 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgedots.tts Technical Report
Jun 05, 2026We present dots.tts, a 2B-parameter continuous autoregressive text-to-speech (TTS) foundation model that models speech in a continuous latent space. Compared with existing continuous autoregressive models, our key innovations are threefold. First, we train an AudioVAE with multiple objectives to build a semantically structured and prediction-friendly continuous speech space. Second, we use full-history conditioning in the flow-matching head to preserve long-range consistency and reduce drift during generation. Third, we apply reward-free self-corrective post-training to the flow-matching head to further improve robustness and acoustic quality. After being trained on a large-scale multilingual corpus, dots.tts achieves the best average performance on Seed-TTS-Eval, with WERs of 0.94%/1.30%/6.60% and SIM scores of 81.0/77.1/79.5 on the zh/en/zh-hard test sets, respectively. Across other benchmarks, dots.tts also consistently demonstrates open-source state-of-the-art performance, exhibiting strong generation stability, voice cloning ability, and emotional expressiveness. For efficient inference, we further apply CFG-aware MeanFlow distillation, enabling low-latency speech generation with first-packet latencies of 85/54 ms in output streaming and dual-streaming modes, respectively. To facilitate reproducible research and practical deployment, we release the training and inference code, together with the pretrained, post-trained, and MeanFlow-distilled checkpoints, under the Apache 2.0 license.
HoliTok:A Coutinuous Holistic Tokenization with Robust Dual Capabilities of Speech Generation and Understanding
May 28, 2026Unified speech foundation models require a holistic tokenization space that is both learnable by language models and decodable into high-quality waveforms. Existing speech tokenizers, however, often fail to satisfy these requirements simultaneously, leading to increased architectural complexity and more involved training designs. We propose HoliTok, a continuous Holistic speech Tokenization model designed for unified generation-understanding modeling. HoliTok encodes 48~kHz speech into a compact 25~Hz sequence of 128-dimensional latents. It is trained with a progressive strategy that jointly preserves signal-level fidelity, incorporates semantic information, and maintains strong latent learnability. Based on this tokenization, we build a unified AR+DiT model for speech synthesis and recognition, where the same latent sequence supports both generation-specific and unified generation-understanding tasks. Experiments show that HoliTok achieves competitive reconstruction fidelity, improves generative learnability for high-quality and controllable synthesis, and, among the evaluated representations, is the only one that operates robustly in our unified generation-understanding architecture without additional optimization tricks. These results suggest that HoliTok serves as an effective speech tokenizer and a foundational representation interface for unified spoken language modeling. The code is available at: https://github.com/bovod-sjtu/HoliTok.
Step-TP: A Grounded, Step-Level Dataset with Chain-of-Thought Reasoning for LLM-Guided Tensor Program Optimization
May 25, 2026Despite the strong reasoning capabilities of large language models (LLMs), optimizing the execution efficiency of tensor programs remains challenging due to the need for precise, composable transformation decisions. Recent LLM-guided approaches frame tensor program optimization as an iterative decision process, but existing datasets provide only end-to-end optimized program pairs using token-inefficient representations, lacking verifiable step-level supervision and interpretability. As a result, LLMs struggle to make reliable single-step decisions in large combinatorial optimization spaces. We introduce Step-TP, a post-training dataset for tensor program optimization that provides grounded, atomic, step-level supervision with structured chain-of-thought (CoT) reasoning. Step-TP forms a closed reasoning loop over intermediate program states, enabling reliable multi-step optimization rather than outcome imitation. Its design is guided by four principles: (i) a token-efficient, verifiable intermediate representation (IR) that deterministically lowers to TVM TIR; (ii) atomic and composable optimization strategies that decompose complex trajectories into interpretable single-step decisions; (iii) structured CoT supervision coupled with explicit IR-to-IR state transitions; and (iv) strategy filtering to balance coverage while preventing shortcut exploitation. The dataset and implementation are available at a GitHub link, https://github.com/LIUMENGFAN-gif/StepTP.
LightThinker++: From Reasoning Compression to Memory Management
Apr 04, 2026Large language models (LLMs) excel at complex reasoning, yet their efficiency is limited by the surging cognitive overhead of long thought traces. In this paper, we propose LightThinker, a method that enables LLMs to dynamically compress intermediate thoughts into compact semantic representations. However, static compression often struggles with complex reasoning where the irreversible loss of intermediate details can lead to logical bottlenecks. To address this, we evolve the framework into LightThinker++, introducing Explicit Adaptive Memory Management. This paradigm shifts to behavioral-level management by incorporating explicit memory primitives, supported by a specialized trajectory synthesis pipeline to train purposeful memory scheduling. Extensive experiments demonstrate the framework's versatility across three dimensions. (1) LightThinker reduces peak token usage by 70% and inference time by 26% with minimal accuracy loss. (2) In standard reasoning, LightThinker++ slashes peak token usage by 69.9% while yielding a +2.42% accuracy gain under the same context budget for maximum performance. (3) Most notably, in long-horizon agentic tasks, it maintains a stable footprint beyond 80 rounds (a 60%-70% reduction), achieving an average performance gain of 14.8% across different complex scenarios. Overall, our work provides a scalable direction for sustaining deep LLM reasoning over extended horizons with minimal overhead.
