error of binary ResNet-18 on the ImageNet ILSVRC 2012 dataset.
Disassembling the Dataset: A Camera Alignment Mechanism for Multiple Tasks in Person Re-identification
Jan 23, 2020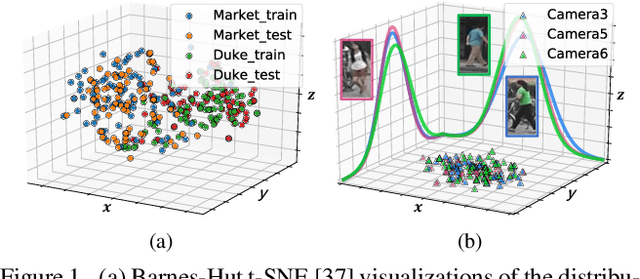
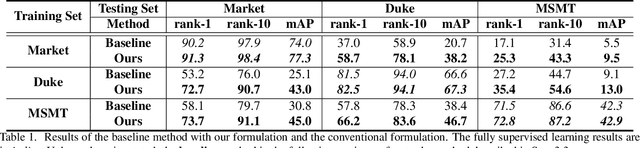
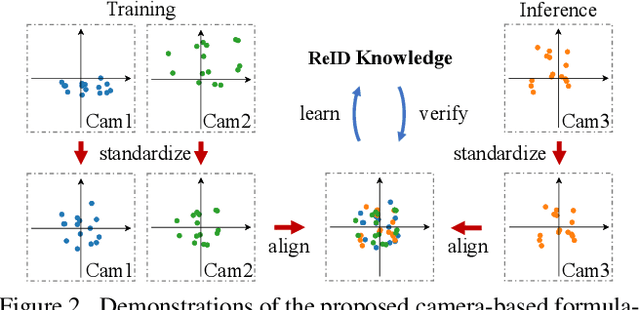
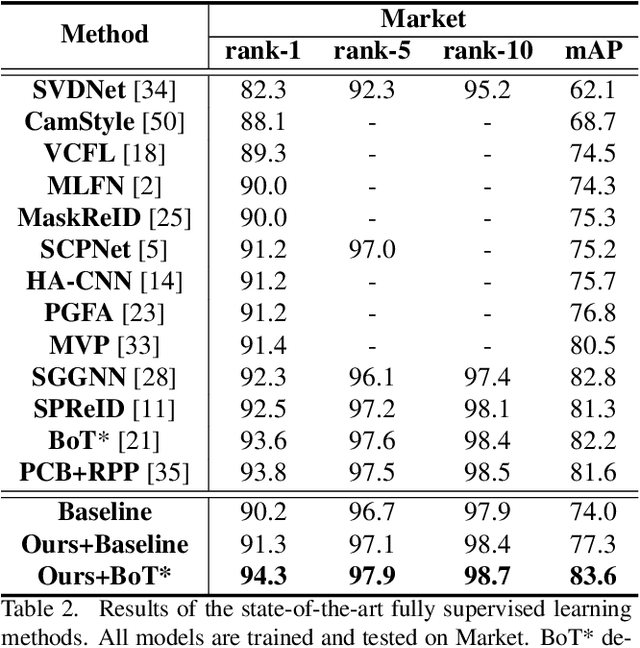
In person re-identification (ReID), one of the main challenges is the distribution inconsistency among different datasets. Previous researchers have defined several seemingly individual topics, such as fully supervised learning, direct transfer, domain adaptation, and incremental learning, each with different settings of training and testing scenarios. These topics are designed in a dataset-wise manner, i.e., images from the same dataset, even from disjoint cameras, are presumed to follow the same distribution. However, such distribution is coarse and training-set-specific, and the ReID knowledge learned in such manner works well only on the corresponding scenarios. To address this issue, we propose a fine-grained distribution alignment formulation, which disassembles the dataset and aligns all training and testing cameras. It connects all topics above and guarantees that ReID knowledge is always learned, accumulated, and verified in the aligned distributions. In practice, we devise the Camera-based Batch Normalization, which is easy for integration and nearly cost-free for existing ReID methods. Extensive experiments on the above four ReID tasks demonstrate the superiority of our approach. The code will be publicly available.
