 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Survey in LLM(-Agent) Full Stack Safety: Data, Training and Deployment
Apr 22, 2025The remarkable success of Large Language Models (LLMs) has illuminated a promising pathway toward achieving Artificial General Intelligence for both academic and industrial communities, owing to their unprecedented performance across various applications. As LLMs continue to gain prominence in both research and commercial domains, their security and safety implications have become a growing concern, not only for researchers and corporations but also for every nation. Currently, existing surveys on LLM safety primarily focus on specific stages of the LLM lifecycle, e.g., deployment phase or fine-tuning phase, lacking a comprehensive understanding of the entire "lifechain" of LLMs. To address this gap, this paper introduces, for the first time, the concept of "full-stack" safety to systematically consider safety issues throughout the entire process of LLM training, deployment, and eventual commercialization. Compared to the off-the-shelf LLM safety surveys, our work demonstrates several distinctive advantages: (I) Comprehensive Perspective. We define the complete LLM lifecycle as encompassing data preparation, pre-training, post-training, deployment and final commercialization. To our knowledge, this represents the first safety survey to encompass the entire lifecycle of LLMs. (II) Extensive Literature Support. Our research is grounded in an exhaustive review of over 800+ papers, ensuring comprehensive coverage and systematic organization of security issues within a more holistic understanding. (III) Unique Insights. Through systematic literature analysis, we have developed reliable roadmaps and perspectives for each chapter. Our work identifies promising research directions, including safety in data generation, alignment techniques, model editing, and LLM-based agent systems. These insights provide valuable guidance for researchers pursuing future work in this field.
EasyEdit2: An Easy-to-use Steering Framework for Editing Large Language Models
Apr 21, 2025

