 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Attention in Video Diffusion Transformers
Apr 14, 2025We conduct an in-depth analysis of attention in video diffusion transformers (VDiTs) and report a number of novel findings. We identify three key properties of attention in VDiTs: Structure, Sparsity, and Sinks. Structure: We observe that attention patterns across different VDiTs exhibit similar structure across different prompts, and that we can make use of the similarity of attention patterns to unlock video editing via self-attention map transfer. Sparse: We study attention sparsity in VDiTs, finding that proposed sparsity methods do not work for all VDiTs, because some layers that are seemingly sparse cannot be sparsified. Sinks: We make the first study of attention sinks in VDiTs, comparing and contrasting them to attention sinks in language models. We propose a number of future directions that can make use of our insights to improve the efficiency-quality Pareto frontier for VDiTs.
Video Prediction Models as Rewards for Reinforcement Learning
May 23, 2023



Specifying reward signals that allow agents to learn complex behaviors is a long-standing challenge in reinforcement learning. A promising approach is to extract preferences for behaviors from unlabeled videos, which are widely available on the internet. We present Video Prediction Rewards (VIPER), an algorithm that leverages pretrained video prediction models as action-free reward signals for reinforcement learning. Specifically, we first train an autoregressive transformer on expert videos and then use the video prediction likelihoods as reward signals for a reinforcement learning agent. VIPER enables expert-level control without programmatic task rewards across a wide range of DMC, Atari, and RLBench tasks. Moreover, generalization of the video prediction model allows us to derive rewards for an out-of-distribution environment where no expert data is available, enabling cross-embodiment generalization for tabletop manipulation. We see our work as starting point for scalable reward specification from unlabeled videos that will benefit from the rapid advances in generative modeling. Source code and datasets are available on the project website: https://escontrela.me
VectorFusion: Text-to-SVG by Abstracting Pixel-Based Diffusion Models
Nov 21, 2022Diffusion models have shown impressive results in text-to-image synthesis. Using massive datasets of captioned images, diffusion models learn to generate raster images of highly diverse objects and scenes. However, designers frequently use vector representations of images like Scalable Vector Graphics (SVGs) for digital icons or art. Vector graphics can be scaled to any size, and are compact. We show that a text-conditioned diffusion model trained on pixel representations of images can be used to generate SVG-exportable vector graphics. We do so without access to large datasets of captioned SVGs. By optimizing a differentiable vector graphics rasterizer, our method, VectorFusion, distills abstract semantic knowledge out of a pretrained diffusion model. Inspired by recent text-to-3D work, we learn an SVG consistent with a caption using Score Distillation Sampling. To accelerate generation and improve fidelity, VectorFusion also initializes from an image sample. Experiments show greater quality than prior work, and demonstrate a range of styles including pixel art and sketches. See our project webpage at https://ajayj.com/vectorfusion .
DreamFusion: Text-to-3D using 2D Diffusion
Sep 29, 2022


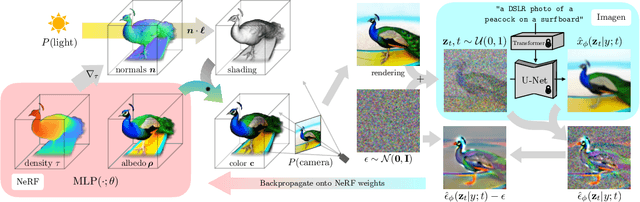
Recent breakthroughs in text-to-image synthesis have been driven by diffusion models trained on billions of image-text pairs. Adapting this approach to 3D synthesis would require large-scale datasets of labeled 3D data and efficient architectures for denoising 3D data, neither of which currently exist. In this work, we circumvent these limitations by using a pretrained 2D text-to-image diffusion model to perform text-to-3D synthesis. We introduce a loss based on probability density distillation that enables the use of a 2D diffusion model as a prior for optimization of a parametric image generator. Using this loss in a DeepDream-like procedure, we optimize a randomly-initialized 3D model (a Neural Radiance Field, or NeRF) via gradient descent such that its 2D renderings from random angles achieve a low loss. The resulting 3D model of the given text can be viewed from any angle, relit by arbitrary illumination, or composited into any 3D environment. Our approach requires no 3D training data and no modifications to the image diffusion model, demonstrating the effectiveness of pretrained image diffusion models as priors.
