 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Llama 2: Open Foundation and Fine-Tuned Chat Models
Jul 19, 2023



In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our models outperform open-source chat models on most benchmarks we tested, and based on our human evaluations for helpfulness and safety, may be a suitable substitute for closed-source models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs.
Masked Trajectory Models for Prediction, Representation, and Control
May 04, 2023



We introduce Masked Trajectory Models (MTM) as a generic abstraction for sequential decision making. MTM takes a trajectory, such as a state-action sequence, and aims to reconstruct the trajectory conditioned on random subsets of the same trajectory. By training with a highly randomized masking pattern, MTM learns versatile networks that can take on different roles or capabilities, by simply choosing appropriate masks at inference time. For example, the same MTM network can be used as a forward dynamics model, inverse dynamics model, or even an offline RL agent. Through extensive experiments in several continuous control tasks, we show that the same MTM network -- i.e. same weights -- can match or outperform specialized networks trained for the aforementioned capabilities. Additionally, we find that state representations learned by MTM can significantly accelerate the learning speed of traditional RL algorithms. Finally, in offline RL benchmarks, we find that MTM is competitive with specialized offline RL algorithms, despite MTM being a generic self-supervised learning method without any explicit RL components. Code is available at https://github.com/facebookresearch/mtm
Modeling Scattering Coefficients using Self-Attentive Complex Polynomials with Image-based Representation
Jan 10, 2023Finding antenna designs that satisfy frequency requirements and are also optimal with respect to multiple physical criteria is a critical component in designing next generation hardware. However, such a process is non-trivial because the objective function is typically highly nonlinear and sensitive to subtle design change. Moreover, the objective to be optimized often involves electromagnetic (EM) simulations, which is slow and expensive with commercial simulation software. In this work, we propose a sample-efficient and accurate surrogate model, named CZP (Constant Zeros Poles), to directly estimate the scattering coefficients in the frequency domain of a given 2D planar antenna design, without using a simulator. CZP achieves this by predicting the complex zeros and poles for the frequency response of scattering coefficients, which we have theoretically justified for any linear PDE, including Maxwell's equations. Moreover, instead of using low-dimensional representations, CZP leverages a novel image-based representation for antenna topology inspired by the existing mesh-based EM simulation techniques, and attention-based neural network architectures. We demonstrate experimentally that CZP not only outperforms baselines in terms of test loss, but also is able to find 2D antenna designs verifiable by commercial software with only 40k training samples, when coupling with advanced sequential search techniques like reinforcement learning.
