 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Call for Collaborative Intelligence: Why Human-Agent Systems Should Precede AI Autonomy
Jun 11, 2025Recent improvements in large language models (LLMs) have led many researchers to focus on building fully autonomous AI agents. This position paper questions whether this approach is the right path forward, as these autonomous systems still have problems with reliability, transparency, and understanding the actual requirements of human. We suggest a different approach: LLM-based Human-Agent Systems (LLM-HAS), where AI works with humans rather than replacing them. By keeping human involved to provide guidance, answer questions, and maintain control, these systems can be more trustworthy and adaptable. Looking at examples from healthcare, finance, and software development, we show how human-AI teamwork can handle complex tasks better than AI working alone. We also discuss the challenges of building these collaborative systems and offer practical solutions. This paper argues that progress in AI should not be measured by how independent systems become, but by how well they can work with humans. The most promising future for AI is not in systems that take over human roles, but in those that enhance human capabilities through meaningful partnership.
PersonaAgent: When Large Language Model Agents Meet Personalization at Test Time
Jun 06, 2025Large Language Model (LLM) empowered agents have recently emerged as advanced paradigms that exhibit impressive capabilities in a wide range of domains and tasks. Despite their potential, current LLM agents often adopt a one-size-fits-all approach, lacking the flexibility to respond to users' varying needs and preferences. This limitation motivates us to develop PersonaAgent, the first personalized LLM agent framework designed to address versatile personalization tasks. Specifically, PersonaAgent integrates two complementary components - a personalized memory module that includes episodic and semantic memory mechanisms; a personalized action module that enables the agent to perform tool actions tailored to the user. At the core, the persona (defined as unique system prompt for each user) functions as an intermediary: it leverages insights from personalized memory to control agent actions, while the outcomes of these actions in turn refine the memory. Based on the framework, we propose a test-time user-preference alignment strategy that simulate the latest n interactions to optimize the persona prompt, ensuring real-time user preference alignment through textual loss feedback between simulated and ground-truth responses. Experimental evaluations demonstrate that PersonaAgent significantly outperforms other baseline methods by not only personalizing the action space effectively but also scaling during test-time real-world applications. These results underscore the feasibility and potential of our approach in delivering tailored, dynamic user experiences.
Lifelong Evolution: Collaborative Learning between Large and Small Language Models for Continuous Emergent Fake News Detection
Jun 05, 2025The widespread dissemination of fake news on social media has significantly impacted society, resulting in serious consequences. Conventional deep learning methodologies employing small language models (SLMs) suffer from extensive supervised training requirements and difficulties adapting to evolving news environments due to data scarcity and distribution shifts. Large language models (LLMs), despite robust zero-shot capabilities, fall short in accurately detecting fake news owing to outdated knowledge and the absence of suitable demonstrations. In this paper, we propose a novel Continuous Collaborative Emergent Fake News Detection (C$^2$EFND) framework to address these challenges. The C$^2$EFND framework strategically leverages both LLMs' generalization power and SLMs' classification expertise via a multi-round collaborative learning framework. We further introduce a lifelong knowledge editing module based on a Mixture-of-Experts architecture to incrementally update LLMs and a replay-based continue learning method to ensure SLMs retain prior knowledge without retraining entirely. Extensive experiments on Pheme and Twitter16 datasets demonstrate that C$^2$EFND significantly outperforms existed methods, effectively improving detection accuracy and adaptability in continuous emergent fake news scenarios.
