 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvo-Attacker: Memory-Augmented Reinforcement Learning for Long-Horizon Tool Attacks on LLM-MAS
May 25, 2026While Large Language Model-based Multi-Agent Systems (LLM-MAS) demonstrate remarkable capabilities in solving complex tasks by orchestrating specialized agents and external tools, the implicit trust in tool outputs creates a critical attack surface. Existing tool attacks are limited by domain specificity or fixed and static templates. To address these challenges, we propose Evo-Attacker, which formulates the tool attack as a self-evolving, memory-augmented reinforcement learning process. Evo-Attacker constructs a dynamic attack memory and employs deliberative reasoning to retrieve adversarial patterns and strategize modifying interventions at critical moments. Furthermore, we introduce Attack-Flow GRPO to optimize intermediate reasoning steps via terminal outcomes, addressing the long-horizon credit assignment challenge. Comprehensive experiments demonstrate that Evo-Attacker consistently outperforms baselines, highlighting its generalization and evolutionary capabilities and the urgent need for defensive tool safeguards.
PhySE: A Psychological Framework for Real-Time AR-LLM Social Engineering Attacks
Apr 25, 2026The emerging threat of AR-LLM-based Social Engineering (AR-LLM-SE) attacks (e.g. SEAR) poses a significant risk to real-world social interactions. In such an attack, a malicious actor uses Augmented Reality (AR) glasses to capture a target visual and vocal data. A Large Language Model (LLM) then analyzes this data to identify the individual and generate a detailed social profile. Subsequently, LLM-powered agents employ social engineering strategies, providing real-time conversation suggestions, to gain the target trust and ultimately execute phishing or other malicious acts. Despite its potential, the practical application of AR-LLM-SE faces two major bottlenecks, (1) Cold-start personalization, Current Retrieval-Augmented Generation (RAG) methods introduce critical delays in the earliest turns, slowing initial profile formation and disrupting real-time interaction, (2) Static Attack Strategies, Existing approaches rely on fixed-stage, handcrafted social engineering tactics that lack foundation in established psychological theory. To address these limitations, we propose PhySE, a novel framework with two core innovations, (1) VLM-Based SocialContext Training, To eliminate profiling delays, we efficiently pre-train a Visual Language Model (VLM) with social-context data, enabling rapid, on-the-fly profile generation, (2) Adaptive Psychological Agent, We introduce a psychological LLM that dynamically deploys distinct classes of psychological strategies based on target response, moving beyond static, handcrafted scripts. We evaluated PhySE through an IRB-approved user study with 60 participants, collecting a novel dataset of 360 annotated conversations across diverse social scenarios.
A2Eval: Agentic and Automated Evaluation for Embodied Brain
Feb 02, 2026Current embodied VLM evaluation relies on static, expert-defined, manually annotated benchmarks that exhibit severe redundancy and coverage imbalance. This labor intensive paradigm drains computational and annotation resources, inflates costs, and distorts model rankings, ultimately stifling iterative development. To address this, we propose Agentic Automatic Evaluation (A2Eval), the first agentic framework that automates benchmark curation and evaluation through two collaborative agents. The Data Agent autonomously induces capability dimensions and assembles a balanced, compact evaluation suite, while the Eval Agent synthesizes and validates executable evaluation pipelines, enabling fully autonomous, high-fidelity assessment. Evaluated across 10 benchmarks and 13 models, A2Eval compresses evaluation suites by 85%, reduces overall computational costs by 77%, and delivers a 4.6x speedup while preserving evaluation quality. Crucially, A2Eval corrects systematic ranking biases, improves human alignment to Spearman's rho=0.85, and maintains high ranking fidelity (Kendall's tau=0.81), establishing a new standard for high-fidelity, low-cost embodied assessment. Our code and data will be public soon.