AdaCat: Adaptive Categorical Discretization for Autoregressive Models
Aug 03, 2022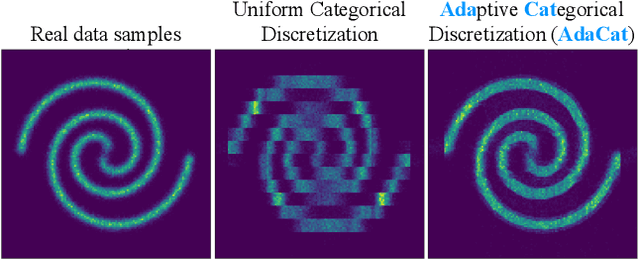
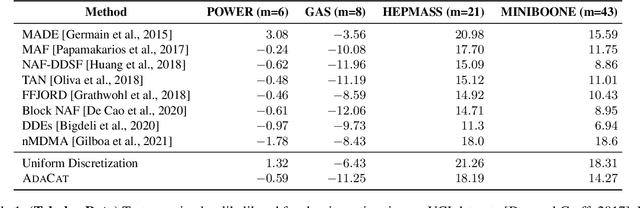
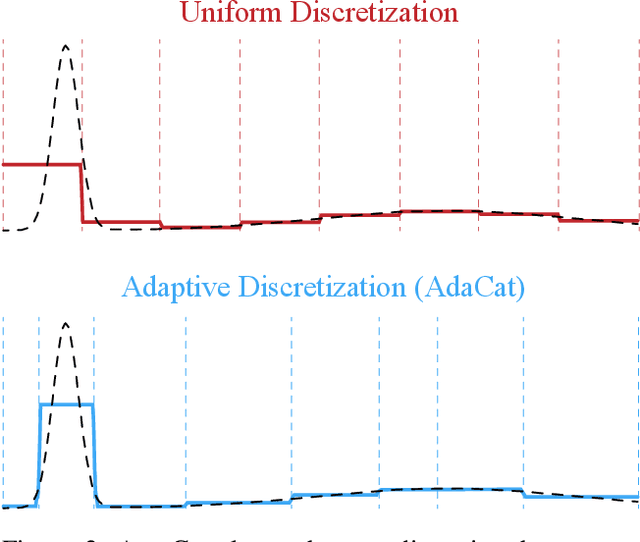
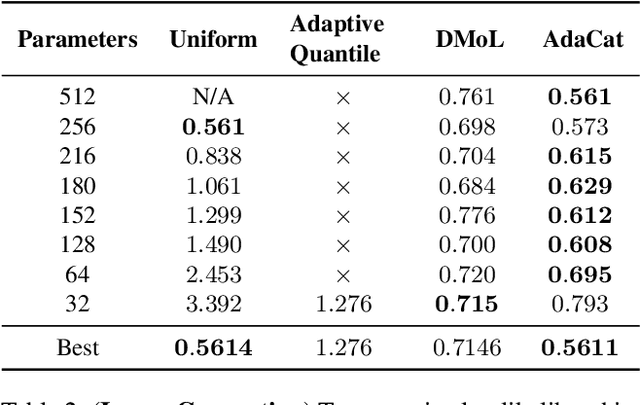
Autoregressive generative models can estimate complex continuous data distributions, like trajectory rollouts in an RL environment, image intensities, and audio. Most state-of-the-art models discretize continuous data into several bins and use categorical distributions over the bins to approximate the continuous data distribution. The advantage is that the categorical distribution can easily express multiple modes and are straightforward to optimize. However, such approximation cannot express sharp changes in density without using significantly more bins, making it parameter inefficient. We propose an efficient, expressive, multimodal parameterization called Adaptive Categorical Discretization (AdaCat). AdaCat discretizes each dimension of an autoregressive model adaptively, which allows the model to allocate density to fine intervals of interest, improving parameter efficiency. AdaCat generalizes both categoricals and quantile-based regression. AdaCat is a simple add-on to any discretization-based distribution estimator. In experiments, AdaCat improves density estimation for real-world tabular data, images, audio, and trajectories, and improves planning in model-based offline RL.
