 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelta-JEPA: Learning Action-Sensitive World Models via Latent Difference Decoding
Jun 30, 2026Learning visual world models for planning requires compact latent dynamics that remain sensitive to actions, yet reconstruction-free joint-embedding objectives can collapse to action-insensitive representations. We propose Delta-JEPA, an end-to-end reconstruction-free world model that augments latent forward prediction with a Latent Difference Action Decoder (LDAD). Unlike inverse decoders that infer actions from concatenated endpoint embeddings, LDAD reconstructs the executed action from the latent displacement between consecutive observations. This displacement-level supervision directly regularizes transition geometry: adjacent embeddings cannot collapse without losing action information, and different actions are encouraged to induce distinguishable latent changes for rollout-based planning. Delta-JEPA uses only latent prediction and action reconstruction, avoiding pixel reconstruction and distribution-matching regularizers. Across four visual continuous-control tasks, Delta-JEPA improves planning over JEPA-based and representation-learning world model baselines. Ablations show that displacement-based action decoding is consistently more effective than endpoint concatenation, and action-sensitivity analyses show clearer action-conditioned latent responses. These results indicate that supervising latent differences is a simple and effective mechanism for collapse-resistant and action-sensitive world model learning.
RAVEN: A Regime-Aware Variable-context Expert Network for Financial Time Series Forecasting
Jun 23, 2026Financial time series forecasting presents structural challenges absent from standard benchmarks. Log-returns are non-stationary, exhibit exceptionally low signal-to-noise (SNR) ratios, and are governed by regime-dependent temporal dependencies. We identify a key limitation of state-of-the-art (SOTA) time series models in financial settings. A fixed context window is mismatched to the time-varying optimal look-back of non-stationary price processes. We propose the Regime-Aware Variable-context Expert Network (RAVEN), a Mixture-of-Experts framework designed to adaptively determine the temporal context for each input sample. Instead of relying on a fixed look-back horizon, RAVEN constructs a hierarchy of nested contiguous windows whose lengths are determined by the data itself. Specifically, RAVEN scores patches by learned importance in reverse chronological order and applies the Cumulative Importance Thresholding (CIT) mechanism to derive nested prefix windows, each routed to a scale-specialized expert. A Global Compressed Representation (GCR) branch runs in parallel over the full context, preserving global temporal coherence that local experts cannot guarantee. Because the nested routing induces structured overlap among expert inputs, we introduce a Correlation-Aware Weighting (CAW) to align variable-length expert outputs and penalize pairwise cosine similarity prior to aggregation. Experiments on cumulative log-return prediction (HS300, S&P500) and fund sales forecasting demonstrate that RAVEN achieves SOTA performances, improves Pearson correlation by 9.2% on HS300 and 20.2% on S&P500, and reduces MSE by 18.2% on fund sales forecasting, while achieving the best results in 14 of 16 metrics on four PEMS traffic benchmarks.
Omni IIE Bench: Benchmarking the Practical Capabilities of Image Editing Models
Mar 16, 2026While Instruction-based Image Editing (IIE) has achieved significant progress, existing benchmarks pursue task breadth via mixed evaluations. This paradigm obscures a critical failure mode crucial in professional applications: the inconsistent performance of models across tasks of varying semantic scales. To address this gap, we introduce Omni IIE Bench, a high-quality, human-annotated benchmark specifically designed to diagnose the editing consistency of IIE models in practical application scenarios. Omni IIE Bench features an innovative dual-track diagnostic design: (1) Single-turn Consistency, comprising shared-context task pairs of attribute modification and entity replacement; and (2) Multi-turn Coordination, involving continuous dialogue tasks that traverse semantic scales. The benchmark is constructed via an exceptionally rigorous multi-stage human filtering process, incorporating a quality standard enforced by computer vision graduate students and an industry relevance review conducted by professional designers. We perform a comprehensive evaluation of 8 mainstream IIE models using Omni IIE Bench. Our analysis quantifies, for the first time, a prevalent performance gap: nearly all models exhibit a significant performance degradation when transitioning from low-semantic-scale to high-semantic-scale tasks. Omni IIE Bench provides critical diagnostic tools and insights for the development of next-generation, more reliable, and stable IIE models.
RPO:Reinforcement Fine-Tuning with Partial Reasoning Optimization
Jan 27, 2026Within the domain of large language models, reinforcement fine-tuning algorithms necessitate the generation of a complete reasoning trajectory beginning from the input query, which incurs significant computational overhead during the rollout phase of training. To address this issue, we analyze the impact of different segments of the reasoning path on the correctness of the final result and, based on these insights, propose Reinforcement Fine-Tuning with Partial Reasoning Optimization (RPO), a plug-and-play reinforcement fine-tuning algorithm. Unlike traditional reinforcement fine-tuning algorithms that generate full reasoning paths, RPO trains the model by generating suffixes of the reasoning path using experience cache. During the rollout phase of training, RPO reduces token generation in this phase by approximately 95%, greatly lowering the theoretical time overhead. Compared with full-path reinforcement fine-tuning algorithms, RPO reduces the training time of the 1.5B model by 90% and the 7B model by 72%. At the same time, it can be integrated with typical algorithms such as GRPO and DAPO, enabling them to achieve training acceleration while maintaining performance comparable to the original algorithms. Our code is open-sourced at https://github.com/yhz5613813/RPO.
