 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a Diffusion Model Policy from Rewards via Q-Score Matching
Dec 18, 2023



Diffusion models have become a popular choice for representing actor policies in behavior cloning and offline reinforcement learning. This is due to their natural ability to optimize an expressive class of distributions over a continuous space. However, previous works fail to exploit the score-based structure of diffusion models, and instead utilize a simple behavior cloning term to train the actor, limiting their ability in the actor-critic setting. In this paper, we focus on off-policy reinforcement learning and propose a new method for learning a diffusion model policy that exploits the linked structure between the score of the policy and the action gradient of the Q-function. We denote this method Q-score matching and provide theoretical justification for this approach. We conduct experiments in simulated environments to demonstrate the effectiveness of our proposed method and compare to popular baselines.
Barkour: Benchmarking Animal-level Agility with Quadruped Robots
May 24, 2023



Animals have evolved various agile locomotion strategies, such as sprinting, leaping, and jumping. There is a growing interest in developing legged robots that move like their biological counterparts and show various agile skills to navigate complex environments quickly. Despite the interest, the field lacks systematic benchmarks to measure the performance of control policies and hardware in agility. We introduce the Barkour benchmark, an obstacle course to quantify agility for legged robots. Inspired by dog agility competitions, it consists of diverse obstacles and a time based scoring mechanism. This encourages researchers to develop controllers that not only move fast, but do so in a controllable and versatile way. To set strong baselines, we present two methods for tackling the benchmark. In the first approach, we train specialist locomotion skills using on-policy reinforcement learning methods and combine them with a high-level navigation controller. In the second approach, we distill the specialist skills into a Transformer-based generalist locomotion policy, named Locomotion-Transformer, that can handle various terrains and adjust the robot's gait based on the perceived environment and robot states. Using a custom-built quadruped robot, we demonstrate that our method can complete the course at half the speed of a dog. We hope that our work represents a step towards creating controllers that enable robots to reach animal-level agility.
Video Prediction Models as Rewards for Reinforcement Learning
May 23, 2023



Specifying reward signals that allow agents to learn complex behaviors is a long-standing challenge in reinforcement learning. A promising approach is to extract preferences for behaviors from unlabeled videos, which are widely available on the internet. We present Video Prediction Rewards (VIPER), an algorithm that leverages pretrained video prediction models as action-free reward signals for reinforcement learning. Specifically, we first train an autoregressive transformer on expert videos and then use the video prediction likelihoods as reward signals for a reinforcement learning agent. VIPER enables expert-level control without programmatic task rewards across a wide range of DMC, Atari, and RLBench tasks. Moreover, generalization of the video prediction model allows us to derive rewards for an out-of-distribution environment where no expert data is available, enabling cross-embodiment generalization for tabletop manipulation. We see our work as starting point for scalable reward specification from unlabeled videos that will benefit from the rapid advances in generative modeling. Source code and datasets are available on the project website: https://escontrela.me
Autonomously Untangling Long Cables
Jul 16, 2022


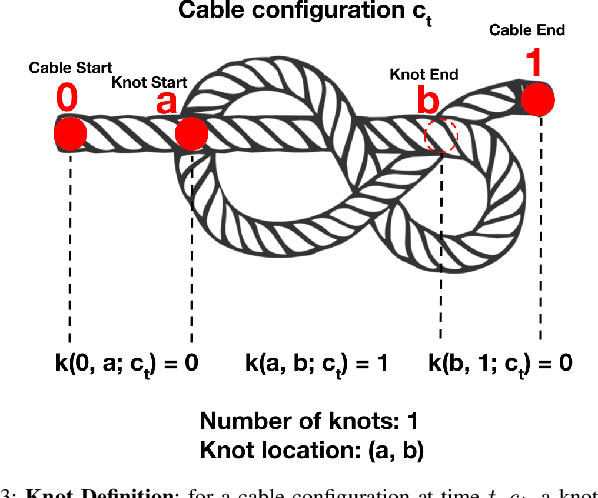
Cables are ubiquitous in many settings, but are prone to self-occlusions and knots, making them difficult to perceive and manipulate. The challenge often increases with cable length: long cables require more complex slack management and strategies to facilitate observability and reachability. In this paper, we focus on autonomously untangling cables up to 3 meters in length using a bilateral robot. We develop new motion primitives to efficiently untangle long cables and novel gripper jaws specialized for this task. We present Sliding and Grasping for Tangle Manipulation (SGTM), an algorithm that composes these primitives with RGBD vision to iteratively untangle. SGTM untangles cables with success rates of 67% on isolated overhand and figure eight knots and 50% on more complex configurations. Supplementary material, visualizations, and videos can be found at https://sites.google.com/view/rss-2022-untangling/home.
