 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamSmooth: Improving Model-based Reinforcement Learning via Reward Smoothing
Nov 02, 2023



Model-based reinforcement learning (MBRL) has gained much attention for its ability to learn complex behaviors in a sample-efficient way: planning actions by generating imaginary trajectories with predicted rewards. Despite its success, we found that surprisingly, reward prediction is often a bottleneck of MBRL, especially for sparse rewards that are challenging (or even ambiguous) to predict. Motivated by the intuition that humans can learn from rough reward estimates, we propose a simple yet effective reward smoothing approach, DreamSmooth, which learns to predict a temporally-smoothed reward, instead of the exact reward at the given timestep. We empirically show that DreamSmooth achieves state-of-the-art performance on long-horizon sparse-reward tasks both in sample efficiency and final performance without losing performance on common benchmarks, such as Deepmind Control Suite and Atari benchmarks.
Managing AI Risks in an Era of Rapid Progress
Oct 26, 2023In this short consensus paper, we outline risks from upcoming, advanced AI systems. We examine large-scale social harms and malicious uses, as well as an irreversible loss of human control over autonomous AI systems. In light of rapid and continuing AI progress, we propose priorities for AI R&D and governance.
Interactive Task Planning with Language Models
Oct 16, 2023An interactive robot framework accomplishes long-horizon task planning and can easily generalize to new goals or distinct tasks, even during execution. However, most traditional methods require predefined module design, which makes it hard to generalize to different goals. Recent large language model based approaches can allow for more open-ended planning but often require heavy prompt engineering or domain-specific pretrained models. To tackle this, we propose a simple framework that achieves interactive task planning with language models. Our system incorporates both high-level planning and low-level function execution via language. We verify the robustness of our system in generating novel high-level instructions for unseen objectives and its ease of adaptation to different tasks by merely substituting the task guidelines, without the need for additional complex prompt engineering. Furthermore, when the user sends a new request, our system is able to replan accordingly with precision based on the new request, task guidelines and previously executed steps. Please check more details on our https://wuphilipp.github.io/itp_site and https://youtu.be/TrKLuyv26_g.
Video Language Planning
