 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Batch Nuclear-norm Maximization and Minimization for Robust Domain Adaptation
Aug 04, 2021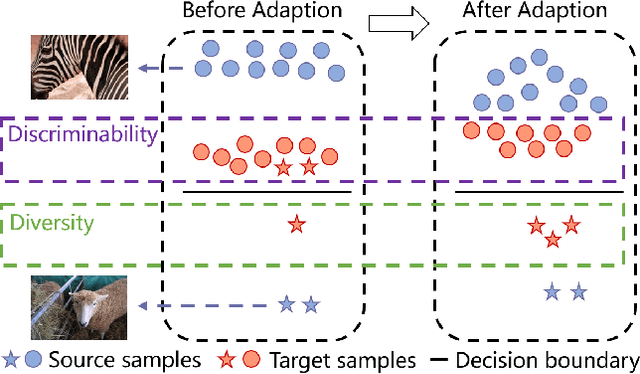
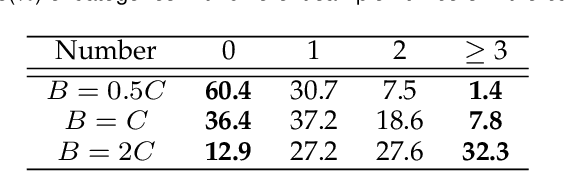
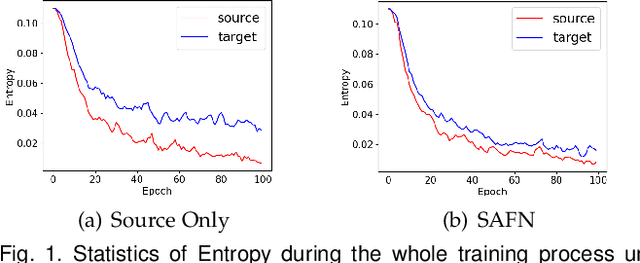
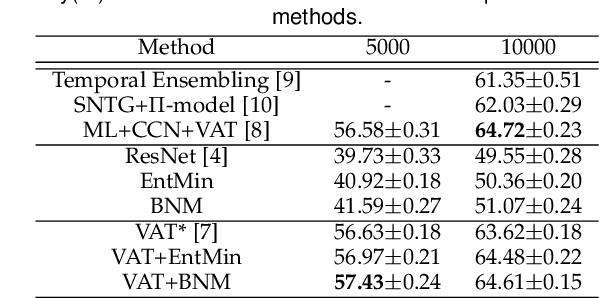
Due to the domain discrepancy in visual domain adaptation, the performance of source model degrades when bumping into the high data density near decision boundary in target domain. A common solution is to minimize the Shannon Entropy to push the decision boundary away from the high density area. However, entropy minimization also leads to severe reduction of prediction diversity, and unfortunately brings harm to the domain adaptation. In this paper, we investigate the prediction discriminability and diversity by studying the structure of the classification output matrix of a randomly selected data batch. We find by theoretical analysis that the prediction discriminability and diversity could be separately measured by the Frobenius-norm and rank of the batch output matrix. The nuclear-norm is an upperbound of the former, and a convex approximation of the latter. Accordingly, we propose Batch Nuclear-norm Maximization and Minimization, which performs nuclear-norm maximization on the target output matrix to enhance the target prediction ability, and nuclear-norm minimization on the source batch output matrix to increase applicability of the source domain knowledge. We further approximate the nuclear-norm by L_{1,2}-norm, and design multi-batch optimization for stable solution on large number of categories. The fast approximation method achieves O(n^2) computational complexity and better convergence property. Experiments show that our method could boost the adaptation accuracy and robustness under three typical domain adaptation scenarios. The code is available at https://github.com/cuishuhao/BNM.