Filter Sketch for Network Pruning
Jan 23, 2020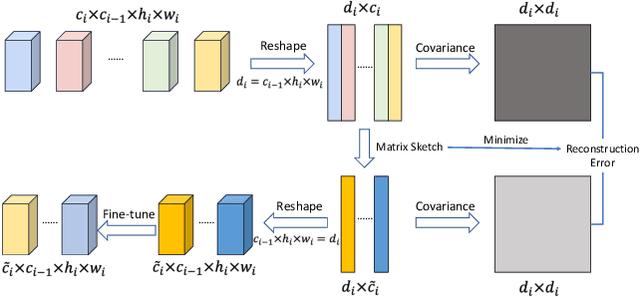
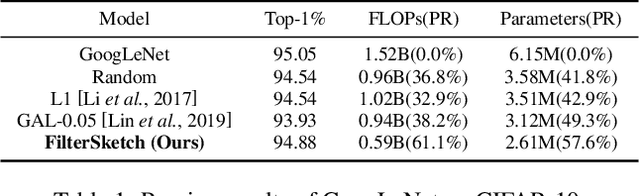
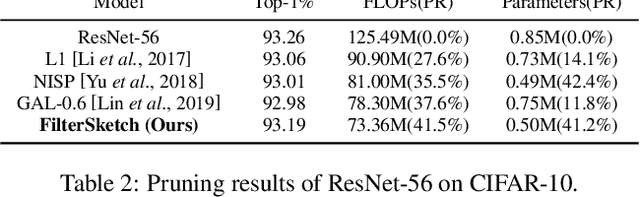
In this paper, we propose a novel network pruning approach by information preserving of pre-trained network weights (filters). Our approach, referred to as FilterSketch, encodes the second-order information of pre-trained weights, through which the model performance is recovered by fine-tuning the pruned network in an end-to-end manner. Network pruning with information preserving can be approximated as a matrix sketch problem, which is efficiently solved by the off-the-shelf Frequent Direction method. FilterSketch thereby requires neither training from scratch nor data-driven iterative optimization, leading to a magnitude-order reduction of time consumption in the optimization of pruning. Experiments on CIFAR-10 show that FilterSketch reduces 63.3% of FLOPs and prunes 59.9% of network parameters with negligible accuracy cost overhead for ResNet-110. On ILSVRC-2012, it achieves a reduction of 45.5% FLOPs and removes 43.0% of parameters with only a small top-5 accuracy drop of 0.69% for ResNet-50. Source codes of the proposed FilterSketch can be available at https://github.com/lmbxmu/FilterSketch.