DayDreamer: World Models for Physical Robot Learning
Jun 28, 2022
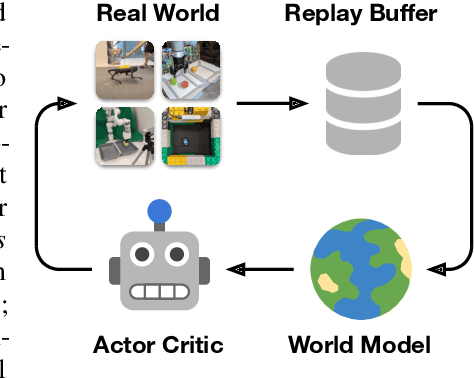
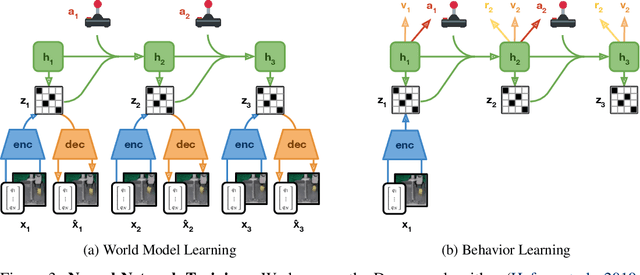

To solve tasks in complex environments, robots need to learn from experience. Deep reinforcement learning is a common approach to robot learning but requires a large amount of trial and error to learn, limiting its deployment in the physical world. As a consequence, many advances in robot learning rely on simulators. On the other hand, learning inside of simulators fails to capture the complexity of the real world, is prone to simulator inaccuracies, and the resulting behaviors do not adapt to changes in the world. The Dreamer algorithm has recently shown great promise for learning from small amounts of interaction by planning within a learned world model, outperforming pure reinforcement learning in video games. Learning a world model to predict the outcomes of potential actions enables planning in imagination, reducing the amount of trial and error needed in the real environment. However, it is unknown whether Dreamer can facilitate faster learning on physical robots. In this paper, we apply Dreamer to 4 robots to learn online and directly in the real world, without simulators. Dreamer trains a quadruped robot to roll off its back, stand up, and walk from scratch and without resets in only 1 hour. We then push the robot and find that Dreamer adapts within 10 minutes to withstand perturbations or quickly roll over and stand back up. On two different robotic arms, Dreamer learns to pick and place multiple objects directly from camera images and sparse rewards, approaching human performance. On a wheeled robot, Dreamer learns to navigate to a goal position purely from camera images, automatically resolving ambiguity about the robot orientation. Using the same hyperparameters across all experiments, we find that Dreamer is capable of online learning in the real world, establishing a strong baseline. We release our infrastructure for future applications of world models to robot learning.