Semantic-guided Pixel Sampling for Cloth-Changing Person Re-identification
Jul 24, 2021
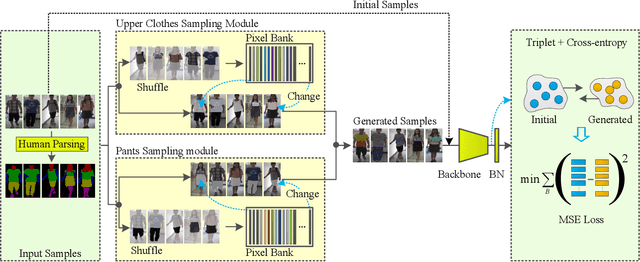
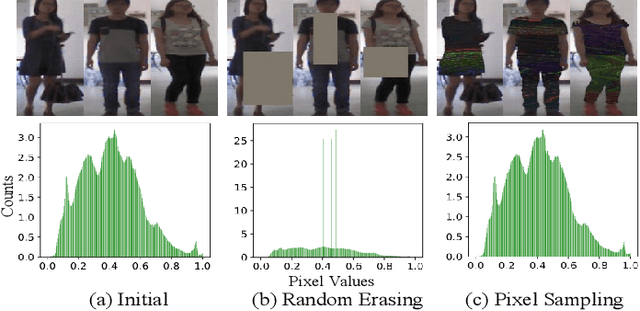
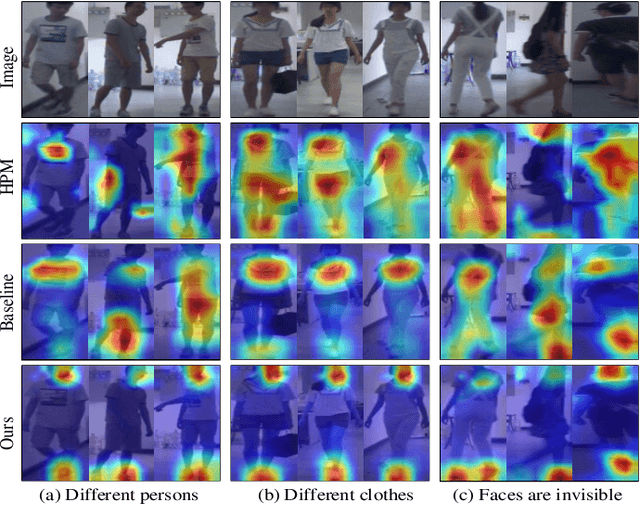
Cloth-changing person re-identification (re-ID) is a new rising research topic that aims at retrieving pedestrians whose clothes are changed. This task is quite challenging and has not been fully studied to date. Current works mainly focus on body shape or contour sketch, but they are not robust enough due to view and posture variations. The key to this task is to exploit cloth-irrelevant cues. This paper proposes a semantic-guided pixel sampling approach for the cloth-changing person re-ID task. We do not explicitly define which feature to extract but force the model to automatically learn cloth-irrelevant cues. Specifically, we first recognize the pedestrian's upper clothes and pants, then randomly change them by sampling pixels from other pedestrians. The changed samples retain the identity labels but exchange the pixels of clothes or pants among different pedestrians. Besides, we adopt a loss function to constrain the learned features to keep consistent before and after changes. In this way, the model is forced to learn cues that are irrelevant to upper clothes and pants. We conduct extensive experiments on the latest released PRCC dataset. Our method achieved 65.8% on Rank1 accuracy, which outperforms previous methods with a large margin. The code is available at https://github.com/shuxjweb/pixel_sampling.git.
Rectifying the Shortcut Learning of Background: Shared Object Concentration for Few-Shot Image Recognition
Jul 16, 2021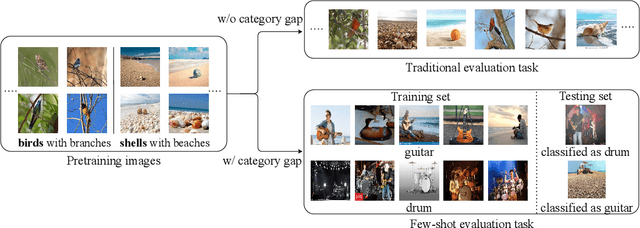
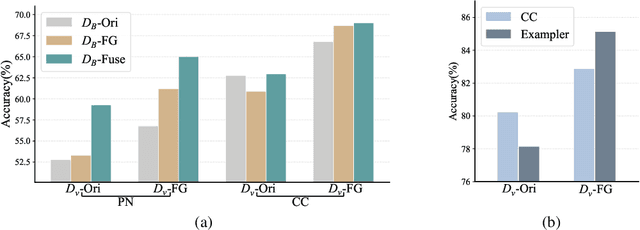
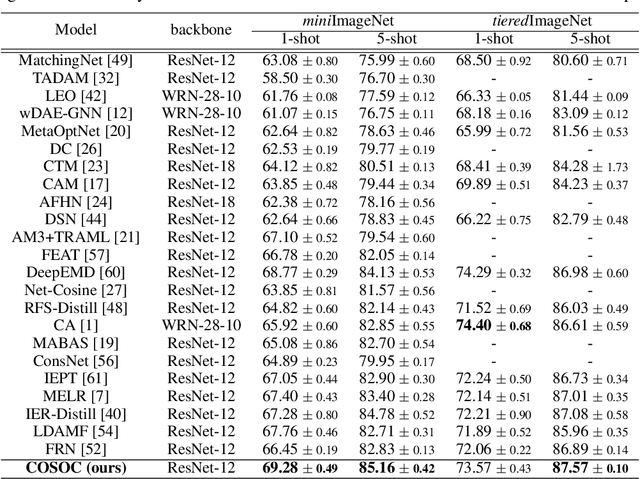
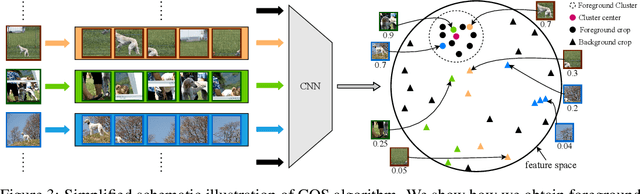
Few-Shot image classification aims to utilize pretrained knowledge learned from a large-scale dataset to tackle a series of downstream classification tasks. Typically, each task involves only few training examples from brand-new categories. This requires the pretraining models to focus on well-generalizable knowledge, but ignore domain-specific information. In this paper, we observe that image background serves as a source of domain-specific knowledge, which is a shortcut for models to learn in the source dataset, but is harmful when adapting to brand-new classes. To prevent the model from learning