TabDLM: Free-Form Tabular Data Generation via Joint Numerical-Language Diffusion
Feb 26, 2026Synthetic tabular data generation has attracted growing attention due to its importance for data augmentation, foundation models, and privacy. However, real-world tabular datasets increasingly contain free-form text fields (e.g., reviews or clinical notes) alongside structured numerical and categorical attributes. Generating such heterogeneous tables with joint modeling of different modalities remains challenging. Existing approaches broadly fall into two categories: diffusion-based methods and LLM-based methods. Diffusion models can capture complex dependencies over numerical and categorical features in continuous or discrete spaces, but extending them to open-ended text is nontrivial and often leads to degraded text quality. In contrast, LLM-based generators naturally produce fluent text, yet their discrete tokenization can distort precise or wide-range numerical values, hindering accurate modeling of both numbers and language. In this work, we propose TabDLM, a unified framework for free-form tabular data generation via a joint numerical--language diffusion model built on masked diffusion language models (MDLMs). TabDLM models textual and categorical features through masked diffusion, while modeling numerical features with a continuous diffusion process through learned specialized numeric tokens embedding; bidirectional attention then captures cross-modality interactions within a single model. Extensive experiments on diverse benchmarks demonstrate the effectiveness of TabDLM compared to strong diffusion- and LLM-based baselines.
GREPO: A Benchmark for Graph Neural Networks on Repository-Level Bug Localization
Feb 14, 2026Repository-level bug localization-the task of identifying where code must be modified to fix a bug-is a critical software engineering challenge. Standard Large Language Modles (LLMs) are often unsuitable for this task due to context window limitations that prevent them from processing entire code repositories. As a result, various retrieval methods are commonly used, including keyword matching, text similarity, and simple graph-based heuristics such as Breadth-First Search. Graph Neural Networks (GNNs) offer a promising alternative due to their ability to model complex, repository-wide dependencies; however, their application has been hindered by the lack of a dedicated benchmark. To address this gap, we introduce GREPO, the first GNN benchmark for repository-scale bug localization tasks. GREPO comprises 86 Python repositories and 47294 bug-fixing tasks, providing graph-based data structures ready for direct GNN processing. Our evaluation of various GNN architectures shows outstanding performance compared to established information retrieval baselines. This work highlights the potential of GNNs for bug localization and established GREPO as a foundation resource for future research, The code is available at https://github.com/qingpingmo/GREPO.
LLaDA2.1: Speeding Up Text Diffusion via Token Editing
Feb 09, 2026While LLaDA2.0 showcased the scaling potential of 100B-level block-diffusion models and their inherent parallelization, the delicate equilibrium between decoding speed and generation quality has remained an elusive frontier. Today, we unveil LLaDA2.1, a paradigm shift designed to transcend this trade-off. By seamlessly weaving Token-to-Token (T2T) editing into the conventional Mask-to-Token (M2T) scheme, we introduce a joint, configurable threshold-decoding scheme. This structural innovation gives rise to two distinct personas: the Speedy Mode (S Mode), which audaciously lowers the M2T threshold to bypass traditional constraints while relying on T2T to refine the output; and the Quality Mode (Q Mode), which leans into conservative thresholds to secure superior benchmark performances with manageable efficiency degrade. Furthering this evolution, underpinned by an expansive context window, we implement the first large-scale Reinforcement Learning (RL) framework specifically tailored for dLLMs, anchored by specialized techniques for stable gradient estimation. This alignment not only sharpens reasoning precision but also elevates instruction-following fidelity, bridging the chasm between diffusion dynamics and complex human intent. We culminate this work by releasing LLaDA2.1-Mini (16B) and LLaDA2.1-Flash (100B). Across 33 rigorous benchmarks, LLaDA2.1 delivers strong task performance and lightning-fast decoding speed. Despite its 100B volume, on coding tasks it attains an astounding 892 TPS on HumanEval+, 801 TPS on BigCodeBench, and 663 TPS on LiveCodeBench.
Full-Graph vs. Mini-Batch Training: Comprehensive Analysis from a Batch Size and Fan-Out Size Perspective
Jan 30, 2026Full-graph and mini-batch Graph Neural Network (GNN) training approaches have distinct system design demands, making it crucial to choose the appropriate approach to develop. A core challenge in comparing these two GNN training approaches lies in characterizing their model performance (i.e., convergence and generalization) and computational efficiency. While a batch size has been an effective lens in analyzing such behaviors in deep neural networks (DNNs), GNNs extend this lens by introducing a fan-out size, as full-graph training can be viewed as mini-batch training with the largest possible batch size and fan-out size. However, the impact of the batch and fan-out size for GNNs remains insufficiently explored. To this end, this paper systematically compares full-graph vs. mini-batch training of GNNs through empirical and theoretical analyses from the view points of the batch size and fan-out size. Our key contributions include: 1) We provide a novel generalization analysis using the Wasserstein distance to study the impact of the graph structure, especially the fan-out size. 2) We uncover the non-isotropic effects of the batch size and the fan-out size in GNN convergence and generalization, providing practical guidance for tuning these hyperparameters under resource constraints. Finally, full-graph training does not always yield better model performance or computational efficiency than well-tuned smaller mini-batch settings. The implementation can be found in the github link: https://github.com/LIUMENGFAN-gif/GNN_fullgraph_minibatch_training.