Adversarial Motion Priors Make Good Substitutes for Complex Reward Functions
Mar 28, 2022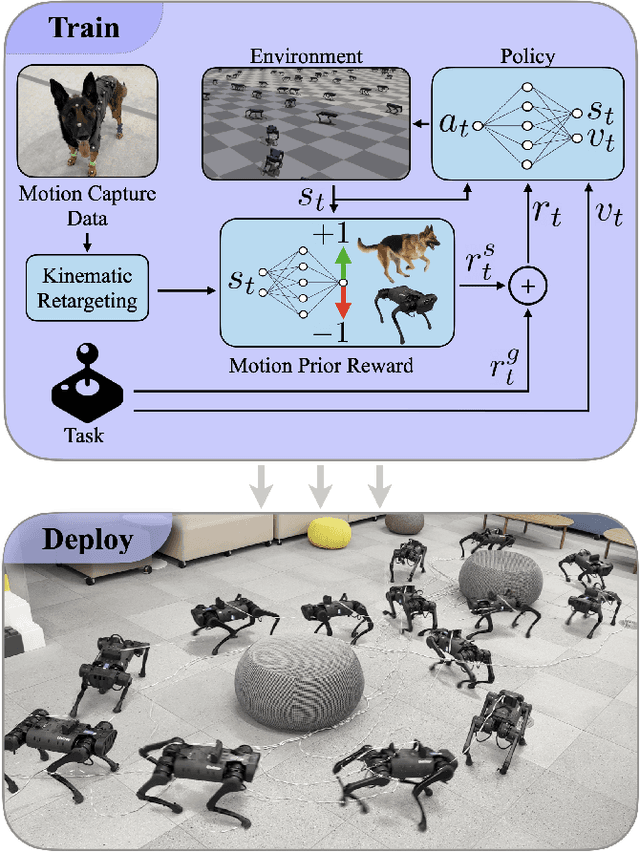
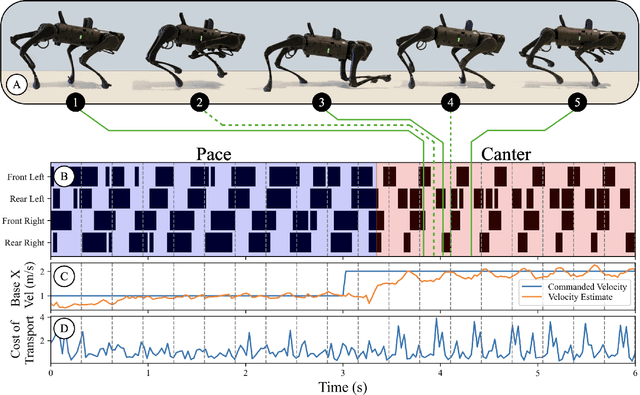


Training a high-dimensional simulated agent with an under-specified reward function often leads the agent to learn physically infeasible strategies that are ineffective when deployed in the real world. To mitigate these unnatural behaviors, reinforcement learning practitioners often utilize complex reward functions that encourage physically plausible behaviors. However, a tedious labor-intensive tuning process is often required to create hand-designed rewards which might not easily generalize across platforms and tasks. We propose substituting complex reward functions with "style rewards" learned from a dataset of motion capture demonstrations. A learned style reward can be combined with an arbitrary task reward to train policies that perform tasks using naturalistic strategies. These natural strategies can also facilitate transfer to the real world. We build upon Adversarial Motion Priors -- an approach from the computer graphics domain that encodes a style reward from a dataset of reference motions -- to demonstrate that an adversarial approach to training policies can produce behaviors that transfer to a real quadrupedal robot without requiring complex reward functions. We also demonstrate that an effective style reward can be learned from a few seconds of motion capture data gathered from a German Shepherd and leads to energy-efficient locomotion strategies with natural gait transitions.