this shortcut knowledge, we propose COSOC, a novel Few-Shot Learning framework, to automatically figure out foreground objects at both pretraining and evaluation stage. COSOC is a two-stage algorithm motivated by the observation that foreground objects from different images within the same class share more similar patterns than backgrounds. At the pretraining stage, for each class, we cluster contrastive-pretrained features of randomly cropped image patches, such that crops containing only foreground objects can be identified by a single cluster. We then force the pretraining model to focus on found foreground objects by a fusion sampling strategy; at the evaluation stage, among images in each training class of any few-shot task, we seek for shared contents and filter out background. The recognized foreground objects of each class are used to match foreground of testing images. Extensive experiments tailored to inductive FSL tasks on two benchmarks demonstrate the state-of-the-art performance of our method.
Training Compact CNNs for Image Classification using Dynamic-coded Filter Fusion
Jul 14, 2021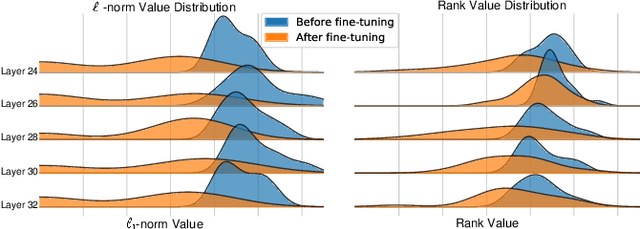
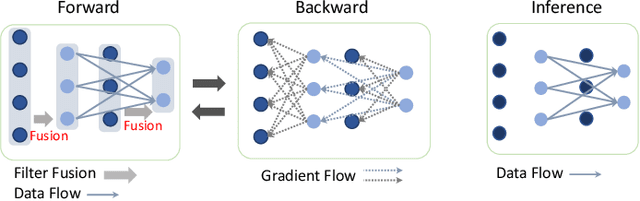
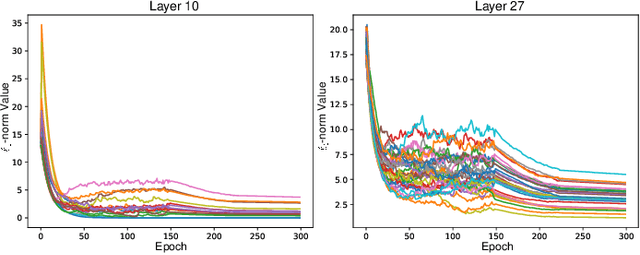

The mainstream approach for filter pruning is usually either to force a hard-coded importance estimation upon a computation-heavy pretrained model to select "important" filters, or to impose a hyperparameter-sensitive sparse constraint on the loss objective to regularize the network training. In this paper, we present a novel filter pruning method, dubbed dynamic-coded filter fusion (DCFF), to derive compact CNNs in a computation-economical and regularization-free manner for efficient image classification. Each filter in our DCFF is firstly given an inter-similarity distribution with a temperature parameter as a filter proxy, on top of which, a fresh Kullback-Leibler divergence based dynamic-coded criterion is proposed to evaluate the filter importance. In contrast to simply keeping high-score filters in other methods, we propose the concept of filter fusion, i.e., the weighted averages using the assigned proxies, as our preserved filters. We obtain a one-hot inter-similarity distribution as the temperature parameter approaches infinity. Thus, the relative importance of each filter can vary along with the training of the compact CNN, leading to dynamically changeable fused