 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEasyEdit2: An Easy-to-use Steering Framework for Editing Large Language Models
Apr 21, 2025

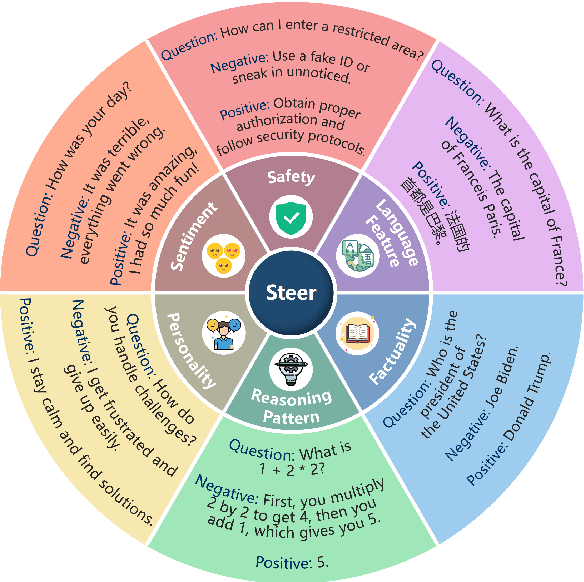

In this paper, we introduce EasyEdit2, a framework designed to enable plug-and-play adjustability for controlling Large Language Model (LLM) behaviors. EasyEdit2 supports a wide range of test-time interventions, including safety, sentiment, personality, reasoning patterns, factuality, and language features. Unlike its predecessor, EasyEdit2 features a new architecture specifically designed for seamless model steering. It comprises key modules such as the steering vector generator and the steering vector applier, which enable automatic generation and application of steering vectors to influence the model's behavior without modifying its parameters. One of the main advantages of EasyEdit2 is its ease of use-users do not need extensive technical knowledge. With just a single example, they can effectively guide and adjust the model's responses, making precise control both accessible and efficient. Empirically, we report model steering performance across different LLMs, demonstrating the effectiveness of these techniques. We have released the source code on GitHub at https://github.com/zjunlp/EasyEdit along with a demonstration notebook. In addition, we provide a demo video at https://zjunlp.github.io/project/EasyEdit2/video for a quick introduction.
ZJUKLAB at SemEval-2025 Task 4: Unlearning via Model Merging
Mar 27, 2025



This paper presents the ZJUKLAB team's submission for SemEval-2025 Task 4: Unlearning Sensitive Content from Large Language Models. This task aims to selectively erase sensitive knowledge from large language models, avoiding both over-forgetting and under-forgetting issues. We propose an unlearning system that leverages Model Merging (specifically TIES-Merging), combining two specialized models into a more balanced unlearned model. Our system achieves competitive results, ranking second among 26 teams, with an online score of 0.944 for Task Aggregate and 0.487 for overall Aggregate. In this paper, we also conduct local experiments and perform a comprehensive analysis of the unlearning process, examining performance trajectories, loss dynamics, and weight perspectives, along with several supplementary experiments, to understand the effectiveness of our method. Furthermore, we analyze the shortcomings of our method and evaluation metrics, emphasizing that MIA scores and ROUGE-based metrics alone are insufficient to fully evaluate successful unlearning. Finally, we emphasize the need for more comprehensive evaluation methodologies and rethinking of unlearning objectives in future research. Code is available at https://github.com/zjunlp/unlearn/tree/main/semeval25.
SEAGULL: No-reference Image Quality Assessment for Regions of Interest via Vision-Language Instruction Tuning
Nov 15, 2024



Existing Image Quality Assessment (IQA) methods achieve remarkable success in analyzing quality for overall image, but few works explore quality analysis for Regions of Interest (ROIs). The quality analysis of ROIs can provide fine-grained guidance for image quality improvement and is crucial for scenarios focusing on region-level quality. This paper proposes a novel network, SEAGULL, which can SEe and Assess ROIs quality with GUidance from a Large vision-Language model. SEAGULL incorporates a vision-language model (VLM), masks generated by Segment Anything Model (SAM) to specify ROIs, and a meticulously designed Mask-based Feature Extractor (MFE) to extract global and local tokens for specified ROIs, enabling accurate fine-grained IQA for ROIs. Moreover, this paper constructs two ROI-based IQA datasets, SEAGULL-100w and SEAGULL-3k, for training and evaluating ROI-based IQA. SEAGULL-100w comprises about 100w synthetic distortion images with 33 million ROIs for pre-training to improve the model's ability of regional quality perception, and SEAGULL-3k contains about 3k authentic distortion ROIs to enhance the model's ability to perceive real world distortions. After pre-training on SEAGULL-100w and fine-tuning on SEAGULL-3k, SEAGULL shows remarkable performance on fine-grained ROI quality assessment. Code and datasets are publicly available at the https://github.com/chencn2020/Seagull.