Cold-Start Recommendation with Knowledge-Guided Retrieval-Augmented Generation
May 27, 2025Cold-start items remain a persistent challenge in recommender systems due to their lack of historical user interactions, which collaborative models rely on. While recent zero-shot methods leverage large language models (LLMs) to address this, they often struggle with sparse metadata and hallucinated or incomplete knowledge. We propose ColdRAG, a retrieval-augmented generation approach that builds a domain-specific knowledge graph dynamically to enhance LLM-based recommendation in cold-start scenarios, without requiring task-specific fine-tuning. ColdRAG begins by converting structured item attributes into rich natural-language profiles, from which it extracts entities and relationships to construct a unified knowledge graph capturing item semantics. Given a user's interaction history, it scores edges in the graph using an LLM, retrieves candidate items with supporting evidence, and prompts the LLM to rank them. By enabling multi-hop reasoning over this graph, ColdRAG grounds recommendations in verifiable evidence, reducing hallucinations and strengthening semantic connections. Experiments on three public benchmarks demonstrate that ColdRAG surpasses existing zero-shot baselines in both Recall and NDCG. This framework offers a practical solution to cold-start recommendation by combining knowledge-graph reasoning with retrieval-augmented LLM generation.
MARCO: Meta-Reflection with Cross-Referencing for Code Reasoning
May 23, 2025The ability to reason is one of the most fundamental capabilities of large language models (LLMs), enabling a wide range of downstream tasks through sophisticated problem-solving. A critical aspect of this is code reasoning, which involves logical reasoning with formal languages (i.e., programming code). In this paper, we enhance this capability of LLMs by exploring the following question: how can an LLM agent become progressively smarter in code reasoning with each solution it proposes, thereby achieving substantial cumulative improvement? Most existing research takes a static perspective, focusing on isolated problem-solving using frozen LLMs. In contrast, we adopt a cognitive-evolving perspective and propose a novel framework named Meta-Reflection with Cross-Referencing (MARCO) that enables the LLM to evolve dynamically during inference through self-improvement. From the perspective of human cognitive development, we leverage both knowledge accumulation and lesson sharing. In particular, to accumulate knowledge during problem-solving, we propose meta-reflection that reflects on the reasoning paths of the current problem to obtain knowledge and experience for future consideration. Moreover, to effectively utilize the lessons from other agents, we propose cross-referencing that incorporates the solution and feedback from other agents into the current problem-solving process. We conduct experiments across various datasets in code reasoning, and the results demonstrate the effectiveness of MARCO.
Dynamic Text Bundling Supervision for Zero-Shot Inference on Text-Attributed Graphs
May 23, 2025Large language models (LLMs) have been used in many zero-shot learning problems, with their strong generalization ability. Recently, adopting LLMs in text-attributed graphs (TAGs) has drawn increasing attention. However, the adoption of LLMs faces two major challenges: limited information on graph structure and unreliable responses. LLMs struggle with text attributes isolated from the graph topology. Worse still, they yield unreliable predictions due to both information insufficiency and the inherent weakness of LLMs (e.g., hallucination). Towards this end, this paper proposes a novel method named Dynamic Text Bundling Supervision (DENSE) that queries LLMs with bundles of texts to obtain bundle-level labels and uses these labels to supervise graph neural networks. Specifically, we sample a set of bundles, each containing a set of nodes with corresponding texts of close proximity. We then query LLMs with the bundled texts to obtain the label of each bundle. Subsequently, the bundle labels are used to supervise the optimization of graph neural networks, and the bundles are further refined to exclude noisy items. To justify our design, we also provide theoretical analysis of the proposed method. Extensive experiments across ten datasets validate the effectiveness of the proposed method.
A Personalized Conversational Benchmark: Towards Simulating Personalized Conversations
May 20, 2025
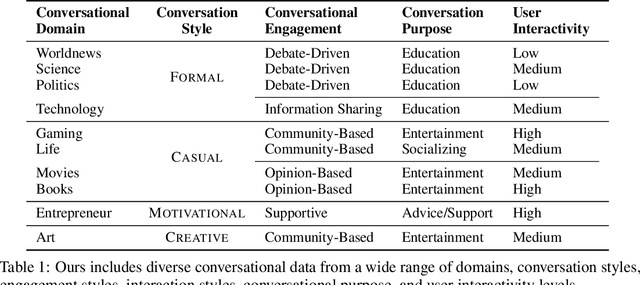


We present PersonaConvBench, a large-scale benchmark for evaluating personalized reasoning and generation in multi-turn conversations with large language models (LLMs). Unlike existing work that focuses on either personalization or conversational structure in isolation, PersonaConvBench integrates both, offering three core tasks: sentence classification, impact regression, and user-centric text generation across ten diverse Reddit-based domains. This design enables systematic analysis of how personalized conversational context shapes LLM outputs in realistic multi-user scenarios. We benchmark several commercial and open-source LLMs under a unified prompting setup and observe that incorporating personalized history yields substantial performance improvements, including a 198 percent relative gain over the best non-conversational baseline in sentiment classification. By releasing PersonaConvBench with evaluations and code, we aim to support research on LLMs that adapt to individual styles, track long-term context, and produce contextually rich, engaging responses.