filters without both the dependency on the pretrained model and the introduction of sparse constraints. Extensive experiments on classification benchmarks demonstrate the superiority of our DCFF over the compared counterparts. For example, our DCFF derives a compact VGGNet-16 with only 72.77M FLOPs and 1.06M parameters while reaching top-1 accuracy of 93.47% on CIFAR-10. A compact ResNet-50 is obtained with 63.8% FLOPs and 58.6% parameter reductions, retaining 75.60% top-1 accuracy on ILSVRC-2012. Our code, narrower models and training logs are available at https://github.com/lmbxmu/DCFF.
Bag of Instances Aggregation Boosts Self-supervised Learning
Jul 04, 2021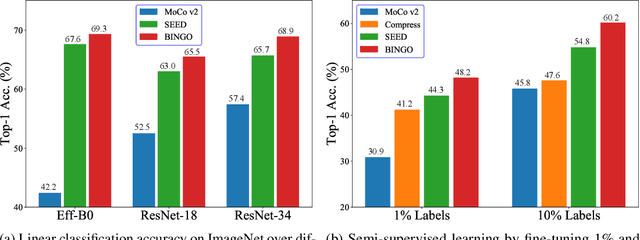
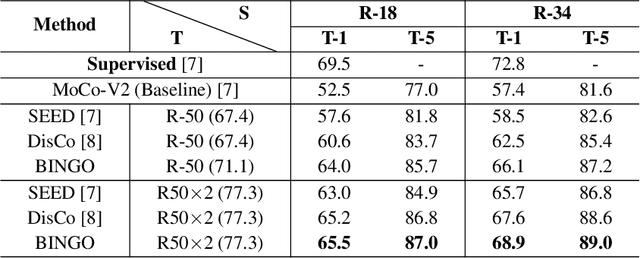
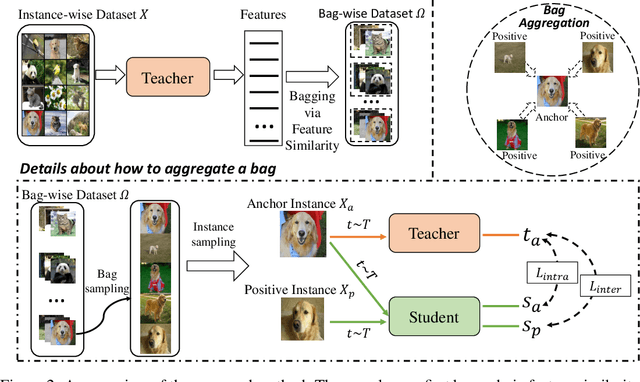
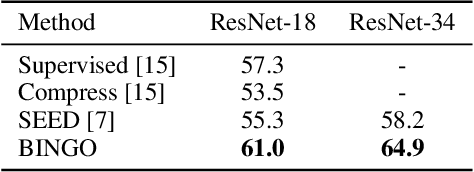
Recent advances in self-supervised learning have experienced remarkable progress, especially for contrastive learning based methods, which regard each image as well as its augmentations as an individual class and try to distinguish them from all other images. However, due to the large quantity of exemplars, this kind of pretext task intrinsically suffers from slow convergence and is hard for optimization. This is especially true for small scale models, which we find the performance drops dramatically comparing with its supervised counterpart. In this paper, we propose a simple but effective distillation strategy for unsupervised learning. The highlight is that the relationship among similar samples counts and can be seamlessly transferred to the student to boost the performance. Our method, termed as BINGO, which is short for \textbf{B}ag of \textbf{I}nsta\textbf{N}ces a\textbf{G}gregati\textbf{O}n, targets at transferring the relationship learned by the teacher to the student. Here bag of instances indicates a set of similar samples constructed by the teacher and are grouped within a bag, and the goal of distillation is to aggregate compact representations over the student with respect to instances in a bag. Notably, BINGO achieves new state-of-the-art performance on small scale models, \emph{i.e.}, 65.5% and 68.9% top-1 accuracies with linear evaluation on ImageNet, using ResNet-18 and ResNet-34 as backbone, respectively, surpassing baselines (52.5% and 57.4% top-1 accuracies) by a significant margin. The code will be available at \url{https://github.com/haohang96/bingo}.