Learning Agile Locomotion Skills with a Mentor
Nov 11, 2020
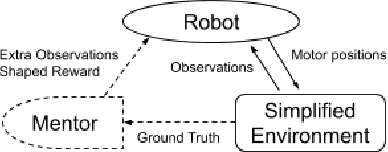
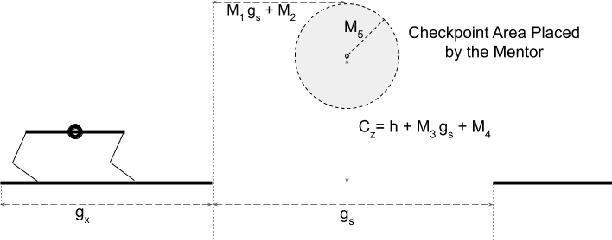
Developing agile behaviors for legged robots remains a challenging problem. While deep reinforcement learning is a promising approach, learning truly agile behaviors typically requires tedious reward shaping and careful curriculum design. We formulate agile locomotion as a multi-stage learning problem in which a mentor guides the agent throughout the training. The mentor is optimized to place a checkpoint to guide the movement of the robot's center of mass while the student (i.e. the robot) learns to reach these checkpoints. Once the student can solve the task, we teach the student to perform the task without the mentor. We evaluate our proposed learning system with a simulated quadruped robot on a course consisting of randomly generated gaps and hurdles. Our method significantly outperforms a single-stage RL baseline without a mentor, and the quadruped robot can agilely run and jump across gaps and obstacles. Finally, we present a detailed analysis of the learned behaviors' feasibility and efficiency.
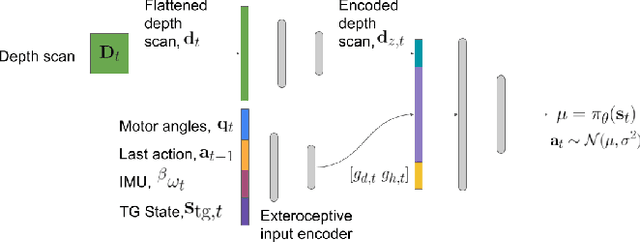
Zero-Shot Terrain Generalization for Visual Locomotion Policies
Nov 11, 2020
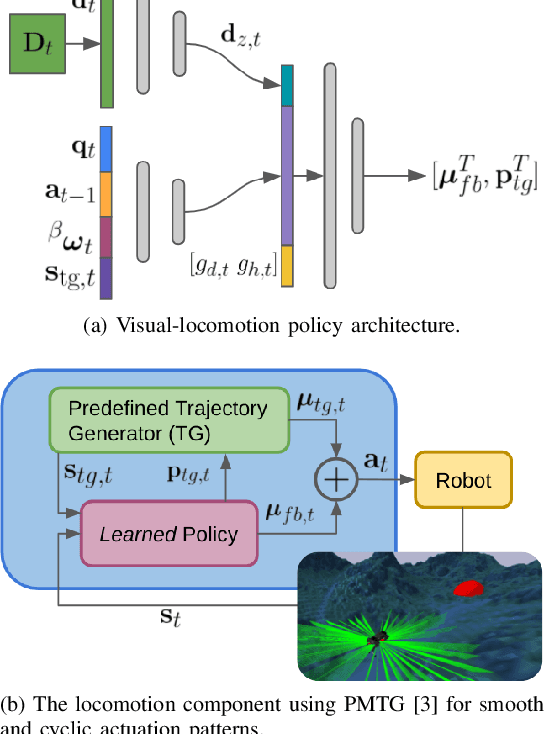


Legged robots have unparalleled mobility on unstructured terrains. However, it remains an open challenge to design locomotion controllers that can operate in a large variety of environments. In this paper, we address this challenge of automatically learning locomotion controllers that can generalize to a diverse collection of terrains often encountered in the real world. We frame this challenge as a multi-task reinforcement learning problem and define each task as a type of terrain that the robot needs to traverse. We propose an end-to-end learning approach that makes direct use of the raw exteroceptive inputs gathered from a simulated 3D LiDAR sensor, thus circumventing the need for ground-truth heightmaps or preprocessing of perception information. As a result, the learned controller demonstrates excellent zero-shot generalization capabilities and can navigate 13 different environments, including stairs, rugged land, cluttered offices, and indoor spaces with humans.