Lifelong Evolution: Collaborative Learning between Large and Small Language Models for Continuous Emergent Fake News Detection
Jun 05, 2025The widespread dissemination of fake news on social media has significantly impacted society, resulting in serious consequences. Conventional deep learning methodologies employing small language models (SLMs) suffer from extensive supervised training requirements and difficulties adapting to evolving news environments due to data scarcity and distribution shifts. Large language models (LLMs), despite robust zero-shot capabilities, fall short in accurately detecting fake news owing to outdated knowledge and the absence of suitable demonstrations. In this paper, we propose a novel Continuous Collaborative Emergent Fake News Detection (C$^2$EFND) framework to address these challenges. The C$^2$EFND framework strategically leverages both LLMs' generalization power and SLMs' classification expertise via a multi-round collaborative learning framework. We further introduce a lifelong knowledge editing module based on a Mixture-of-Experts architecture to incrementally update LLMs and a replay-based continue learning method to ensure SLMs retain prior knowledge without retraining entirely. Extensive experiments on Pheme and Twitter16 datasets demonstrate that C$^2$EFND significantly outperforms existed methods, effectively improving detection accuracy and adaptability in continuous emergent fake news scenarios.
SEAR: A Multimodal Dataset for Analyzing AR-LLM-Driven Social Engineering Behaviors
May 30, 2025The SEAR Dataset is a novel multimodal resource designed to study the emerging threat of social engineering (SE) attacks orchestrated through augmented reality (AR) and multimodal large language models (LLMs). This dataset captures 180 annotated conversations across 60 participants in simulated adversarial scenarios, including meetings, classes and networking events. It comprises synchronized AR-captured visual/audio cues (e.g., facial expressions, vocal tones), environmental context, and curated social media profiles, alongside subjective metrics such as trust ratings and susceptibility assessments. Key findings reveal SEAR's alarming efficacy in eliciting compliance (e.g., 93.3% phishing link clicks, 85% call acceptance) and hijacking trust (76.7% post-interaction trust surge). The dataset supports research in detecting AR-driven SE attacks, designing defensive frameworks, and understanding multimodal adversarial manipulation. Rigorous ethical safeguards, including anonymization and IRB compliance, ensure responsible use. The SEAR dataset is available at https://github.com/INSLabCN/SEAR-Dataset.
Simultaneous Collision Detection and Force Estimation for Dynamic Quadrupedal Locomotion
Apr 24, 2025In this paper we address the simultaneous collision detection and force estimation problem for quadrupedal locomotion using joint encoder information and the robot dynamics only. We design an interacting multiple-model Kalman filter (IMM-KF) that estimates the external force exerted on the robot and multiple possible contact modes. The method is invariant to any gait pattern design. Our approach leverages pseudo-measurement information of the external forces based on the robot dynamics and encoder information. Based on the estimated contact mode and external force, we design a reflex motion and an admittance controller for the swing leg to avoid collisions by adjusting the leg's reference motion. Additionally, we implement a force-adaptive model predictive controller to enhance balancing. Simulation ablatation studies and experiments show the efficacy of the approach.
On the Feasibility of Using MultiModal LLMs to Execute AR Social Engineering Attacks
Apr 16, 2025Augmented Reality (AR) and Multimodal Large Language Models (LLMs) are rapidly evolving, providing unprecedented capabilities for human-computer interaction. However, their integration introduces a new attack surface for social engineering. In this paper, we systematically investigate the feasibility of orchestrating AR-driven Social Engineering attacks using Multimodal LLM for the first time, via our proposed SEAR framework, which operates through three key phases: (1) AR-based social context synthesis, which fuses Multimodal inputs (visual, auditory and environmental cues); (2) role-based Multimodal RAG (Retrieval-Augmented Generation), which dynamically retrieves and integrates contextual data while preserving character differentiation; and (3) ReInteract social engineering agents, which execute adaptive multiphase attack strategies through inference interaction loops. To verify SEAR, we conducted an IRB-approved study with 60 participants in three experimental configurations (unassisted, AR+LLM, and full SEAR pipeline) compiling a new dataset of 180 annotated conversations in simulated social scenarios. Our results show that SEAR is highly effective at eliciting high-risk behaviors (e.g., 93.3% of participants susceptible to email phishing). The framework was particularly effective in building trust, with 85% of targets willing to accept an attacker's call after an interaction. Also, we identified notable limitations such as ``occasionally artificial'' due to perceived authenticity gaps. This work provides proof-of-concept for AR-LLM driven social engineering attacks and insights for developing defensive countermeasures against next-generation augmented reality threats.