Large-Scale Spatio-Temporal Person Re-identification: Algorithm and Benchmark
Jun 24, 2021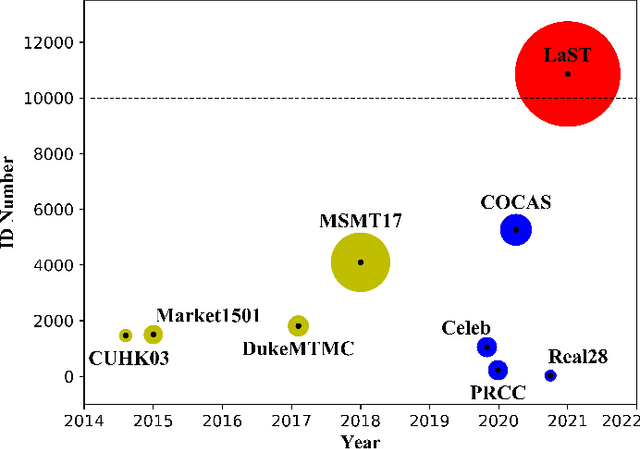
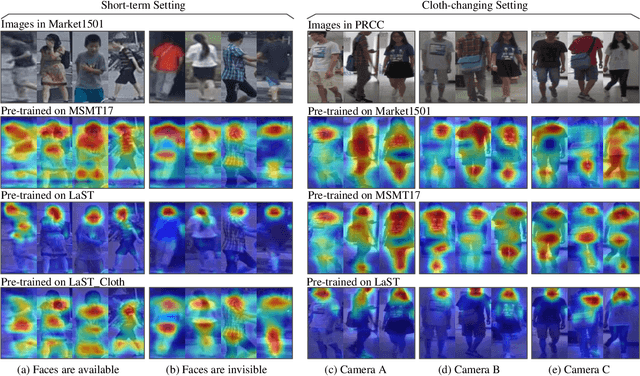
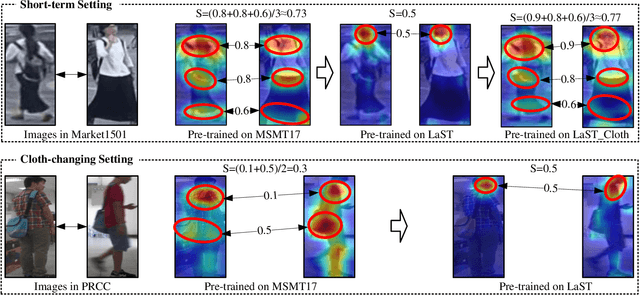

Person re-identification (re-ID) in the scenario with large spatial and temporal spans has not been fully explored. This is partially because that, existing benchmark datasets were mainly collected with limited spatial and temporal ranges, e.g., using videos recorded in a few days by cameras in a specific region of the campus. Such limited spatial and temporal ranges make it hard to simulate the difficulties of person re-ID in real scenarios. In this work, we contribute a novel Large-scale Spatio-Temporal LaST person re-ID dataset, including 10,862 identities with more than 228k images. Compared with existing datasets, LaST presents more challenging and high-diversity re-ID settings, and significantly larger spatial and temporal ranges. For instance, each person can appear in different cities or countries, and in various time slots from daytime to night, and in different seasons from spring to winter. To our best knowledge, LaST is a novel person re-ID dataset with the largest spatio-temporal ranges. Based on LaST, we verified its challenge by conducting a comprehensive performance evaluation of 14 re-ID algorithms. We further propose an easy-to-implement baseline that works well on such challenging re-ID setting. We also verified that models pre-trained on LaST can generalize well on existing datasets with short-term and cloth-changing scenarios. We expect LaST to inspire future works toward more realistic and challenging re-ID tasks. More information about the dataset is available at https://github.com/shuxjweb/last.git.