Zero-Shot Text-Guided Object Generation with Dream Fields
Dec 02, 2021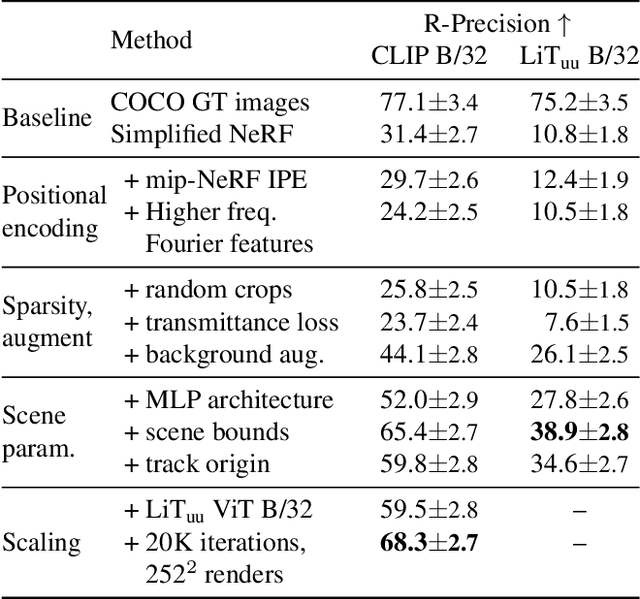

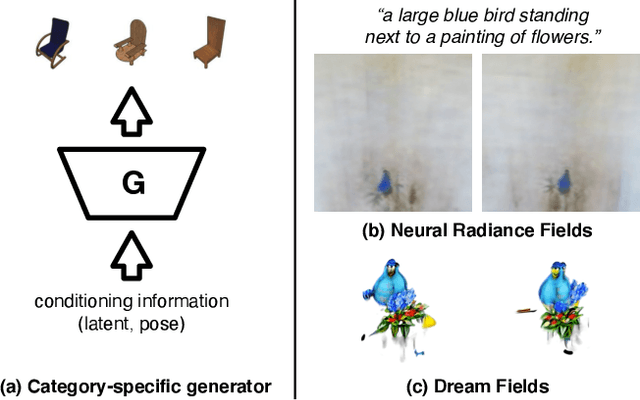
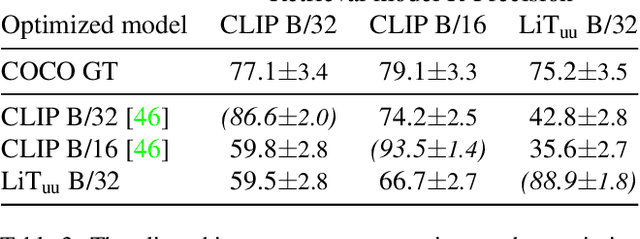
We combine neural rendering with multi-modal image and text representations to synthesize diverse 3D objects solely from natural language descriptions. Our method, Dream Fields, can generate the geometry and color of a wide range of objects without 3D supervision. Due to the scarcity of diverse, captioned 3D data, prior methods only generate objects from a handful of categories, such as ShapeNet. Instead, we guide generation with image-text models pre-trained on large datasets of captioned images from the web. Our method optimizes a Neural Radiance Field from many camera views so that rendered images score highly with a target caption according to a pre-trained CLIP model. To improve fidelity and visual quality, we introduce simple geometric priors, including sparsity-inducing transmittance regularization, scene bounds, and new MLP architectures. In experiments, Dream Fields produce realistic, multi-view consistent object geometry and color from a variety of natural language captions.