Collaborative Evolution: Multi-Round Learning Between Large and Small Language Models for Emergent Fake News Detection
Mar 27, 2025



The proliferation of fake news on social media platforms has exerted a substantial influence on society, leading to discernible impacts and deleterious consequences. Conventional deep learning methodologies employing small language models (SLMs) suffer from the necessity for extensive supervised training and the challenge of adapting to rapidly evolving circumstances. Large language models (LLMs), despite their robust zero-shot capabilities, have fallen short in effectively identifying fake news due to a lack of pertinent demonstrations and the dynamic nature of knowledge. In this paper, a novel framework Multi-Round Collaboration Detection (MRCD) is proposed to address these aforementioned limitations. The MRCD framework is capable of enjoying the merits from both LLMs and SLMs by integrating their generalization abilities and specialized functionalities, respectively. Our approach features a two-stage retrieval module that selects relevant and up-to-date demonstrations and knowledge, enhancing in-context learning for better detection of emerging news events. We further design a multi-round learning framework to ensure more reliable detection results. Our framework MRCD achieves SOTA results on two real-world datasets Pheme and Twitter16, with accuracy improvements of 7.4\% and 12.8\% compared to using only SLMs, which effectively addresses the limitations of current models and improves the detection of emergent fake news.
Physically-Feasible Reactive Synthesis for Terrain-Adaptive Locomotion via Trajectory Optimization and Symbolic Repair
Mar 05, 2025We propose an integrated planning framework for quadrupedal locomotion over dynamically changing, unforeseen terrains. Existing approaches either rely on heuristics for instantaneous foothold selection--compromising safety and versatility--or solve expensive trajectory optimization problems with complex terrain features and long time horizons. In contrast, our framework leverages reactive synthesis to generate correct-by-construction controllers at the symbolic level, and mixed-integer convex