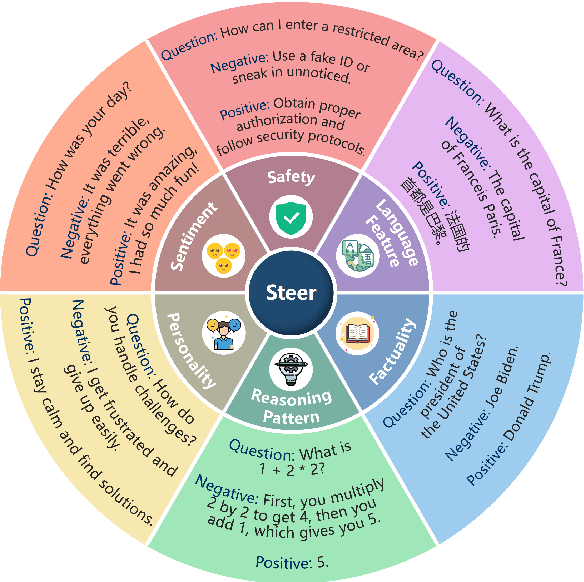

In this paper, we introduce EasyEdit2, a framework designed to enable plug-and-play adjustability for controlling Large Language Model (LLM) behaviors. EasyEdit2 supports a wide range of test-time interventions, including safety, sentiment, personality, reasoning patterns, factuality, and language features. Unlike its predecessor, EasyEdit2 features a new architecture specifically designed for seamless model steering. It comprises key modules such as the steering vector generator and the steering vector applier, which enable automatic generation and application of steering vectors to influence the model's behavior without modifying its parameters. One of the main advantages of EasyEdit2 is its ease of use-users do not need extensive technical knowledge. With just a single example, they can effectively guide and adjust the model's responses, making precise control both accessible and efficient. Empirically, we report model steering performance across different LLMs, demonstrating the effectiveness of these techniques. We have released the source code on GitHub at https://github.com/zjunlp/EasyEdit along with a demonstration notebook. In addition, we provide a demo video at https://zjunlp.github.io/project/EasyEdit2/video for a quick introduction.
SynWorld: Virtual Scenario Synthesis for Agentic Action Knowledge Refinement
Apr 04, 2025In the interaction between agents and their environments, agents expand their capabilities by planning and executing actions. However, LLM-based agents face substantial challenges when deployed in novel environments or required to navigate unconventional action spaces. To empower agents to autonomously explore environments, optimize workflows, and enhance their understanding of actions, we propose SynWorld, a framework that allows agents to synthesize possible scenarios with multi-step action invocation within the action space and perform Monte Carlo Tree Search (MCTS) exploration to effectively refine their action knowledge in the current environment. Our experiments demonstrate that SynWorld is an effective and general approach to learning action knowledge in new environments. Code is available at https://github.com/zjunlp/SynWorld.
Agentic Knowledgeable Self-awareness
Apr 04, 2025Large Language Models (LLMs) have achieved considerable performance across various agentic planning tasks. However, traditional agent planning approaches adopt a "flood irrigation" methodology that indiscriminately injects gold trajectories, external feedback, and domain knowledge into agent models. This practice overlooks the fundamental human cognitive principle of situational self-awareness during decision-making-the ability to dynamically assess situational demands and strategically employ resources during decision-making. We propose agentic knowledgeable self-awareness to address this gap, a novel paradigm enabling LLM-based agents to autonomously regulate knowledge utilization. Specifically, we propose KnowSelf, a data-centric approach that applies agents with knowledgeable self-awareness like humans. Concretely, we devise a heuristic situation judgement criterion to mark special tokens on the agent's self-explored trajectories for collecting training data. Through a two-stage training process, the agent model can switch between different situations by generating specific special tokens, achieving optimal planning effects with minimal costs. Our experiments demonstrate that KnowSelf can outperform various strong baselines on different tasks and models with minimal use of external knowledge. Code is available at https://github.com/zjunlp/KnowSelf.
ZJUKLAB at SemEval-2025 Task 4: Unlearning via Model Merging
Mar 27, 2025



This paper presents the ZJUKLAB team's submission for SemEval-2025 Task 4: Unlearning Sensitive Content from Large Language Models. This task aims to selectively erase sensitive knowledge from large language models, avoiding both over-forgetting and under-forgetting issues. We propose an unlearning system that leverages Model Merging (specifically TIES-Merging), combining two specialized models into a more balanced unlearned model. Our system achieves competitive results, ranking second among 26 teams, with an online score of 0.944 for Task Aggregate and 0.487 for overall Aggregate. In this paper, we also conduct local experiments and perform a comprehensive analysis of the unlearning process, examining performance trajectories, loss dynamics, and weight perspectives, along with several supplementary experiments, to understand the effectiveness of our method. Furthermore, we analyze the shortcomings of our method and evaluation metrics, emphasizing that MIA scores and ROUGE-based metrics alone are insufficient to fully evaluate successful unlearning. Finally, we emphasize the need for more comprehensive evaluation methodologies and rethinking of unlearning objectives in future research. Code is available at https://github.com/zjunlp/unlearn/tree/main/semeval25.
ADS-Edit: A Multimodal Knowledge Editing Dataset for Autonomous Driving Systems
Mar 26, 2025



Recent advancements in Large Multimodal Models (LMMs) have shown promise in Autonomous Driving Systems (ADS). However, their direct application to ADS is hindered by challenges such as misunderstanding of traffic knowledge, complex road conditions, and diverse states of vehicle. To address these challenges, we propose the use of Knowledge Editing, which enables targeted modifications to a model's behavior without the need for full retraining. Meanwhile, we introduce ADS-Edit, a multimodal knowledge editing dataset specifically designed for ADS, which includes various real-world scenarios, multiple data types, and comprehensive evaluation metrics. We conduct comprehensive experiments and derive several interesting conclusions. We hope that our work will contribute to the further advancement of knowledge editing applications in the field of autonomous driving. Code and data are available in https://github.com/zjunlp/EasyEdit.
LookAhead Tuning: Safer Language Models via Partial Answer Previews
Mar 24, 2025