Putting NeRF on a Diet: Semantically Consistent Few-Shot View Synthesis
Apr 01, 2021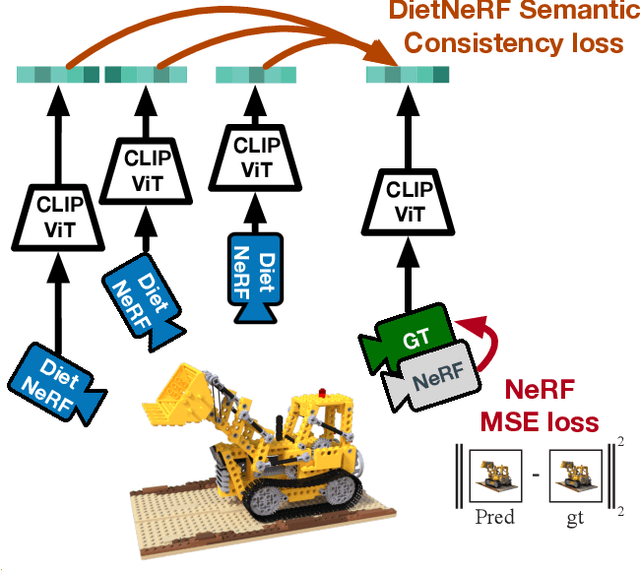
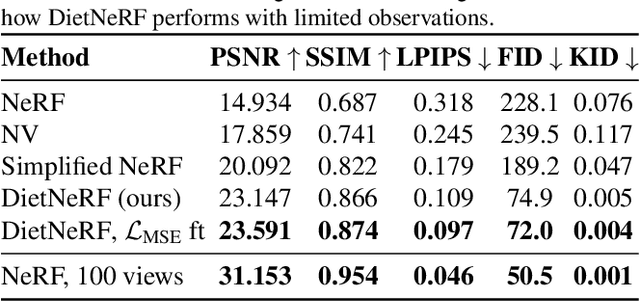

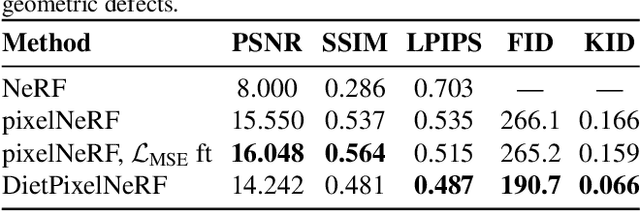
We present DietNeRF, a 3D neural scene representation estimated from a few images. Neural Radiance Fields (NeRF) learn a continuous volumetric representation of a scene through multi-view consistency, and can be rendered from novel viewpoints by ray casting. While NeRF has an impressive ability to reconstruct geometry and fine details given many images, up to 100 for challenging 360{\deg} scenes, it often finds a degenerate solution to its image reconstruction objective when only a few input views are available. To improve few-shot quality, we propose DietNeRF. We introduce an auxiliary semantic consistency loss that encourages realistic renderings at novel poses. DietNeRF is trained on individual scenes to (1) correctly render given input views from the same pose, and (2) match high-level semantic attributes across different, random poses. Our semantic loss allows us to supervise DietNeRF from arbitrary poses. We extract these semantics using a pre-trained visual encoder such as CLIP, a Vision Transformer trained on hundreds of millions of diverse single-view, 2D photographs mined from the web with natural language supervision. In experiments, DietNeRF improves the perceptual quality of few-shot view synthesis when learned from scratch, can render novel views with as few as one observed image when pre-trained on a multi-view dataset, and produces plausible completions of completely unobserved regions.
Contrastive Code Representation Learning
Jul 09, 2020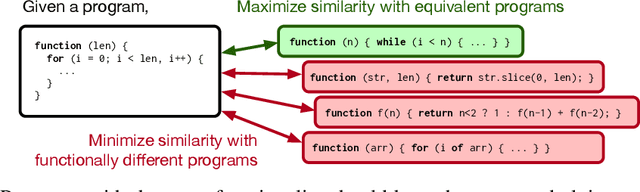
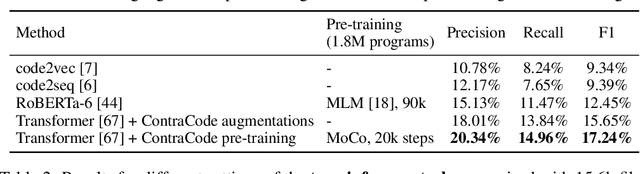
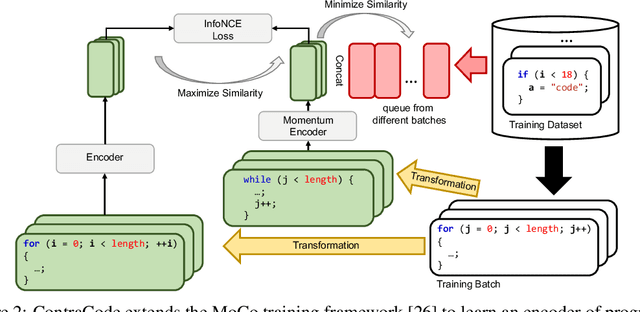
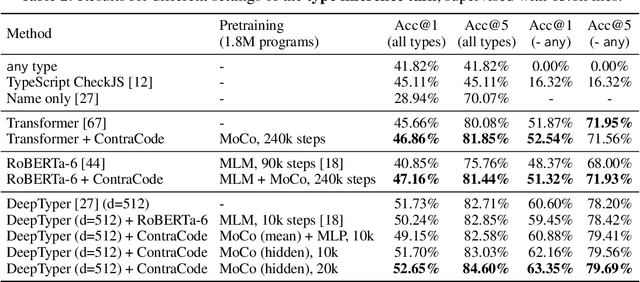
