 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-Refined Dual Context-Aware Network for Partially Relevant Video Retrieval
Mar 25, 2026Retrieving partially relevant segments from untrimmed videos remains difficult due to two persistent challenges: the mismatch in information density between text and video segments, and limited attention mechanisms that overlook semantic focus and event correlations. We present KDC-Net, a Knowledge-Refined Dual Context-Aware Network that tackles these issues from both textual and visual perspectives. On the text side, a Hierarchical Semantic Aggregation module captures and adaptively fuses multi-scale phrase cues to enrich query semantics. On the video side, a Dynamic Temporal Attention mechanism employs relative positional encoding and adaptive temporal windows to highlight key events with local temporal coherence. Additionally, a dynamic CLIP-based distillation strategy, enhanced with temporal-continuity-aware refinement, ensures segment-aware and objective-aligned knowledge transfer. Experiments on PRVR benchmarks show that KDC-Net consistently outperforms state-of-the-art methods, especially under low moment-to-video ratios.
PersonalQ: Select, Quantize, and Serve Personalized Diffusion Models for Efficient Inference
Mar 24, 2026Personalized text-to-image generation lets users fine-tune diffusion models into repositories of concept-specific checkpoints, but serving these repositories efficiently is difficult for two reasons: natural-language requests are often ambiguous and can be misrouted to visually similar checkpoints, and standard post-training quantization can distort the fragile representations that encode personalized concepts. We present PersonalQ, a unified framework that connects checkpoint selection and quantization through a shared signal -- the checkpoint's trigger token. Check-in performs intent-aligned selection by combining intent-aware hybrid retrieval with LLM-based reranking over checkpoint context and asks a brief clarification question only when multiple intents remain plausible; it then rewrites the prompt by inserting the selected checkpoint's canonical trigger. Complementing this, Trigger-Aware Quantization (TAQ) applies trigger-aware mixed precision in cross-attention, preserving trigger-conditioned key/value rows (and their attention weights) while aggressively quantizing the remaining pathways for memory-efficient inference. Experiments show that PersonalQ improves intent alignment over retrieval and reranking baselines, while TAQ consistently offers a stronger compression-quality trade-off than prior diffusion PTQ methods, enabling scalable serving of personalized checkpoints without sacrificing fidelity.
A Human-Oriented Cooperative Driving Approach: Integrating Driving Intention, State, and Conflict
Dec 29, 2025Human-vehicle cooperative driving serves as a vital bridge to fully autonomous driving by improving driving flexibility and gradually building driver trust and acceptance of autonomous technology. To establish more natural and effective human-vehicle interaction, we propose a Human-Oriented Cooperative Driving (HOCD) approach that primarily minimizes human-machine conflict by prioritizing driver intention and state. In implementation, we take both tactical and operational levels into account to ensure seamless human-vehicle cooperation. At the tactical level, we design an intention-aware trajectory planning method, using intention consistency cost as the core metric to evaluate the trajectory and align it with driver intention. At the operational level, we develop a control authority allocation strategy based on reinforcement learning, optimizing the policy through a designed reward function to achieve consistency between driver state and authority allocation. The results of simulation and human-in-the-loop experiments demonstrate that our proposed approach not only aligns with driver intention in trajectory planning but also ensures a reasonable authority allocation. Compared to other cooperative driving approaches, the proposed HOCD approach significantly enhances driving performance and mitigates human-machine conflict.The code is available at https://github.com/i-Qin/HOCD.
PhysPatch: A Physically Realizable and Transferable Adversarial Patch Attack for Multimodal Large Language Models-based Autonomous Driving Systems
Aug 07, 2025