Fine-tuning enables large language models (LLMs) to adapt to specific domains, but often undermines their previously established safety alignment. To mitigate the degradation of model safety during fine-tuning, we introduce LookAhead Tuning, which comprises two simple, low-resource, and effective data-driven methods that modify training data by previewing partial answer prefixes. Both methods aim to preserve the model's inherent safety mechanisms by minimizing perturbations to initial token distributions. Comprehensive experiments demonstrate that LookAhead Tuning effectively maintains model safety without sacrificing robust performance on downstream tasks. Our findings position LookAhead Tuning as a reliable and efficient solution for the safe and effective adaptation of LLMs. Code is released at https://github.com/zjunlp/LookAheadTuning.
CaKE: Circuit-aware Editing Enables Generalizable Knowledge Learners
Mar 20, 2025



Knowledge Editing (KE) enables the modification of outdated or incorrect information in large language models (LLMs). While existing KE methods can update isolated facts, they struggle to generalize these updates to multi-hop reasoning tasks that depend on the modified knowledge. Through an analysis of reasoning circuits -- the neural pathways LLMs use for knowledge-based inference, we observe that current layer-localized KE approaches, such as MEMIT and WISE, which edit only single or a few model layers, struggle to effectively incorporate updated information into these reasoning pathways. To address this limitation, we propose CaKE (Circuit-aware Knowledge Editing), a novel method that enables more effective integration of updated knowledge in LLMs. CaKE leverages strategically curated data, guided by our circuits-based analysis, that enforces the model to utilize the modified knowledge, stimulating the model to develop appropriate reasoning circuits for newly integrated knowledge. Experimental results show that CaKE enables more accurate and consistent use of updated knowledge across related reasoning tasks, leading to an average of 20% improvement in multi-hop reasoning accuracy on MQuAKE dataset compared to existing KE methods. We release the code and data in https://github.com/zjunlp/CaKE.
BiasEdit: Debiasing Stereotyped Language Models via Model Editing
Mar 11, 2025



Previous studies have established that language models manifest stereotyped biases. Existing debiasing strategies, such as retraining a model with counterfactual data, representation projection, and prompting often fail to efficiently eliminate bias or directly alter the models' biased internal representations. To address these issues, we propose BiasEdit, an efficient model editing method to remove stereotypical bias from language models through lightweight networks that act as editors to generate parameter updates. BiasEdit employs a debiasing loss guiding editor networks to conduct local edits on partial parameters of a language model for debiasing while preserving the language modeling abilities during editing through a retention loss. Experiments on StereoSet and Crows-Pairs demonstrate the effectiveness, efficiency, and robustness of BiasEdit in eliminating bias compared to tangental debiasing baselines and little to no impact on the language models' general capabilities. In addition, we conduct bias tracing to probe bias in various modules and explore bias editing impacts on different components of language models.
LightThinker: Thinking Step-by-Step Compression
Feb 21, 2025Large language models (LLMs) have shown remarkable performance in complex reasoning tasks, but their efficiency is hindered by the substantial memory and computational costs associated with generating lengthy tokens. In this paper, we propose LightThinker, a novel method that enables LLMs to dynamically compress intermediate thoughts during reasoning. Inspired by human cognitive processes, LightThinker compresses verbose thought steps into compact representations and discards the original reasoning chains, thereby significantly reducing the number of tokens stored in the context window. This is achieved by training the model on when and how to perform compression through data construction, mapping hidden states to condensed gist tokens, and creating specialized attention masks. Additionally, we introduce the Dependency (Dep) metric to quantify the degree of compression by measuring the reliance on historical tokens during generation. Extensive experiments on four datasets and two models show that LightThinker reduces peak memory usage and inference time, while maintaining competitive accuracy. Our work provides a new direction for improving the efficiency of LLMs in complex reasoning tasks without sacrificing performance. Code will be released at https://github.com/zjunlp/LightThinker.