Latency-Aware Differentiable Neural Architecture Search
Jan 17, 2020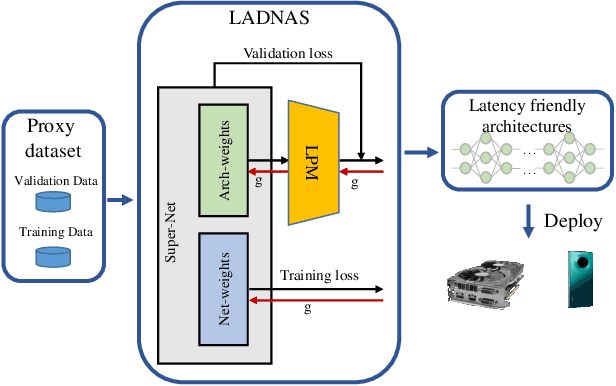

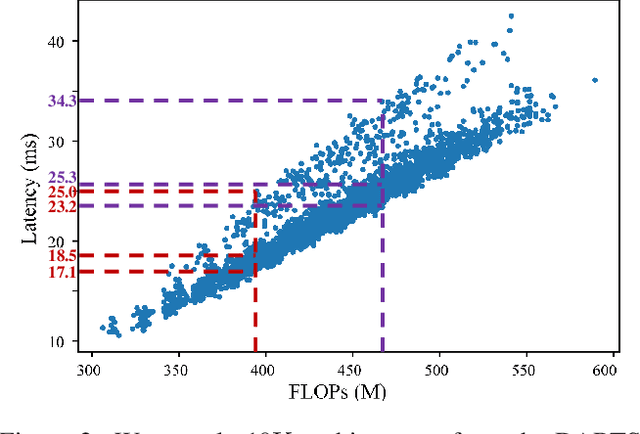
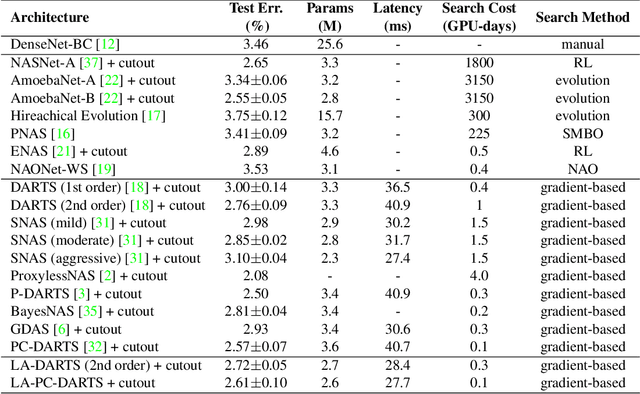
Differentiable neural architecture search methods became popular in automated machine learning, mainly due to their low search costs and flexibility in designing the search space. However, these methods suffer the difficulty in optimizing network, so that the searched network is often unfriendly to hardware. This paper deals with this problem by adding a differentiable latency loss term into optimization, so that the search process can tradeoff between accuracy and latency with a balancing coefficient. The core of latency prediction is to encode each network architecture and feed it into a multi-layer regressor, with the training data being collected from randomly sampling a number of architectures and evaluating them on the hardware. We evaluate our approach on NVIDIA Tesla-P100 GPUs. With 100K sampled architectures (requiring a few hours), the latency prediction module arrives at a relative error of lower than 10\%. Equipped with this module, the search method can reduce the latency by 20% meanwhile preserving the accuracy. Our approach also enjoys the ability of being transplanted to a wide range of hardware platforms with very few efforts, or being used to optimizing other non-differentiable factors such as power consumption.
AdderNet: Do We Really Need Multiplications in Deep Learning?
Jan 09, 2020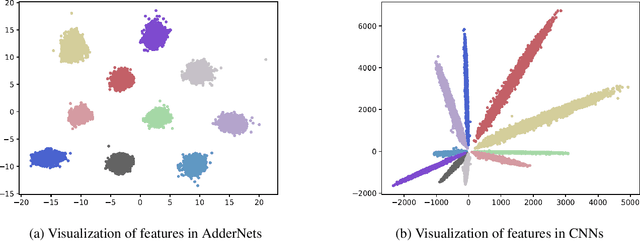
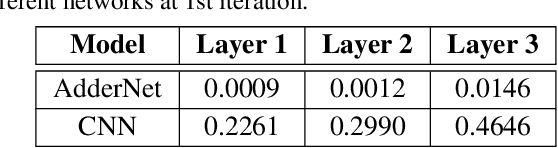
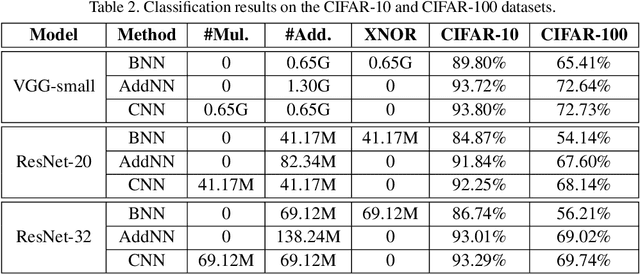
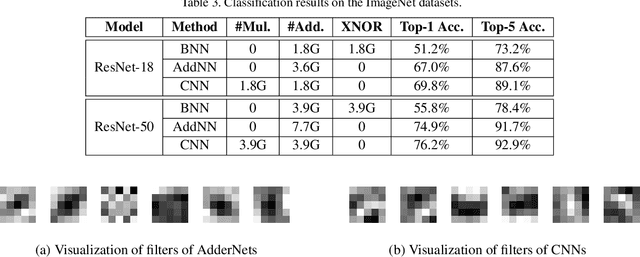
Compared with cheap addition operation, multiplication operation is of much higher computation complexity. The widely-used convolutions in deep neural networks are exactly cross-correlation to measure the similarity between input feature and convolution filters, which involves massive multiplications between float values. In this paper, we present adder networks (AdderNets) to trade these massive multiplications in deep neural networks, especially convolutional neural networks (CNNs), for much cheaper additions to reduce computation costs. In AdderNets, we take the $\ell_1$-norm distance between filters and