Your Offline Policy is Not Trustworthy: Bilevel Reinforcement Learning for Sequential Portfolio Optimization
May 19, 2025Reinforcement learning (RL) has shown significant promise for sequential portfolio optimization tasks, such as stock trading, where the objective is to maximize cumulative returns while minimizing risks using historical data. However, traditional RL approaches often produce policies that merely memorize the optimal yet impractical buying and selling behaviors within the fixed dataset. These offline policies are less generalizable as they fail to account for the non-stationary nature of the market. Our approach, MetaTrader, frames portfolio optimization as a new type of partial-offline RL problem and makes two technical contributions. First, MetaTrader employs a bilevel learning framework that explicitly trains the RL agent to improve both in-domain profits on the original dataset and out-of-domain performance across diverse transformations of the raw financial data. Second, our approach incorporates a new temporal difference (TD) method that approximates worst-case TD estimates from a batch of transformed TD targets, addressing the value overestimation issue that is particularly challenging in scenarios with limited offline data. Our empirical results on two public stock datasets show that MetaTrader outperforms existing methods, including both RL-based approaches and traditional stock prediction models.
Reward Inside the Model: A Lightweight Hidden-State Reward Model for LLM's Best-of-N sampling
May 18, 2025High-quality reward models are crucial for unlocking the reasoning potential of large language models (LLMs), with best-of-N voting demonstrating significant performance gains. However, current reward models, which typically operate on the textual output of LLMs, are computationally expensive and parameter-heavy, limiting their real-world applications. We introduce the Efficient Linear Hidden State Reward (ELHSR) model - a novel, highly parameter-efficient approach that leverages the rich information embedded in LLM hidden states to address these issues. ELHSR systematically outperform baselines with less than 0.005% of the parameters of baselines, requiring only a few samples for training. ELHSR also achieves orders-of-magnitude efficiency improvement with significantly less time and fewer FLOPs per sample than baseline reward models. Moreover, ELHSR exhibits robust performance even when trained only on logits, extending its applicability to some closed-source LLMs. In addition, ELHSR can also be combined with traditional reward models to achieve additional performance gains.
T-T: Table Transformer for Tagging-based Aspect Sentiment Triplet Extraction
May 08, 2025Aspect sentiment triplet extraction (ASTE) aims to extract triplets composed of aspect terms, opinion terms, and sentiment polarities from given sentences. The table tagging method is a popular approach to addressing this task, which encodes a sentence into a 2-dimensional table, allowing for the tagging of relations between any two words. Previous efforts have focused on designing various downstream relation learning modules to better capture interactions between tokens in the table, revealing that a stronger capability to capture relations can lead to greater improvements in the model. Motivated by this, we attempt to directly utilize transformer layers as downstream relation learning modules. Due to the powerful semantic modeling capability of transformers, it is foreseeable that this will lead to excellent improvement. However, owing to the quadratic relation between the length of the table and the length of the input sentence sequence, using transformers directly faces two challenges: overly long table sequences and unfair local attention interaction. To address these challenges, we propose a novel Table-Transformer (T-T) for the tagging-based ASTE method. Specifically, we introduce a stripe attention mechanism with a loop-shift strategy to tackle these challenges. The former modifies the global attention mechanism to only attend to a 2-dimensional local attention window, while the latter facilitates interaction between different attention windows. Extensive and comprehensive experiments demonstrate that the T-T, as a downstream relation learning module, achieves state-of-the-art performance with lower computational costs.