Learning to compile smartly for program size reduction
Jan 09, 2023Compiler optimization passes are an important tool for improving program efficiency and reducing program size, but manually selecting optimization passes can be time-consuming and error-prone. While human experts have identified a few fixed sequences of optimization passes (e.g., the Clang -Oz passes) that perform well for a wide variety of programs, these sequences are not conditioned on specific programs. In this paper, we propose a novel approach that learns a policy to select passes for program size reduction, allowing for customization and adaptation to specific programs. Our approach uses a search mechanism that helps identify useful pass sequences and a GNN with customized attention that selects the optimal sequence to use. Crucially it is able to generalize to new, unseen programs, making it more flexible and general than previous approaches. We evaluate our approach on a range of programs and show that it leads to size reduction compared to traditional optimization techniques. Our results demonstrate the potential of a single policy that is able to optimize many programs.
CenterSnap: Single-Shot Multi-Object 3D Shape Reconstruction and Categorical 6D Pose and Size Estimation
Mar 03, 2022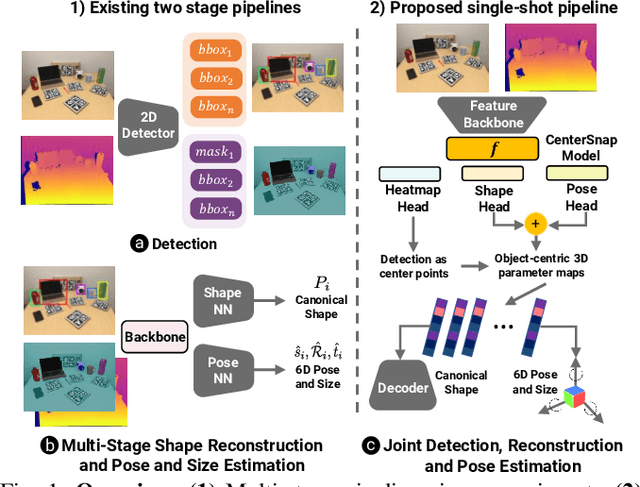
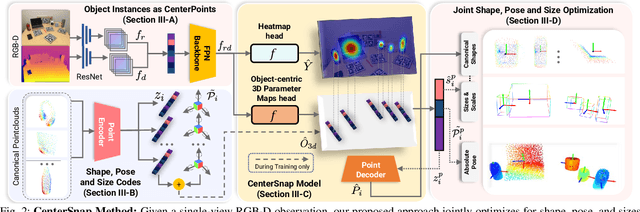
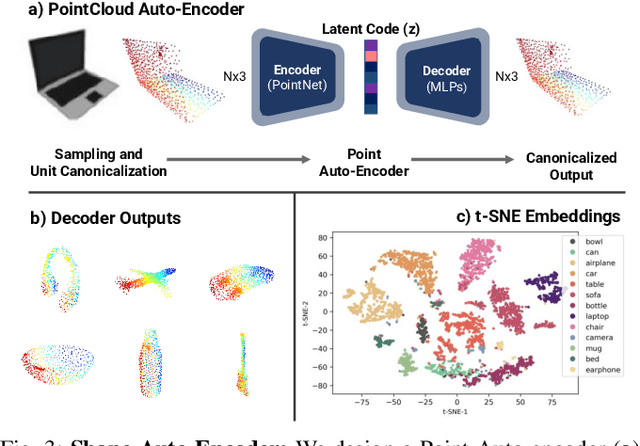
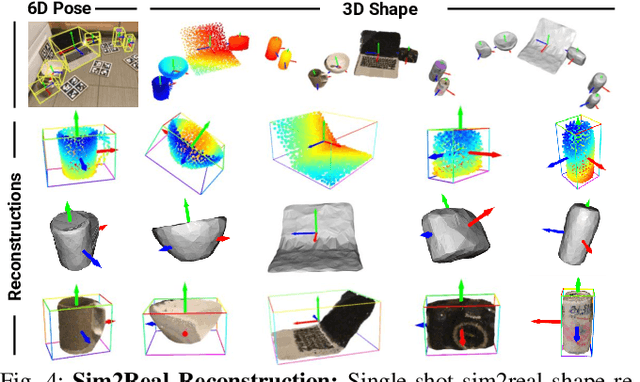
This paper studies the complex task of simultaneous multi-object 3D reconstruction, 6D pose and size estimation from a single-view RGB-D observation. In contrast to instance-level pose estimation, we focus on a more challenging problem where CAD models are not available at inference time. Existing approaches mainly follow a complex multi-stage pipeline which first localizes and detects each object instance in the image and then regresses to either their 3D meshes or 6D poses. These approaches suffer from high-computational cost and low performance in complex multi-object scenarios, where occlusions can be present. Hence, we present a simple one-stage approach to predict both the 3D shape and estimate the 6D pose and size jointly in a bounding-box free manner. In particular, our method treats object instances as spatial centers where each center denotes the complete shape of an object along with its 6D pose and size. Through this per-pixel representation, our approach can reconstruct in real-time (40 FPS) multiple novel object instances and predict their 6D pose and sizes in a single-forward pass. Through extensive experiments, we demonstrate that our approach significantly outperforms all shape completion and categorical 6D pose and size estimation baselines on multi-object ShapeNet and NOCS datasets respectively with a 12.6% absolute improvement in mAP for 6D pose for novel real-world object instances.
A Learned Stereo Depth System for Robotic Manipulation in Homes
Sep 23, 2021