Machine-aided programming tools such as type predictors and code summarizers are increasingly learning-based. However, most code representation learning approaches rely on supervised learning with task-specific annotated datasets. We propose Contrastive Code Representation Learning (ContraCode), a self-supervised algorithm for learning task-agnostic semantic representations of programs via contrastive learning. Our approach uses no human-provided labels, relying only on the raw text of programs. In particular, we design an unsupervised pretext task by generating textually divergent copies of source functions via automated source-to-source compiler transforms that preserve semantics. We train a neural model to identify variants of an anchor program within a large batch of negatives. To solve this task, the network must extract program features representing the functionality, not form, of the program. This is the first application of instance discrimination to code representation learning to our knowledge. We pre-train models over 1.8m unannotated JavaScript methods mined from GitHub. ContraCode pre-training improves code summarization accuracy by 7.9% over supervised approaches and 4.8% over RoBERTa pre-training. Moreover, our approach is agnostic to model architecture; for a type inference task, contrastive pre-training consistently improves the accuracy of existing baselines.
Locally Masked Convolution for Autoregressive Models
Jun 27, 2020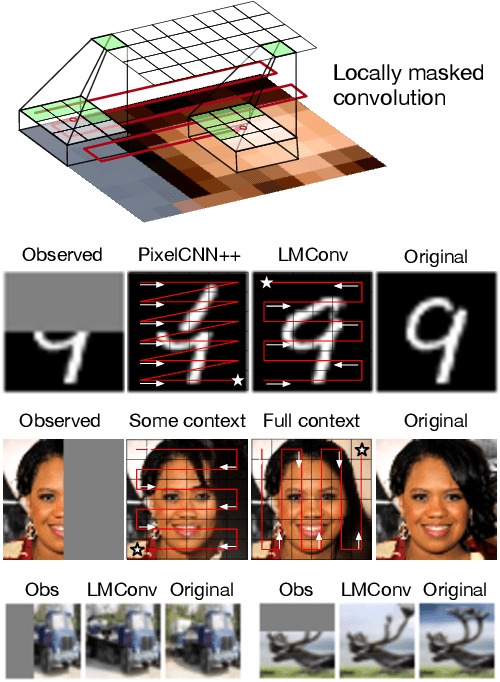
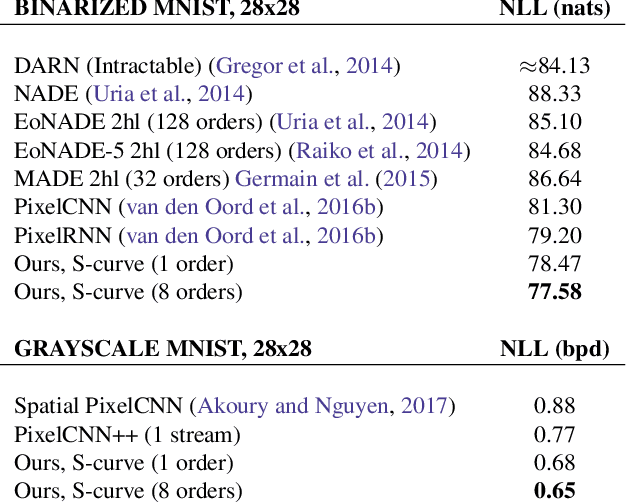
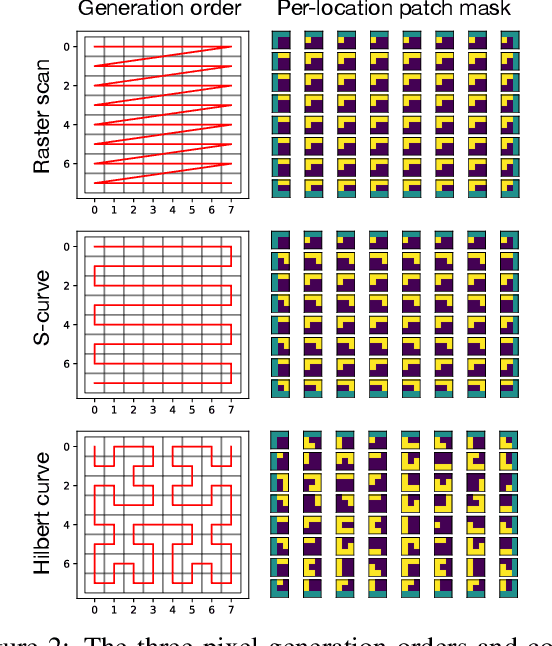