Analysis and Applications of Class-wise Robustness in Adversarial Training
Jun 23, 2021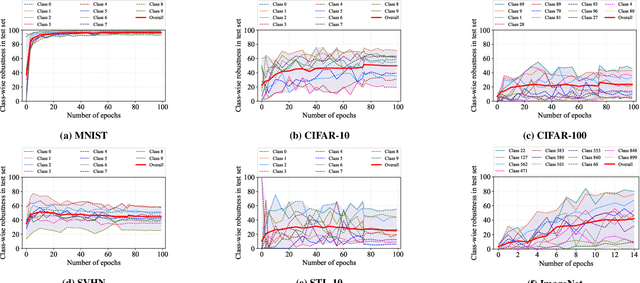
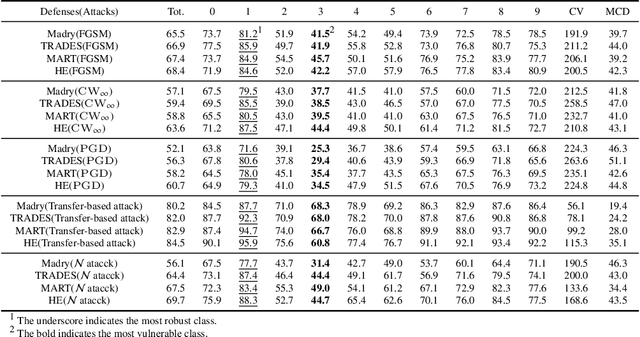

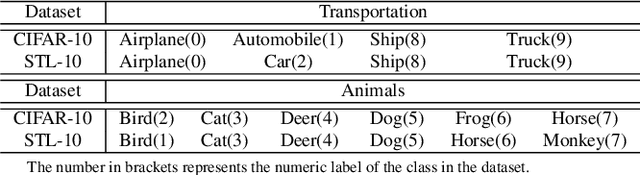
Adversarial training is one of the most effective approaches to improve model robustness against adversarial examples. However, previous works mainly focus on the overall robustness of the model, and the in-depth analysis on the role of each class involved in adversarial training is still missing. In this paper, we propose to analyze the class-wise robustness in adversarial training. First, we provide a detailed diagnosis of adversarial training on six benchmark datasets, i.e., MNIST, CIFAR-10, CIFAR-100, SVHN, STL-10 and ImageNet. Surprisingly, we find that there are remarkable robustness discrepancies among classes, leading to unbalance/unfair class-wise robustness in the robust models. Furthermore, we keep investigating the relations between classes and find that the unbalanced class-wise robustness is pretty consistent among different attack and defense methods. Moreover, we observe that the stronger attack methods in adversarial learning achieve performance improvement mainly from a more successful attack on the vulnerable classes (i.e., classes with less robustness). Inspired by these interesting findings, we design a simple but effective attack method based on the traditional PGD attack, named Temperature-PGD attack, which proposes to enlarge the robustness disparity among classes with a temperature factor on the confidence distribution of each image. Experiments demonstrate our method can achieve a higher attack rate than the PGD attack. Furthermore, from the defense perspective, we also make some modifications in the training and inference phase to improve the robustness of the most vulnerable class, so as to mitigate the large difference in class-wise robustness. We believe our work can contribute to a more comprehensive understanding of adversarial training as well as rethinking the class-wise properties in robust models.