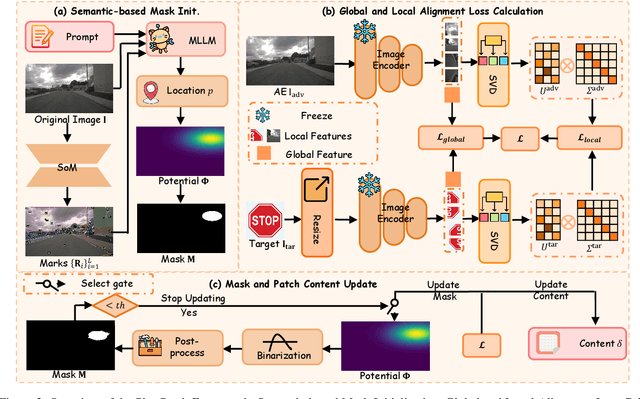

Multimodal Large Language Models (MLLMs) are becoming integral to autonomous driving (AD) systems due to their strong vision-language reasoning capabilities. However, MLLMs are vulnerable to adversarial attacks, particularly adversarial patch attacks, which can pose serious threats in real-world scenarios. Existing patch-based attack methods are primarily designed for object detection models and perform poorly when transferred to MLLM-based systems due to the latter's complex architectures and reasoning abilities. To address these limitations, we propose PhysPatch, a physically realizable and transferable adversarial patch framework tailored for MLLM-based AD systems. PhysPatch jointly optimizes patch location, shape, and content to enhance attack effectiveness and real-world applicability. It introduces a semantic-based mask initialization strategy for realistic placement, an SVD-based local alignment loss with patch-guided crop-resize to improve transferability, and a potential field-based mask refinement method. Extensive experiments across open-source, commercial, and reasoning-capable MLLMs demonstrate that PhysPatch significantly outperforms prior methods in steering MLLM-based AD systems toward target-aligned perception and planning outputs. Moreover, PhysPatch consistently places adversarial patches in physically feasible regions of AD scenes, ensuring strong real-world applicability and deployability.
Accelerate 3D Object Detection Models via Zero-Shot Attention Key Pruning
Mar 11, 2025



Query-based methods with dense features have demonstrated remarkable success in 3D object detection tasks. However, the computational demands of these models, particularly with large image sizes and multiple transformer layers, pose significant challenges for efficient running on edge devices. Existing pruning and distillation methods either need retraining or are designed for ViT models, which are hard to migrate to 3D detectors. To address this issue, we propose a zero-shot runtime pruning method for transformer decoders in 3D object detection models. The method, termed tgGBC (trim keys gradually Guided By Classification scores), systematically trims keys in transformer modules based on their importance. We expand the classification score to multiply it with the attention map to get the importance score of each key and then prune certain keys after each transformer layer according to their importance scores. Our method achieves a 1.99x speedup in the transformer decoder of the latest ToC3D model, with only a minimal performance loss of less than 1%. Interestingly, for certain models, our method even enhances their performance. Moreover, we deploy 3D detectors with tgGBC on an edge device, further validating the effectiveness of our method. The code can be found at https://github.com/iseri27/tg_gbc.
Redundant Queries in DETR-Based 3D Detection Methods: Unnecessary and Prunable
Dec 03, 2024



Query-based models are extensively used in 3D object detection tasks, with a wide range of pre-trained checkpoints readily available online. However, despite their popularity, these models often require an excessive number of object queries, far surpassing the actual number of objects to detect. The redundant queries result in unnecessary computational and memory costs. In this paper, we find that not all queries contribute equally -- a significant portion of queries have a much smaller impact compared to others. Based on this observation, we propose an embarrassingly simple approach called \bd{G}radually \bd{P}runing \bd{Q}ueries (GPQ), which prunes queries incrementally based on their classification scores. It is straightforward to implement in any query-based method, as it can be seamlessly integrated as a fine-tuning step using an existing checkpoint after training. With GPQ, users can easily generate multiple models with fewer queries, starting from a checkpoint with an excessive number of queries. Experiments on various advanced 3D detectors show that GPQ effectively reduces redundant queries while maintaining performance. Using our method, model inference on desktop GPUs can be accelerated by up to 1.31x. Moreover, after deployment on edge devices, it achieves up to a 67.86\% reduction in FLOPs and a 76.38\% decrease in inference time. The code will be available at \url{https://github.com/iseri27/Gpq}.
HeightMapNet: Explicit Height Modeling for End-to-End HD Map Learning
Nov 03, 2024



Recent advances in high-definition (HD) map construction from surround-view images have highlighted their cost-effectiveness in deployment. However, prevailing techniques often fall short in accurately extracting and utilizing road features, as well as in the implementation of view transformation. In response, we introduce HeightMapNet, a novel framework that establishes a dynamic relationship between image features and road surface height distributions. By integrating height priors, our approach refines the accuracy of Bird's-Eye-View (BEV) features beyond conventional methods. HeightMapNet also introduces a foreground-background separation network that sharply distinguishes between critical road elements and extraneous background components, enabling precise focus on detailed road micro-features. Additionally, our method leverages multi-scale features within the BEV space, optimally utilizing spatial geometric information to boost model performance. HeightMapNet has shown exceptional results on the challenging nuScenes and Argoverse 2 datasets, outperforming several widely recognized approaches. The code will be available at \url{https://github.com/adasfag/HeightMapNet/}.
EmoAttack: Emotion-to-Image Diffusion Models for Emotional Backdoor Generation
Jun 22, 2024