Oct 16, 2023We are interested in enabling visual planning for complex long-horizon tasks in the space of generated videos and language, leveraging recent advances in large generative models pretrained on Internet-scale data. To this end, we present video language planning (VLP), an algorithm that consists of a tree search procedure, where we train (i) vision-language models to serve as both policies and value functions, and (ii) text-to-video models as dynamics models. VLP takes as input a long-horizon task instruction and current image observation, and outputs a long video plan that provides detailed multimodal (video and language) specifications that describe how to complete the final task. VLP scales with increasing computation budget where more computation time results in improved video plans, and is able to synthesize long-horizon video plans across different robotics domains: from multi-object rearrangement, to multi-camera bi-arm dexterous manipulation. Generated video plans can be translated into real robot actions via goal-conditioned policies, conditioned on each intermediate frame of the generated video. Experiments show that VLP substantially improves long-horizon task success rates compared to prior methods on both simulated and real robots (across 3 hardware platforms).
Exploration with Principles for Diverse AI Supervision
Oct 13, 2023Training large transformers using next-token prediction has given rise to groundbreaking advancements in AI. While this generative AI approach has produced impressive results, it heavily leans on human supervision. Even state-of-the-art AI models like ChatGPT depend on fine-tuning through human demonstrations, demanding extensive human input and domain expertise. This strong reliance on human oversight poses a significant hurdle to the advancement of AI innovation. To address this limitation, we propose a novel paradigm termed Exploratory AI (EAI) aimed at autonomously generating high-quality training data. Drawing inspiration from unsupervised reinforcement learning (RL) pretraining, EAI achieves exploration within the natural language space. We accomplish this by harnessing large language models to assess the novelty of generated content. Our approach employs two key components: an actor that generates novel content following exploration principles and a critic that evaluates the generated content, offering critiques to guide the actor. Empirical evaluations demonstrate that EAI significantly boosts model performance on complex reasoning tasks, addressing the limitations of human-intensive supervision.
Ring Attention with Blockwise Transformers for Near-Infinite Context
Oct 12, 2023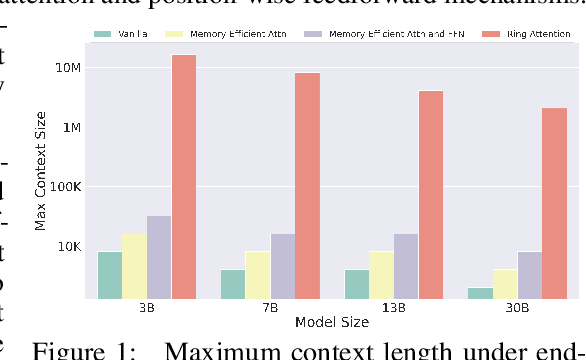
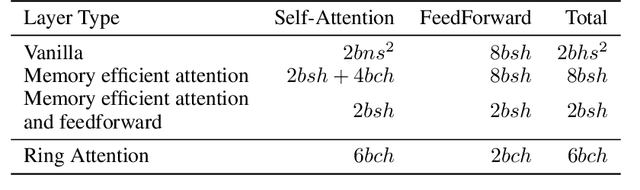
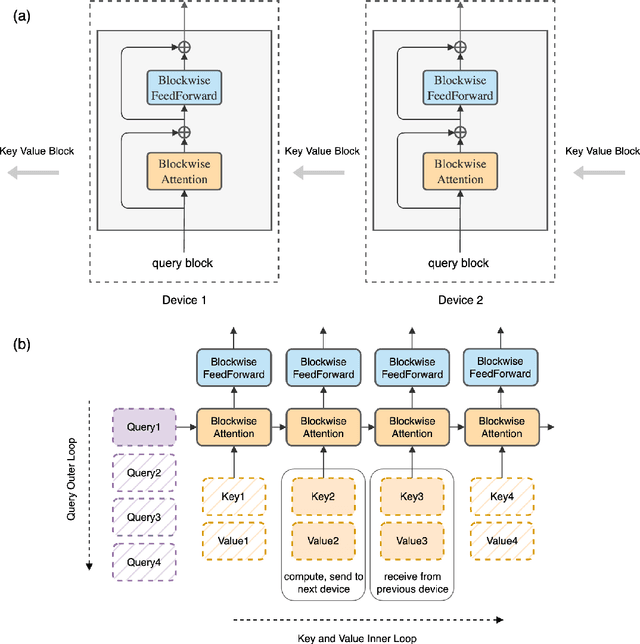