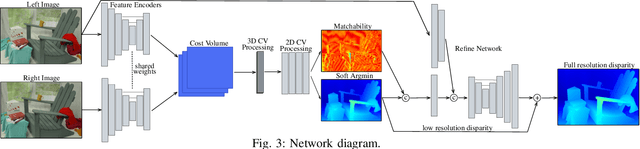

We present a passive stereo depth system that produces dense and accurate point clouds optimized for human environments, including dark, textureless, thin, reflective and specular surfaces and objects, at 2560x2048 resolution, with 384 disparities, in 30 ms. The system consists of an algorithm combining learned stereo matching with engineered filtering, a training and data-mixing methodology, and a sensor hardware design. Our architecture is 15x faster than approaches that perform similarly on the Middlebury and Flying Things Stereo Benchmarks. To effectively supervise the training of this model, we combine real data labelled using off-the-shelf depth sensors, as well as a number of different rendered, simulated labeled datasets. We demonstrate the efficacy of our system by presenting a large number of qualitative results in the form of depth maps and point-clouds, experiments validating the metric accuracy of our system and comparisons to other sensors on challenging objects and scenes. We also show the competitiveness of our algorithm compared to state-of-the-art learned models using the Middlebury and FlyingThings datasets.
SimNet: Enabling Robust Unknown Object Manipulation from Pure Synthetic Data via Stereo
Jun 30, 2021
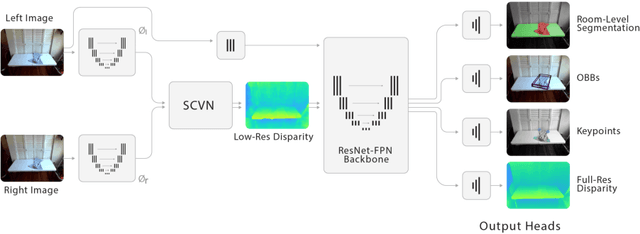

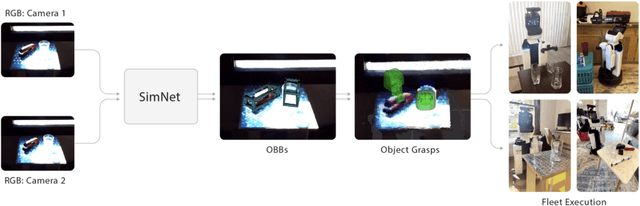
Robot manipulation of unknown objects in unstructured environments is a challenging problem due to the variety of shapes, materials, arrangements and lighting conditions. Even with large-scale real-world data collection, robust perception and manipulation of transparent and reflective objects across various lighting conditions remain challenging. To address these challenges we propose an approach to performing sim-to-real transfer of robotic perception. The underlying model, SimNet, is trained as a single multi-headed neural network using simulated stereo data as input and simulated object segmentation masks, 3D oriented bounding boxes (OBBs), object keypoints, and disparity as output. A key component of SimNet is the incorporation of a learned stereo sub-network that predicts disparity. SimNet is evaluated on 2D car detection, unknown object detection, and deformable object keypoint detection and significantly outperforms a baseline that uses a structured light RGB-D sensor. By inferring grasp positions using the OBB and keypoint predictions, SimNet can be used to perform end-to-end manipulation of unknown objects in both easy and hard scenarios using our fleet of Toyota HSR robots in four home environments. In unknown object grasping experiments, the predictions from the baseline RGB-D network and SimNet enable successful grasps of most of the easy objects. However, the RGB-D baseline only grasps 35% of the hard (e.g., transparent) objects, while SimNet grasps 95%, suggesting that SimNet can enable robust manipulation of unknown objects, including transparent objects, in unknown environments.