VDE Bench: Evaluating The Capability of Image Editing Models to Modify Visual Documents
Jan 27, 2026In recent years, multimodal image editing models have achieved substantial progress, enabling users to manipulate visual content through natural language in a flexible and interactive manner. Nevertheless, an important yet insufficiently explored research direction remains visual document image editing, which involves modifying textual content within images while faithfully preserving the original text style and background context. Existing approaches, including AnyText, GlyphControl, and TextCtrl, predominantly focus on English-language scenarios and documents with relatively sparse textual layouts, thereby failing to adequately address dense, structurally complex documents or non-Latin scripts such as Chinese. To bridge this gap, we propose \textbf{V}isual \textbf{D}oc \textbf{E}dit Bench(VDE Bench), a rigorously human-annotated and evaluated benchmark specifically designed to assess image editing models on multilingual and complex visual document editing tasks. The benchmark comprises a high-quality dataset encompassing densely textual documents in both English and Chinese, including academic papers, posters, presentation slides, examination materials, and newspapers. Furthermore, we introduce a decoupled evaluation framework that systematically quantifies editing performance at the OCR parsing level, enabling fine-grained assessment of text modification accuracy. Based on this benchmark, we conduct a comprehensive evaluation of representative state-of-the-art image editing models. Manual verification demonstrates a strong consistency between human judgments and automated evaluation metrics. VDE Bench constitutes the first systematic benchmark for evaluating image editing models on multilingual and densely textual visual documents.
Lifelong Evolution: Collaborative Learning between Large and Small Language Models for Continuous Emergent Fake News Detection
Jun 05, 2025The widespread dissemination of fake news on social media has significantly impacted society, resulting in serious consequences. Conventional deep learning methodologies employing small language models (SLMs) suffer from extensive supervised training requirements and difficulties adapting to evolving news environments due to data scarcity and distribution shifts. Large language models (LLMs), despite robust zero-shot capabilities, fall short in accurately detecting fake news owing to outdated knowledge and the absence of suitable demonstrations. In this paper, we propose a novel Continuous Collaborative Emergent Fake News Detection (C$^2$EFND) framework to address these challenges. The C$^2$EFND framework strategically leverages both LLMs' generalization power and SLMs' classification expertise via a multi-round collaborative learning framework. We further introduce a lifelong knowledge editing module based on a Mixture-of-Experts architecture to incrementally update LLMs and a replay-based continue learning method to ensure SLMs retain prior knowledge without retraining entirely. Extensive experiments on Pheme and Twitter16 datasets demonstrate that C$^2$EFND significantly outperforms existed methods, effectively improving detection accuracy and adaptability in continuous emergent fake news scenarios.
A Secure and Efficient Distributed Semantic Communication System for Heterogeneous Internet of Things Devices
Jul 19, 2024



Semantic communications have emerged as a promising solution to address the challenge of efficient communication in rapidly evolving and increasingly complex Internet of Things (IoT) networks. However, protecting the security of semantic communication systems within the distributed and heterogeneous IoT networks is critical issues that need to be addressed. We develop a secure and efficient distributed semantic communication system in IoT scenarios, focusing on three aspects: secure system maintenance, efficient system update, and privacy-preserving system usage. Firstly, we propose a blockchain-based interaction framework that ensures the integrity, authentication, and availability of interactions among IoT devices to securely maintain system. This framework includes a novel digital signature verification mechanism designed for semantic communications, enabling secure and efficient interactions with semantic communications. Secondly, to improve the efficiency of interactions, we develop a flexible semantic communication scheme that leverages compressed semantic knowledge bases. This scheme reduces the data exchange required for system update and is adapt to dynamic task requirements and the diversity of device capabilities. Thirdly, we exploit the integration of differential privacy into semantic communications. We analyze the implementation of differential privacy taking into account the lossy nature of semantic communications and wireless channel distortions. An joint model-channel noise mechanism is introduced to achieve differential privacy preservation in semantic communications without compromising the system's functionality. Experiments show that the system is able to achieve integrity, availability, efficiency and the preservation of privacy.