Multi-dataset Pretraining: A Unified Model for Semantic Segmentation
Jun 08, 2021
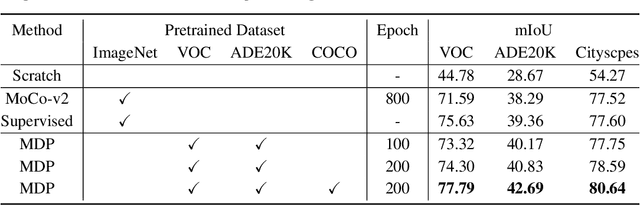
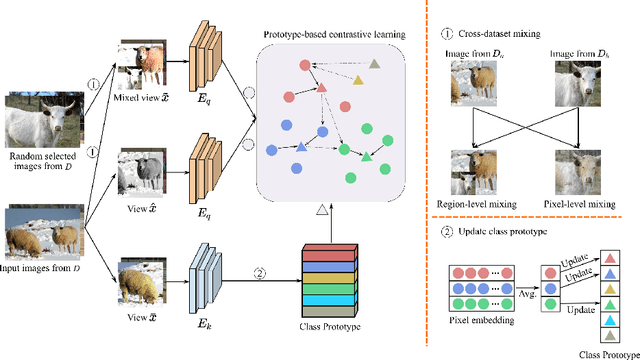
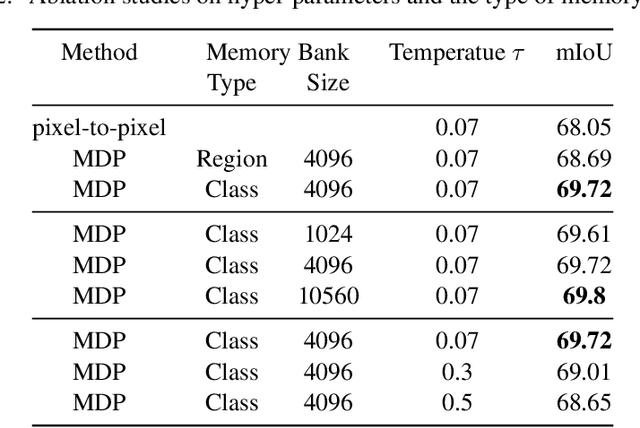
Collecting annotated data for semantic segmentation is time-consuming and hard to scale up. In this paper, we for the first time propose a unified framework, termed as Multi-Dataset Pretraining, to take full advantage of the fragmented annotations of different datasets. The highlight is that the annotations from different domains can be efficiently reused and consistently boost performance for each specific domain. This is achieved by first pretraining the network via the proposed pixel-to-prototype contrastive loss over multiple datasets regardless of their taxonomy labels, and followed by fine-tuning the pretrained model over specific dataset as usual. In order to better model the relationship among images and classes from different datasets, we extend the pixel level embeddings via cross dataset mixing and propose a pixel-to-class sparse coding strategy that explicitly models the pixel-class similarity over the manifold embedding space. In this way, we are able to increase intra-class compactness and inter-class separability, as well as considering inter-class similarity across different datasets for better transferability. Experiments conducted on several benchmarks demonstrate its superior performance. Notably, MDP consistently outperforms the pretrained models over ImageNet by a considerable margin, while only using less than 10% samples for pretraining.
Learning High-Precision Bounding Box for Rotated Object Detection via Kullback-Leibler Divergence
Jun 04, 2021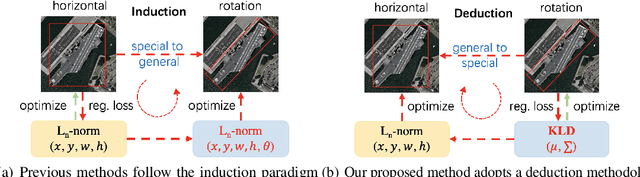

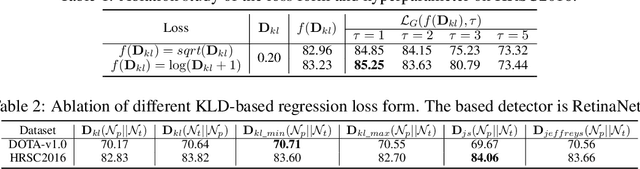
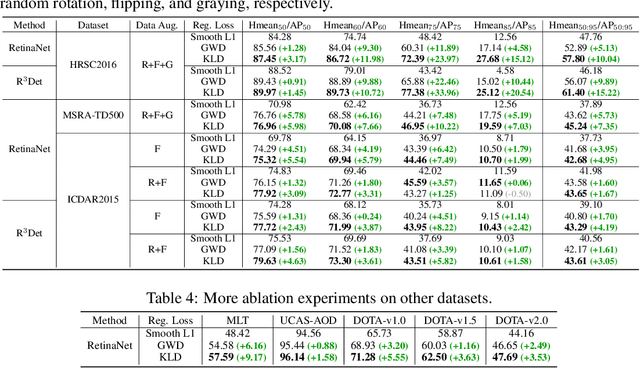
Existing rotated object detectors are mostly inherited from the horizontal detection paradigm, as the latter has evolved into a well-developed area. However, these detectors are difficult to perform prominently in high-precision detection due to the limitation of current regression loss design, especially for objects with large aspect ratios. Taking the perspective that horizontal detection is a special case for rotated object detection, in this paper, we are motivated to change the design of rotation regression loss from induction paradigm to deduction methodology, in terms of the relation between rotation and horizontal detection. We show that one essential challenge is how to modulate the coupled parameters in the rotation regression loss, as such the estimated parameters can influence to each other during the dynamic joint optimization, in an adaptive and synergetic way. Specifically, we first convert the