LLaDA2.0: Scaling Up Diffusion Language Models to 100B
Dec 24, 2025This paper presents LLaDA2.0 -- a tuple of discrete diffusion large language models (dLLM) scaling up to 100B total parameters through systematic conversion from auto-regressive (AR) models -- establishing a new paradigm for frontier-scale deployment. Instead of costly training from scratch, LLaDA2.0 upholds knowledge inheritance, progressive adaption and efficiency-aware design principle, and seamless converts a pre-trained AR model into dLLM with a novel 3-phase block-level WSD based training scheme: progressive increasing block-size in block diffusion (warm-up), large-scale full-sequence diffusion (stable) and reverting back to compact-size block diffusion (decay). Along with post-training alignment with SFT and DPO, we obtain LLaDA2.0-mini (16B) and LLaDA2.0-flash (100B), two instruction-tuned Mixture-of-Experts (MoE) variants optimized for practical deployment. By preserving the advantages of parallel decoding, these models deliver superior performance and efficiency at the frontier scale. Both models were open-sourced.
EvolProver: Advancing Automated Theorem Proving by Evolving Formalized Problems via Symmetry and Difficulty
Oct 01, 2025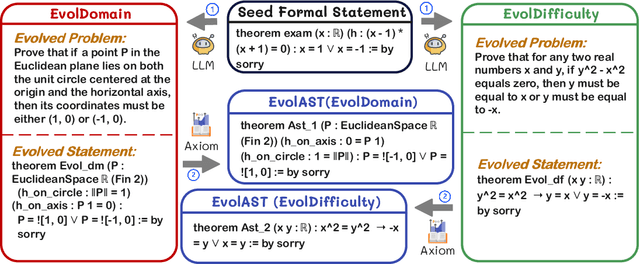
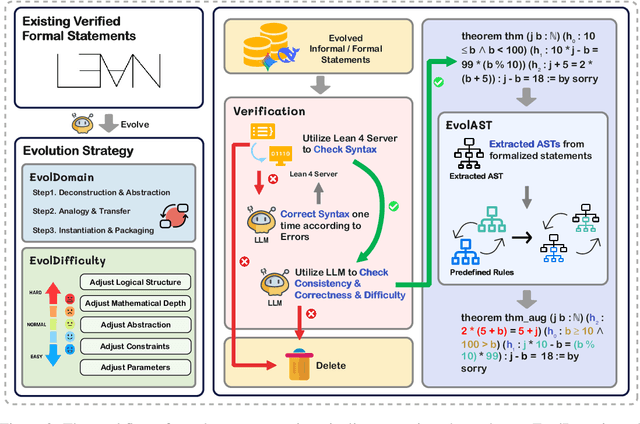
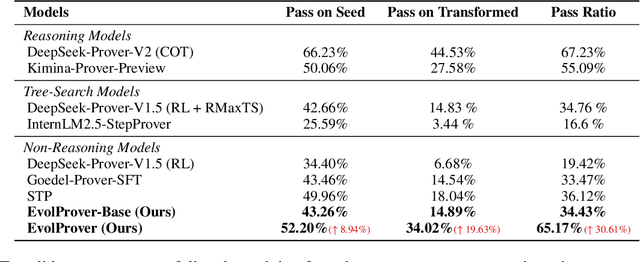

Large Language Models (LLMs) for formal theorem proving have shown significant promise, yet they often lack generalizability and are fragile to even minor transformations of problem statements. To address this limitation, we introduce a novel data augmentation pipeline designed to enhance model robustness from two perspectives: symmetry and difficulty. From the symmetry perspective, we propose two complementary methods: EvolAST, an Abstract Syntax Tree (AST) based approach that targets syntactic symmetry to generate semantically equivalent problem variants, and EvolDomain, which leverages LLMs to address semantic symmetry by translating theorems across mathematical domains. From the difficulty perspective, we propose EvolDifficulty, which uses carefully designed evolutionary instructions to guide LLMs in generating new theorems with a wider range of difficulty. We then use the evolved data to train EvolProver, a 7B-parameter non-reasoning theorem prover. EvolProver establishes a new state-of-the-art (SOTA) on FormalMATH-Lite with a 53.8% pass@32 rate, surpassing all models of comparable size, including reasoning-based models. It also sets new SOTA records for non-reasoning models on MiniF2F-Test (69.8% pass@32), Ineq-Comp-Seed (52.2% pass@32), and Ineq-Comp-Transformed (34.0% pass@32). Ablation studies further confirm our data augmentation pipeline's effectiveness across multiple benchmarks.