Text-to-image diffusion models can create realistic images based on input texts. Users can describe an object to convey their opinions visually. In this work, we unveil a previously unrecognized and latent risk of using diffusion models to generate images; we utilize emotion in the input texts to introduce negative contents, potentially eliciting unfavorable emotions in users. Emotions play a crucial role in expressing personal opinions in our daily interactions, and the inclusion of maliciously negative content can lead users astray, exacerbating negative emotions. Specifically, we identify the emotion-aware backdoor attack (EmoAttack) that can incorporate malicious negative content triggered by emotional texts during image generation. We formulate such an attack as a diffusion personalization problem to avoid extensive model retraining and propose the EmoBooth. Unlike existing personalization methods, our approach fine-tunes a pre-trained diffusion model by establishing a mapping between a cluster of emotional words and a given reference image containing malicious negative content. To validate the effectiveness of our method, we built a dataset and conducted extensive analysis and discussion about its effectiveness. Given consumers' widespread use of diffusion models, uncovering this threat is critical for society.
Efficiently Adversarial Examples Generation for Visual-Language Models under Targeted Transfer Scenarios using Diffusion Models
Apr 18, 2024



Targeted transfer-based attacks involving adversarial examples pose a significant threat to large visual-language models (VLMs). However, the state-of-the-art (SOTA) transfer-based attacks incur high costs due to excessive iteration counts. Furthermore, the generated adversarial examples exhibit pronounced adversarial noise and demonstrate limited efficacy in evading defense methods such as DiffPure. To address these issues, inspired by score matching, we introduce AdvDiffVLM, which utilizes diffusion models to generate natural, unrestricted adversarial examples. Specifically, AdvDiffVLM employs Adaptive Ensemble Gradient Estimation to modify the score during the diffusion model's reverse generation process, ensuring the adversarial examples produced contain natural adversarial semantics and thus possess enhanced transferability. Simultaneously, to enhance the quality of adversarial examples further, we employ the GradCAM-guided Mask method to disperse adversarial semantics throughout the image, rather than concentrating them in a specific area. Experimental results demonstrate that our method achieves a speedup ranging from 10X to 30X compared to existing transfer-based attack methods, while maintaining superior quality of adversarial examples. Additionally, the generated adversarial examples possess strong transferability and exhibit increased robustness against adversarial defense methods. Notably, AdvDiffVLM can successfully attack commercial VLMs, including GPT-4V, in a black-box manner.
Sparse Semantic Map-Based Monocular Localization in Traffic Scenes Using Learned 2D-3D Point-Line Correspondences
Oct 10, 2022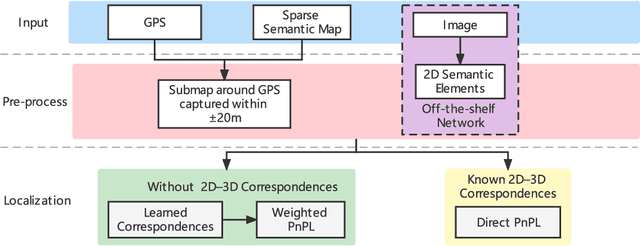
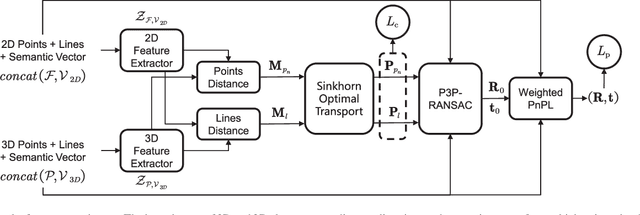
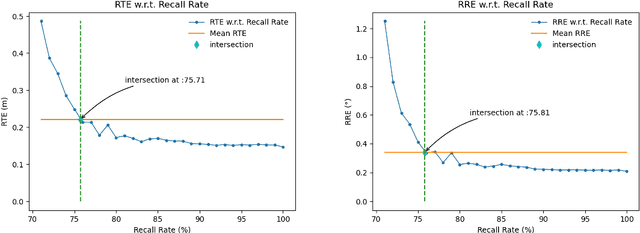
Vision-based localization in a prior map is of crucial importance for autonomous vehicles. Given a query image, the goal is to estimate the camera pose corresponding to the prior map, and the key is the registration problem of camera images within the map. While autonomous vehicles drive on the road under occlusion (e.g., car, bus, truck) and changing environment appearance (e.g., illumination changes, seasonal variation), existing approaches rely heavily on dense point descriptors at the feature level to solve the registration problem, entangling features with appearance and occlusion. As a result, they often fail to estimate the correct poses. To address these issues, we propose a sparse semantic map-based monocular localization method, which solves 2D-3D registration via a well-designed deep neural network. Given a sparse semantic map that consists of simplified elements (e.g., pole lines, traffic sign midpoints) with multiple semantic labels, the camera pose is then estimated by learning the corresponding features between the 2D semantic elements from the image and the 3D elements from the sparse semantic map. The proposed sparse semantic map-based localization approach is robust against occlusion and long-term appearance changes in the environments. Extensive experimental results show that the proposed method outperforms the state-of-the-art approaches.