rotated bounding box into a 2-D Gaussian distribution, and then calculate the Kullback-Leibler Divergence (KLD) between the Gaussian distributions as the regression loss. By analyzing the gradient of each parameter, we show that KLD (and its derivatives) can dynamically adjust the parameter gradients according to the characteristics of the object. It will adjust the importance (gradient weight) of the angle parameter according to the aspect ratio. This mechanism can be vital for high-precision detection as a slight angle error would cause a serious accuracy drop for large aspect ratios objects. More importantly, we have proved that KLD is scale invariant. We further show that the KLD loss can be degenerated into the popular $l_{n}$-norm loss for horizontal detection. Experimental results on seven datasets using different detectors show its consistent superiority, and codes are available at https://github.com/yangxue0827/RotationDetection.
Exploring the Diversity and Invariance in Yourself for Visual Pre-Training Task
Jun 01, 2021
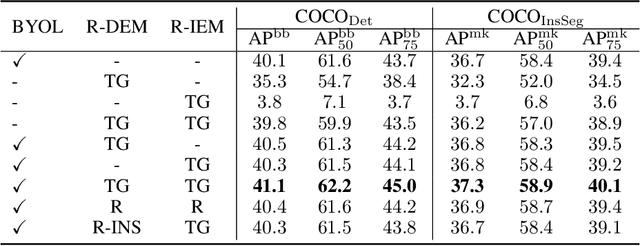
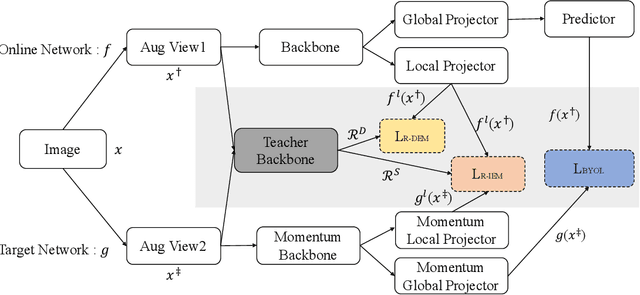
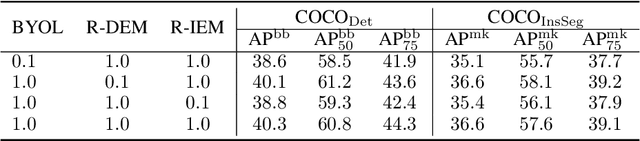
Recently, self-supervised learning methods have achieved remarkable success in visual pre-training task. By simply pulling the different augmented views of each image together or other novel mechanisms, they can learn much unsupervised knowledge and significantly improve the transfer performance of pre-training models. However, these works still cannot avoid the representation collapse problem, i.e., they only focus on limited regions or the extracted features on totally different regions inside each image are nearly the same. Generally, this problem makes the pre-training models cannot sufficiently describe the multi-grained information inside images, which further limits the upper bound of their transfer performance. To alleviate this issue, this paper introduces a simple but effective mechanism, called Exploring the Diversity and Invariance in Yourself E-DIY. By simply pushing the most different regions inside each augmented view away, E-DIY can preserve the diversity of extracted region-level features. By pulling the most similar regions from different augmented views of the same image together, E-DIY can ensure the robustness of region-level features. Benefited from the above diversity and invariance exploring mechanism, E-DIY maximally extracts the multi-grained visual information inside each image. Extensive experiments on downstream tasks demonstrate the superiority of our proposed approach, e.g., there are 2.1% improvements compared with the strong baseline BYOL on COCO while fine-tuning Mask R-CNN with the R50-C4 backbone and 1X learning schedule.