High-dimensional generative models have many applications including image compression, multimedia generation, anomaly detection and data completion. State-of-the-art estimators for natural images are autoregressive, decomposing the joint distribution over pixels into a product of conditionals parameterized by a deep neural network, e.g. a convolutional neural network such as the PixelCNN. However, PixelCNNs only model a single decomposition of the joint, and only a single generation order is efficient. For tasks such as image completion, these models are unable to use much of the observed context. To generate data in arbitrary orders, we introduce LMConv: a simple modification to the standard 2D convolution that allows arbitrary masks to be applied to the weights at each location in the image. Using LMConv, we learn an ensemble of distribution estimators that share parameters but differ in generation order, achieving improved performance on whole-image density estimation (2.89 bpd on unconditional CIFAR10), as well as globally coherent image completions. Our code is available at https://ajayjain.github.io/lmconv.
Denoising Diffusion Probabilistic Models
Jun 19, 2020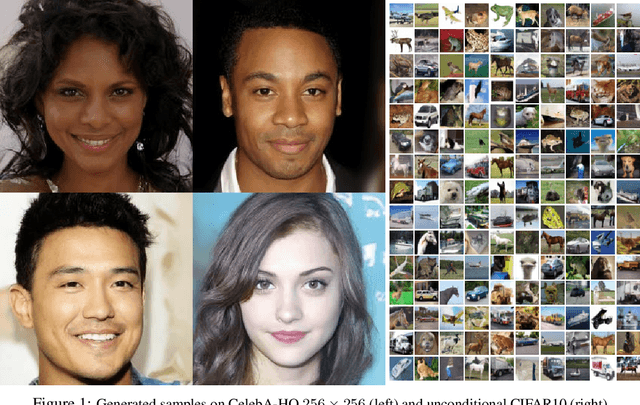
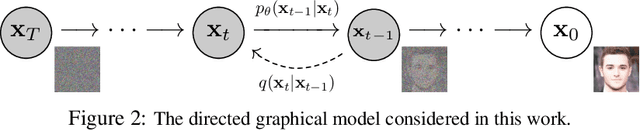
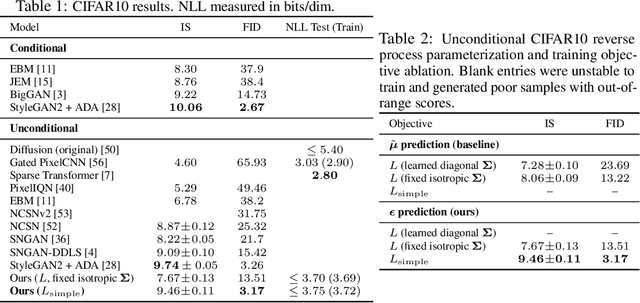

We present high quality image synthesis results using diffusion probabilistic models, a class of latent variable models inspired by considerations from nonequilibrium thermodynamics. Our best results are obtained by training on a weighted variational bound designed according to a novel connection between diffusion probabilistic models and denoising score matching with Langevin dynamics, and our models naturally admit a progressive lossy decompression scheme that can be interpreted as a generalization of autoregressive decoding. On the unconditional CIFAR10 dataset, we obtain an Inception score of 9.46 and a state-of-the-art FID score of 3.17. On 256x256 LSUN, we obtain sample quality similar to ProgressiveGAN. Our implementation is available at https://github.com/hojonathanho/diffusion