input feature as the output response. The influence of this new similarity measure on the optimization of neural network have been thoroughly analyzed. To achieve a better performance, we develop a special back-propagation approach for AdderNets by investigating the full-precision gradient. We then propose an adaptive learning rate strategy to enhance the training procedure of AdderNets according to the magnitude of each neuron's gradient. As a result, the proposed AdderNets can achieve 74.9% Top-1 accuracy 91.7% Top-5 accuracy using ResNet-50 on the ImageNet dataset without any multiplication in convolution layer.
Progressive DARTS: Bridging the Optimization Gap for NAS in the Wild
Jan 06, 2020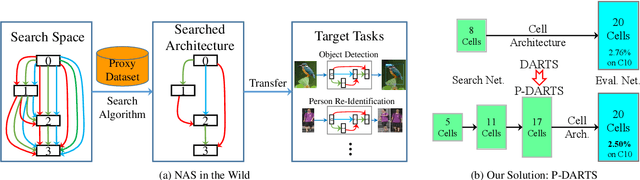
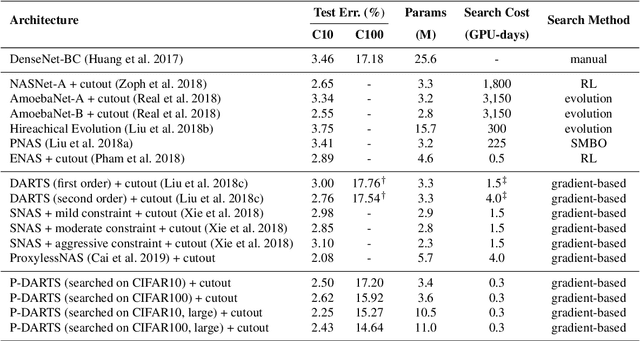
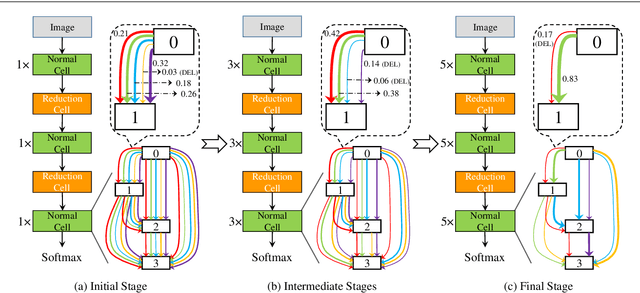
With the rapid development of neural architecture search (NAS), researchers found powerful network architectures for a wide range of vision tasks. However, it remains unclear if the searched architecture can transfer across different types of tasks as manually designed ones did. This paper puts forward this problem, referred to as NAS in the wild, which explores the possibility of finding the optimal architecture in a proxy dataset and then deploying it to mostly unseen scenarios. We instantiate this setting using a currently popular algorithm named differentiable architecture search (DARTS), which often suffers unsatisfying performance while being transferred across different tasks. We argue that the accuracy drop originates from the formulation that uses a super-network for search but a sub-network for re-training. The different properties of these stages have resulted in a significant optimization gap, and consequently, the architectural parameters "over-fit" the super-network. To alleviate the gap, we present a progressive method that gradually increases the network depth during the search stage, which leads to the Progressive DARTS (P-DARTS) algorithm. With a reduced search cost (7 hours on a single GPU), P-DARTS achieves improved performance on both the proxy dataset (CIFAR10) and a few target problems (ImageNet classification, COCO detection and three ReID benchmarks). Our code is available at \url{https://github.com/chenxin061/pdarts}.