Richelieu: Self-Evolving LLM-Based Agents for AI Diplomacy
Jul 09, 2024Diplomacy is one of the most sophisticated activities in human society. The complex interactions among multiple parties/ agents involve various abilities like social reasoning, negotiation arts, and long-term strategy planning. Previous AI agents surely have proved their capability of handling multi-step games and larger action spaces on tasks involving multiple agents. However, diplomacy involves a staggering magnitude of decision spaces, especially considering the negotiation stage required. Recently, LLM agents have shown their potential for extending the boundary of previous agents on a couple of applications, however, it is still not enough to handle a very long planning period in a complex multi-agent environment. Empowered with cutting-edge LLM technology, we make the first stab to explore AI's upper bound towards a human-like agent for such a highly comprehensive multi-agent mission by combining three core and essential capabilities for stronger LLM-based societal agents: 1) strategic planner with memory and reflection; 2) goal-oriented negotiate with social reasoning; 3) augmenting memory by self-play games to self-evolving without any human in the loop.
East: Efficient and Accurate Secure Transformer Framework for Inference
Aug 19, 2023



Transformer has been successfully used in practical applications, such as ChatGPT, due to its powerful advantages. However, users' input is leaked to the model provider during the service. With people's attention to privacy, privacy-preserving Transformer inference is on the demand of such services. Secure protocols for non-linear functions are crucial in privacy-preserving Transformer inference, which are not well studied. Thus, designing practical secure protocols for non-linear functions is hard but significant to model performance. In this work, we propose a framework \emph{East} to enable efficient and accurate secure Transformer inference. Firstly, we propose a new oblivious piecewise polynomial evaluation algorithm and apply it to the activation functions, which reduces the runtime and communication of GELU by over 1.5$\times$ and 2.5$\times$, compared to prior arts. Secondly, the secure protocols for softmax and layer normalization are carefully designed to faithfully maintain the desired functionality. Thirdly, several optimizations are conducted in detail to enhance the overall efficiency. We applied \emph{East} to BERT and the results show that the inference accuracy remains consistent with the plaintext inference without fine-tuning. Compared to Iron, we achieve about 1.8$\times$ lower communication within 1.2$\times$ lower runtime.
Early Exit Or Not: Resource-Efficient Blind Quality Enhancement for Compressed Images
Jul 09, 2020
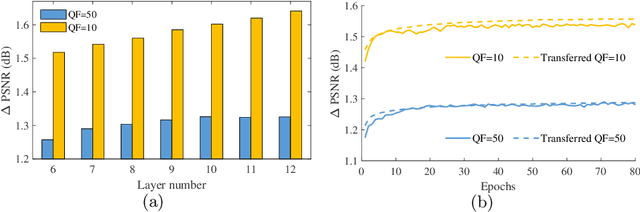
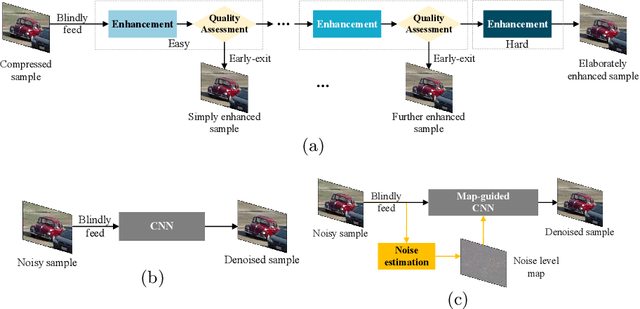
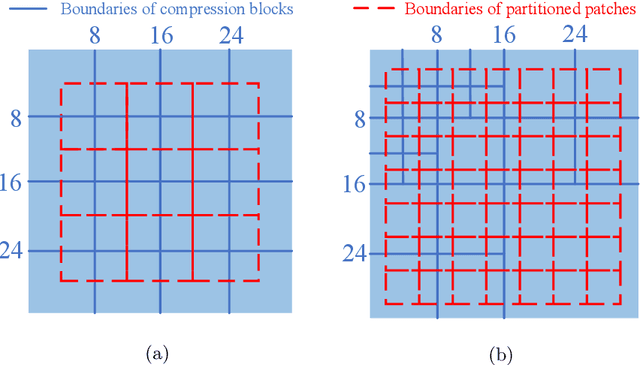
Lossy image compression is pervasively conducted to save communication bandwidth, resulting in undesirable compression artifacts. Recently, extensive approaches have been proposed to reduce image compression artifacts at the decoder side; however, they require a series of architecture-identical models to process images with different quality, which are inefficient and resource-consuming. Besides, it is common in practice that compressed images are with unknown quality and it is intractable for existing approaches to select a suitable model for blind quality enhancement. In this paper, we propose a resource-efficient blind quality enhancement (RBQE) approach for compressed images. Specifically, our approach blindly and progressively enhances the quality of compressed images through a dynamic deep neural network (DNN), in which an early-exit strategy is embedded. Then, our approach can automatically decide to terminate or continue enhancement according to the assessed quality of enhanced images. Consequently, slight artifacts can be removed in a simpler and faster process, while the severe artifacts can be further removed in a more elaborate process. Extensive experiments demonstrate that our RBQE approach achieves state-of-the-art performance in terms of both blind quality enhancement and resource efficiency.