Transformers have emerged as the architecture of choice for many state-of-the-art AI models, showcasing exceptional performance across a wide range of AI applications. However, the memory demands imposed by Transformers limit their ability to handle long sequences, thereby creating challenges for tasks involving extended sequences or long-term dependencies. We present a distinct approach, Ring Attention, which leverages blockwise computation of self-attention to distribute long sequences across multiple devices while overlapping the communication of key-value blocks with the computation of blockwise attention. Ring Attention enables training and inference of sequences that are up to device count times longer than those of prior memory-efficient Transformers, effectively eliminating the memory constraints imposed by individual devices. Extensive experiments on language modeling tasks demonstrate the effectiveness of Ring Attention in allowing large sequence input size and improving performance.
Foundation Reinforcement Learning: towards Embodied Generalist Agents with Foundation Prior Assistance
Oct 10, 2023



Recently, people have shown that large-scale pre-training from internet-scale data is the key to building generalist models, as witnessed in NLP. To build embodied generalist agents, we and many other researchers hypothesize that such foundation prior is also an indispensable component. However, it is unclear what is the proper concrete form to represent those embodied foundation priors and how they should be used in the downstream task. In this paper, we propose an intuitive and effective set of embodied priors that consist of foundation policy, value, and success reward. The proposed priors are based on the goal-conditioned MDP. To verify their effectiveness, we instantiate an actor-critic method assisted by the priors, called Foundation Actor-Critic (FAC). We name our framework as Foundation Reinforcement Learning (FRL), since it completely relies on embodied foundation priors to explore, learn and reinforce. The benefits of FRL are threefold. (1) Sample efficient. With foundation priors, FAC learns significantly faster than traditional RL. Our evaluation on the Meta-World has proved that FAC can achieve 100% success rates for 7/8 tasks under less than 200k frames, which outperforms the baseline method with careful manual-designed rewards under 1M frames. (2) Robust to noisy priors. Our method tolerates the unavoidable noise in embodied foundation models. We show that FAC works well even under heavy noise or quantization errors. (3) Minimal human intervention: FAC completely learns from the foundation priors, without the need of human-specified dense reward, or providing teleoperated demos. Thus, FAC can be easily scaled up. We believe our FRL framework could enable the future robot to autonomously explore and learn without human intervention in the physical world. In summary, our proposed FRL is a novel and powerful learning paradigm, towards achieving embodied generalist agents.
Learning Interactive Real-World Simulators
Oct 09, 2023



Generative models trained on internet data have revolutionized how text, image, and video content can be created. Perhaps the next milestone for generative models is to simulate realistic experience in response to actions taken by humans, robots, and other interactive agents. Applications of a real-world simulator range from controllable content creation in games and movies, to training embodied agents purely in simulation that can be directly deployed in the real world. We explore the possibility of learning a universal simulator (UniSim) of real-world interaction through generative modeling. We first make the important observation that natural datasets available for learning a real-world simulator are often rich along different axes (e.g., abundant objects in image data, densely sampled actions in robotics data, and diverse movements in navigation data). With careful orchestration of diverse datasets, each providing a different aspect of the overall experience, UniSim can emulate how humans and agents interact with the world by simulating the visual outcome of both high-level instructions such as "open the drawer" and low-level controls such as "move by x, y" from otherwise static scenes and objects. There are numerous use cases for such a real-world simulator. As an example, we use UniSim to train both high-level vision-language planners and low-level reinforcement learning policies, each of which exhibit zero-shot real-world transfer after training purely in a learned real-world simulator. We also show that other types of intelligence such as video captioning models can benefit from training with simulated experience in UniSim, opening up even wider applications. Video demos can be found at https://universal-simulator.github.io.
Speed Co-Augmentation for Unsupervised Audio-Visual Pre-training
Sep 25, 2023This work aims to improve unsupervised audio-visual pre-training. Inspired by the efficacy of data augmentation in visual contrastive learning, we propose a novel speed co-augmentation method that randomly changes the playback speeds of both audio and video data. Despite its simplicity, the speed co-augmentation method possesses two compelling attributes: (1) it increases the diversity of audio-visual pairs and doubles the size of negative pairs, resulting in a significant enhancement in the learned representations, and (2) it changes the strict correlation between audio-visual pairs but introduces a partial relationship between the augmented pairs, which is modeled by our proposed SoftInfoNCE loss to further boost the performance. Experimental results show that the proposed method significantly improves the learned representations when compared to vanilla audio-visual contrastive learning.
GELLO: A General, Low-Cost, and Intuitive Teleoperation Framework for Robot Manipulators
Sep 22, 2023



Imitation learning from human demonstrations is a powerful framework to teach robots new skills. However, the performance of the learned policies is bottlenecked by the quality, scale, and variety of the demonstration data. In this paper, we aim to lower the barrier to collecting large and high-quality human demonstration data by proposing GELLO, a general framework for building low-cost and intuitive teleoperation systems for robotic manipulation. Given a target robot arm, we build a GELLO controller that has the same kinematic structure as the target arm, leveraging 3D-printed parts and off-the-shelf motors. GELLO is easy to build and intuitive to use. Through an extensive user study, we show that GELLO enables more reliable and efficient demonstration collection compared to commonly used teleoperation devices in the imitation learning literature such as VR controllers and 3D spacemouses. We further demonstrate the capabilities of GELLO for performing complex bi-manual and contact-rich manipulation tasks. To make GELLO accessible to everyone, we have designed and built GELLO systems for 3 commonly used robotic arms: Franka, UR5, and xArm. All software and hardware are open-sourced and can be found on our website: https://wuphilipp.github.io/gello/.