Scalable NAS with Factorizable Architectural Parameters
Dec 31, 2019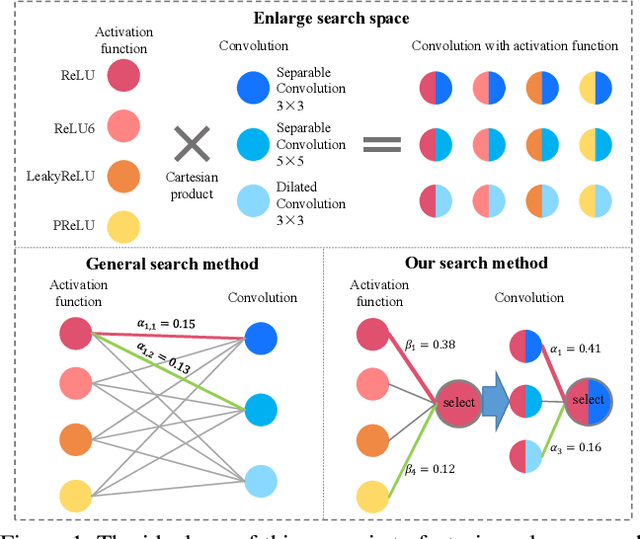
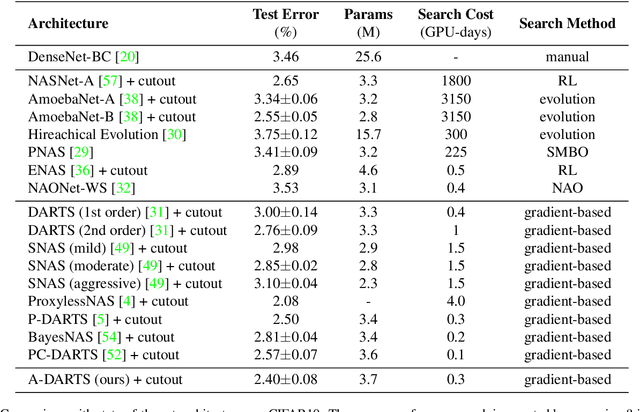
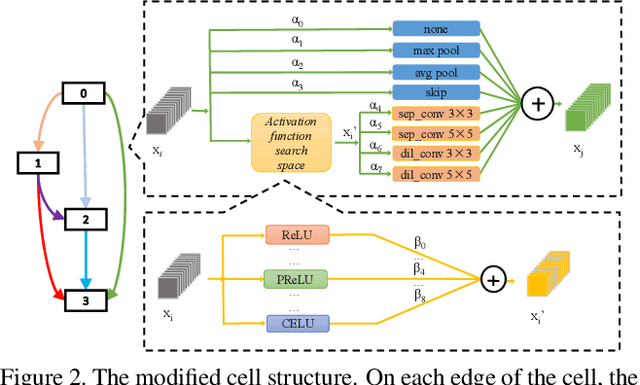
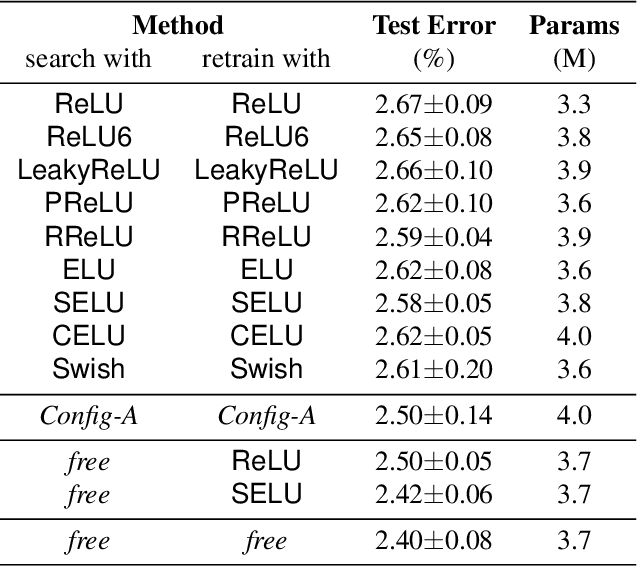
Neural architecture search (NAS) is an emerging topic in machine learning and computer vision. The fundamental ideology of NAS is using an automatic mechanism to replace manual designs for exploring powerful network architectures. One of the key factors of NAS is to scale-up the search space, e.g., increasing the number of operators, so that more possibilities are covered, but existing search algorithms often get lost in a large number of operators. This paper presents a scalable NAS algorithm by designing a factorizable set of architectural parameters, so that the size of the search space goes up quadratically while the burden of optimization increases linearly. As a practical example, we add a set of activation functions to the original set containing convolution, pooling and skip-connect, etc. With a marginal increase in search costs and no extra costs in retraining, we can find interesting architectures that were not explored before and achieve state-of-the-art performance in CIFAR10 and ImageNet, two standard image classification benchmarks.
Appending Adversarial Frames for Universal Video Attack