A Factor-Graph Approach for Optimization Problems with Dynamics Constraints
Nov 11, 2020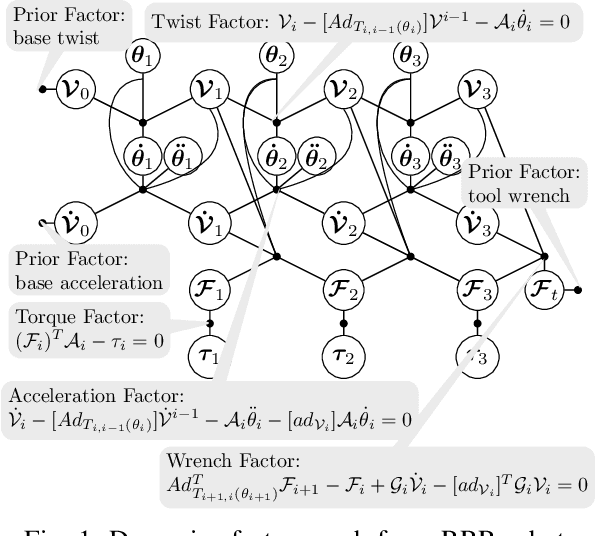
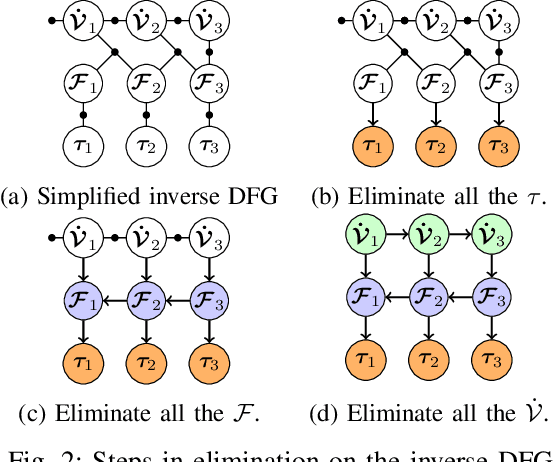
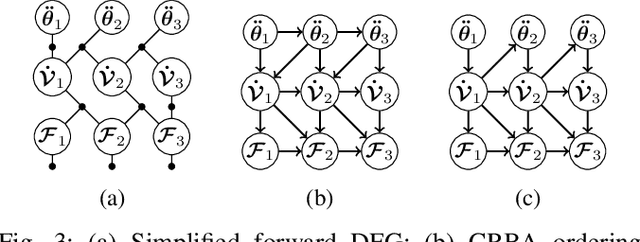
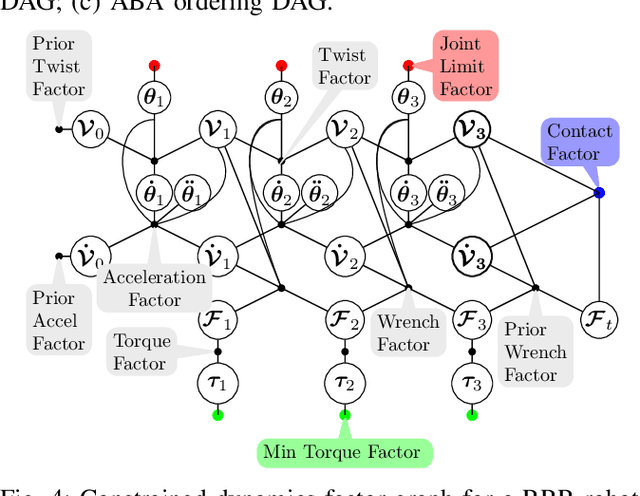
In this paper, we introduce dynamics factor graphs as a graphical framework to solve dynamics problems and kinodynamic motion planning problems with full consideration of whole-body dynamics and contacts. A factor graph representation of dynamics problems provides an insightful visualization of their mathematical structure and can be used in conjunction with sparse nonlinear optimizers to solve challenging, high-dimensional optimization problems in robotics. We can easily formulate kinodynamic motion planning as a trajectory optimization problem with factor graphs. We demonstrate the flexibility and descriptive power of dynamics factor graphs by applying them to control various dynamical systems, ranging from a simple cart pole to a 12-DoF quadrupedal robot.