programming (MICP) for dynamic and physically feasible footstep planning for each symbolic transition. We use a high-level manager to reduce the large state space in synthesis by incorporating local environment information, improving synthesis scalability. To handle specifications that cannot be met due to dynamic infeasibility, and to minimize costly MICP solves, we leverage a symbolic repair process to generate only necessary symbolic transitions. During online execution, re-running the MICP with real-world terrain data, along with runtime symbolic repair, bridges the gap between offline synthesis and online execution. We demonstrate, in simulation, our framework's capabilities to discover missing locomotion skills and react promptly in safety-critical environments, such as scattered stepping stones and rebars.
Beyond Self-Talk: A Communication-Centric Survey of LLM-Based Multi-Agent Systems
Feb 20, 2025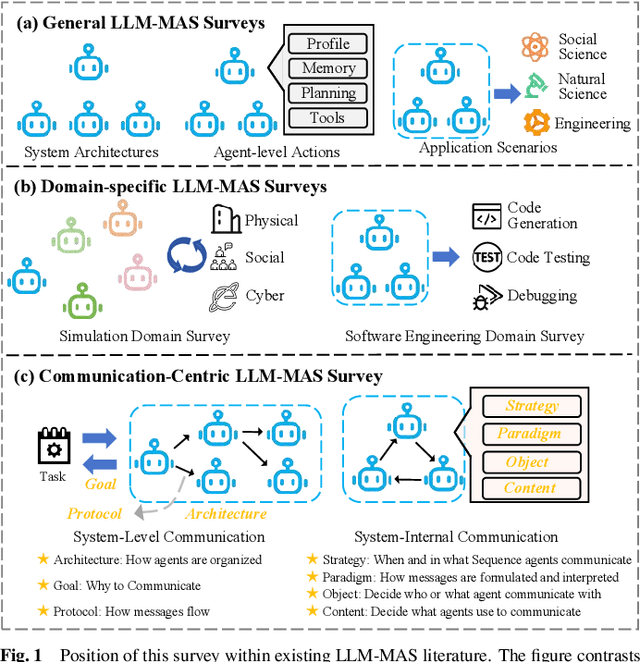
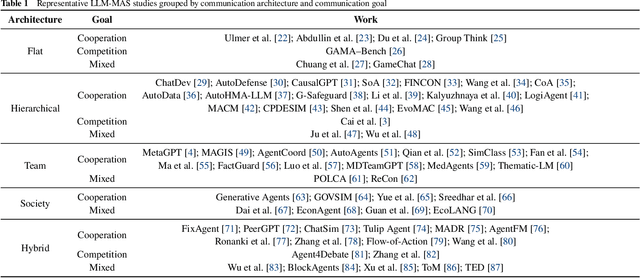
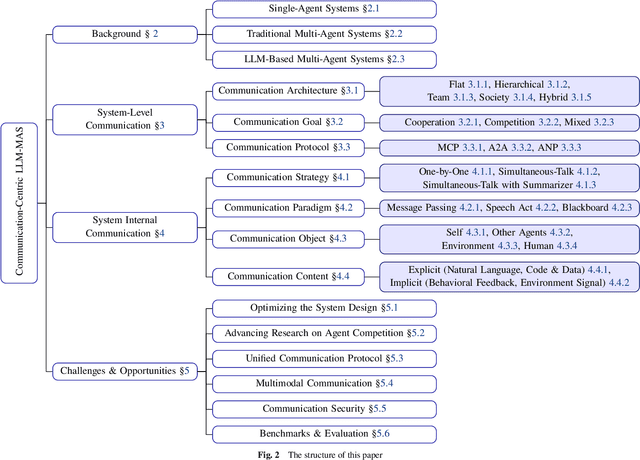
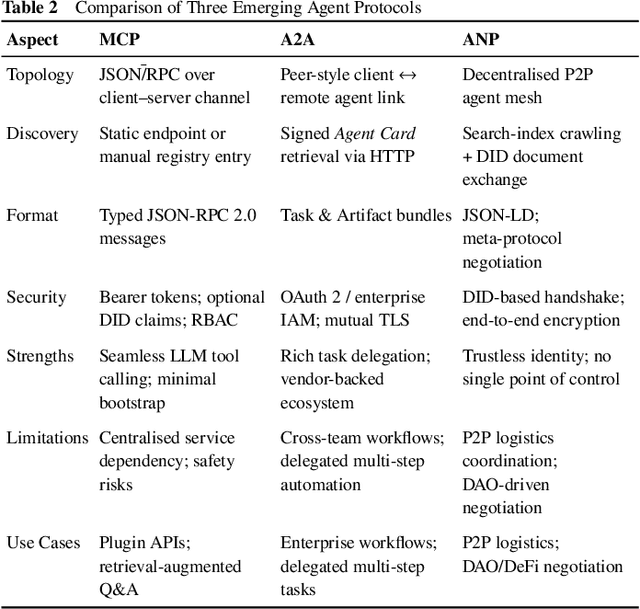
Large Language Models (LLMs) have recently demonstrated remarkable capabilities in reasoning, planning, and decision-making. Building upon these strengths, researchers have begun incorporating LLMs into multi-agent systems (MAS), where agents collaborate or compete through natural language interactions to tackle tasks beyond the scope of single-agent setups. In this survey, we present a communication-centric perspective on LLM-based multi-agent systems, examining key system-level features such as architecture design and communication goals, as well as internal mechanisms like communication strategies, paradigms, objects and content. We illustrate how these communication elements interplay to enable collective intelligence and flexible collaboration. Furthermore, we discuss prominent challenges, including scalability, security, and multimodal integration, and propose directions for future work to advance research in this emerging domain. Ultimately, this survey serves as a catalyst for further innovation, fostering more robust, scalable, and intelligent multi-agent systems across diverse application domains.