Dec 10, 2019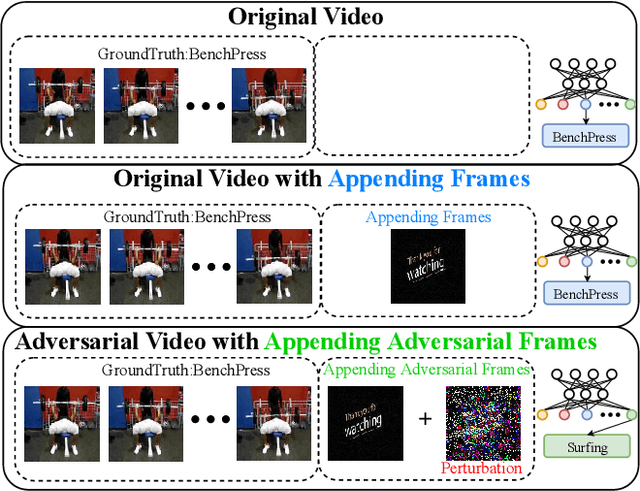
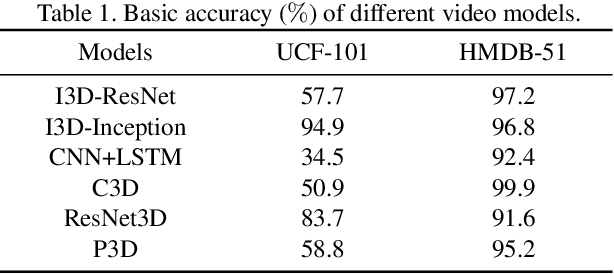
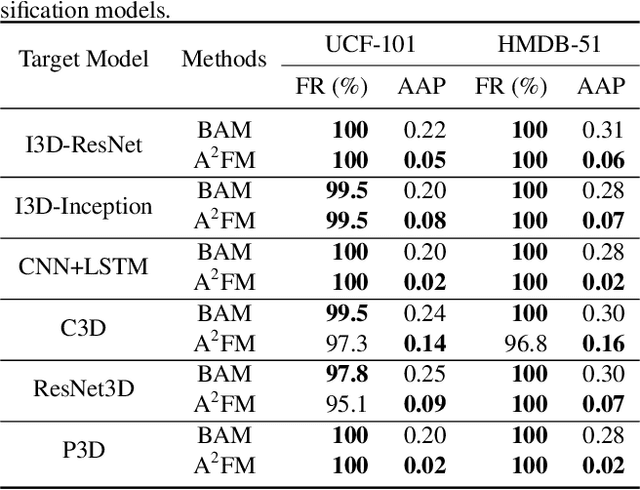
There have been many efforts in attacking image classification models with adversarial perturbations, but the same topic on video classification has not yet been thoroughly studied. This paper presents a novel idea of video-based attack, which appends a few dummy frames (e.g., containing the texts of `thanks for watching') to a video clip and then adds adversarial perturbations only on these new frames. Our approach enjoys three major benefits, namely, a high success rate, a low perceptibility, and a strong ability in transferring across different networks. These benefits mostly come from the common dummy frame which pushes all samples towards the boundary of classification. On the other hand, such attacks are easily to be concealed since most people would not notice the abnormality behind the perturbed video clips. We perform experiments on two popular datasets with six state-of-the-art video classification models, and demonstrate the effectiveness of our approach in the scenario of universal video attacks.
A Real-time Global Inference Network for One-stage Referring Expression Comprehension
Dec 07, 2019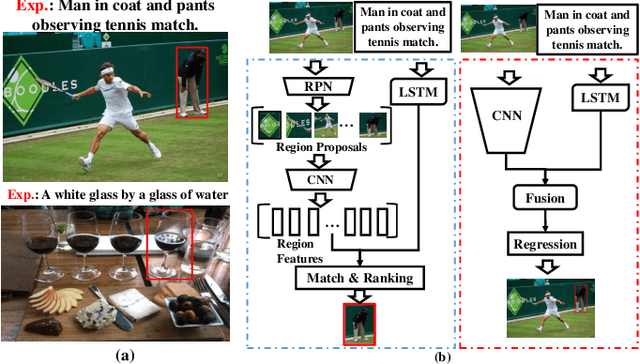
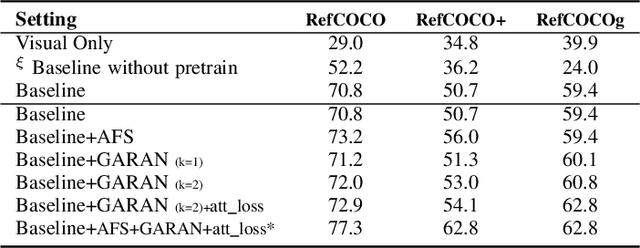
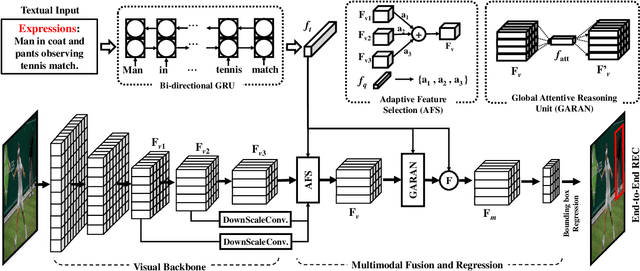

Referring Expression Comprehension (REC) is an emerging research spot in computer vision, which refers to detecting the target region in an image given an text description. Most existing REC methods follow a multi-stage pipeline, which are computationally expensive and greatly limit the application of REC. In this paper, we propose a one-stage model towards real-time REC, termed Real-time Global Inference Network (RealGIN). RealGIN addresses the diversity and complexity issues in REC with two innovative designs: the Adaptive Feature Selection (AFS) and the Global Attentive ReAsoNing unit (GARAN). AFS adaptively fuses features at different semantic levels to handle the varying content of expressions. GARAN uses the textual feature as a pivot to collect expression-related visual information from all regions, and thenselectively diffuse such information back to all regions, which provides sufficient context for modeling the complex linguistic conditions in expressions. On five benchmark datasets, i.e., RefCOCO, RefCOCO+, RefCOCOg, ReferIt and Flickr30k, the proposed RealGIN outperforms most prior works and achieves very competitive performances against the most advanced method, i.e., MAttNet. Most importantly, under the same hardware, RealGIN can boost the processing speed by about 10 times over the existing methods.
Adversarial Domain Adaptation with Domain Mixup
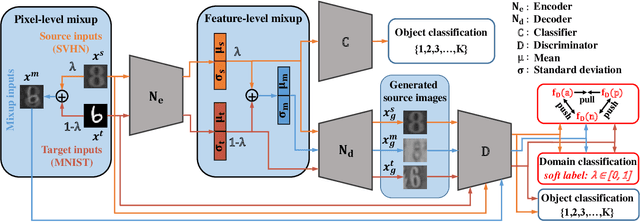
Dec 04, 2019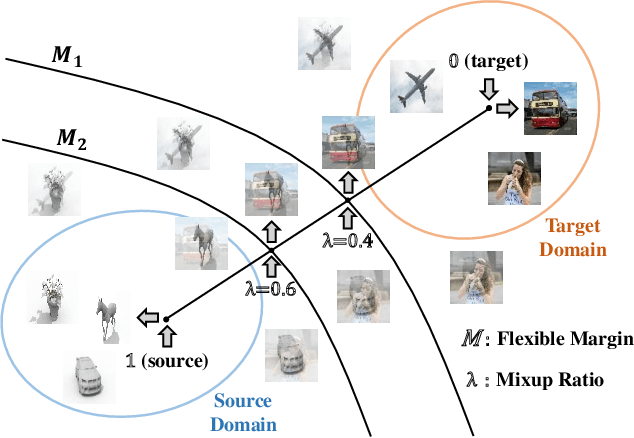
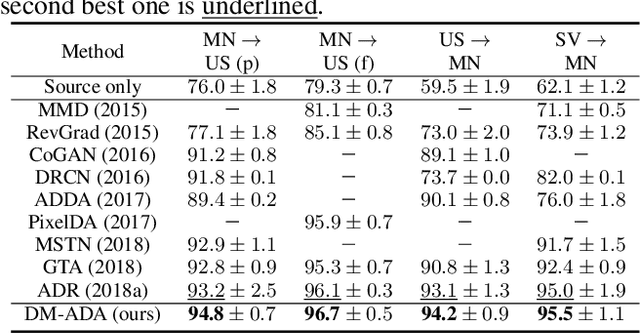

Recent works on domain adaptation reveal the effectiveness of adversarial learning on filling the discrepancy between source and target domains. However, two common limitations exist in current adversarial-learning-based methods. First, samples from two domains alone are not sufficient to ensure domain-invariance at most part of latent space. Second, the domain discriminator involved in these methods can only judge real or fake with the guidance of hard label, while it is more reasonable to use soft scores to evaluate the generated images or features, i.e., to fully utilize the inter-domain information. In this paper, we present adversarial domain adaptation with domain mixup (DM-ADA), which guarantees domain-invariance in a more continuous latent space and guides the domain discriminator in judging samples' difference relative to source and target domains. Domain mixup is jointly conducted on pixel and feature level to improve the robustness of models. Extensive experiments prove that the proposed approach can achieve superior performance on tasks with various degrees of domain shift and data complexity.