 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Loss Balancing for Noise-Robust GRPO in Generative Recommendation
Jun 07, 2026Reinforcement learning (RL) presents a promising avenue for enhancing generative recommendation beyond supervised imitation, leveraging reward signals to guide policy improvement. However, its efficacy is critically contingent on the trustworthiness of the reward model for the samples it evaluates. In practice, production rankers, the widely adopted reward models, are trained on exposure-biased logs, leading to sample-dependent inaccuracies that violate this assumption. Our stratified analysis uncovers a consistent pattern: reward guidance is most beneficial when the policy exhibits uncertainty and the ranker can effectively discriminate the ground-truth item from rollout negatives. On other samples, the reward signal is either negligible or detrimental, highlighting the risk of uniform RL application. To address such an issue, we introduce AdaGRPO, a novel framework that treats reward-guided optimization as selective admission rather than uniform pressure. Training is anchored in supervised negative log-likelihood, while the GRPO objective is gated by a binary, per-sample clip determined by two rollout diagnostics: policy-side difficulty and reward discriminability. Instances failing either diagnostic default to pure supervision, ensuring stability and mitigating the amplification of noisy gradients. We validate AdaGRPO on a large-scale e-commerce dataset. At the best intermediate checkpoint, it elevates HR@10 from 11.01% to 12.18% while constraining hallucination below 0.22%, and maintains robustness at the final checkpoint (HR@10 11.63%, hallucination 0.27%), outperforming fixed NLL--GRPO mixtures across the retrieval--validity frontier. In production A/B tests, AdaGRPO achieves statistically significant gains in click-through rate and dwell time, confirming its practical utility.
LongDS-Bench: On the Failure of Long-Horizon Agentic Data Analysis
May 28, 2026Real-world data analysis is inherently iterative, yet existing benchmarks mostly evaluate isolated or short interactive tasks, leaving agents' ability to track evolving analytical context over long horizons untested. We introduce LongDS, a benchmark for long-horizon, multi-turn data analysis where agents must maintain, update, restore, and compose evolving analytical states. LongDS comprises 68 tasks constructed from real-world Kaggle notebooks, spanning 2,225 turns across six domains including Geoscience, Business, and Education. Tasks are designed around state-evolution patterns (e.g., counterfactual perturbation, rollback, multi-state composition), with an average dependency span of 11.3 turns. Evaluating five state-of-the-art models, we find that the best model reaches only 48.45% average accuracy, performance drops nearly 47 points from early to late turns, and long-horizon errors account for 52%--69% of failures. Further analysis shows that additional agent steps do not necessarily improve performance, suggesting that the key bottleneck is maintaining a correct analytical state rather than increasing interaction budget. We release LongDS to support research on reliable long-horizon agentic data analysis. Code and data will be released at https://github.com/zjunlp/DataMind.
Exploring Autonomous Agentic Data Engineering for Model Specialization
May 28, 2026Large Language Models (LLMs) have demonstrated strong performance on general tasks, while often struggling to adapt to specialized domains without high-quality domain-specific data. Existing LLM-based data curation methods primarily rely on human-designed workflows, leaving it unexamined whether LLMs can autonomously execute an end-to-end data engineering pipeline for model specialization. We formalize \textbf{Autonomous Agentic Data Engineering}, a novel task designed to evaluate LLMs as autonomous data engineers that drive model specialization through end-to-end data curation. We frame data as an optimizable component and study agents that plan, generate, and iteratively optimize training data across multiple domains, guided by post-training performance improvement. Experiments show that autonomous LLM data engineers yield substantial gains, as GPT-5.2 constructs a training curriculum that improves a student model by \textbf{57.29\%}, entirely through iterative, agent-driven data adaptation. By illuminating both potential and bottlenecks, our study establishes autonomous data engineering as a measurable capability and charts a path toward agent-driven model specialization\footnote{Code will be released at https://github.com/zjunlp/DataAgent.}.
Rewarding the Scientific Process: Process-Level Reward Modeling for Agentic Data Analysis
Apr 27, 2026Process Reward Models (PRMs) have achieved remarkable success in augmenting the reasoning capabilities of Large Language Models (LLMs) within static domains such as mathematics. However, their potential in dynamic data analysis tasks remains underexplored. In this work, we first present a empirical study revealing that general-domain PRMs struggle to supervise data analysis agents. Specifically, they fail to detect silent errors, logical flaws that yield incorrect results without triggering interpreter exceptions, and erroneously penalize exploratory actions, mistaking necessary trial-and-error exploration for grounding failures. To bridge this gap, we introduce DataPRM, a novel environment-aware generative process reward model that (1) can serve as an active verifier, autonomously interacting with the environment to probe intermediate execution states and uncover silent errors, and (2) employs a reflection-aware ternary reward strategy that distinguishes between correctable grounding errors and irrecoverable mistakes. We design a scalable pipeline to construct over 8K high-quality training instances for DataPRM via diversity-driven trajectory generation and knowledge-augmented step-level annotation. Experimental results demonstrate that DataPRM improves downstream policy LLMs by 7.21% on ScienceAgentBench and 11.28% on DABStep using Best-of-N inference. Notably, with only 4B parameters, DataPRM outperforms strong baselines, and exhibits robust generalizability across diverse Test-Time Scaling strategies. Furthermore, integrating DataPRM into Reinforcement Learning yields substantial gains over outcome-reward baselines, achieving 78.73% on DABench and 64.84% on TableBench, validating the effectiveness of process reward supervision. Code is available at https://github.com/zjunlp/DataMind.
GenRec: A Preference-Oriented Generative Framework for Large-Scale Recommendation
Apr 16, 2026Generative Retrieval (GR) offers a promising paradigm for recommendation through next-token prediction (NTP). However, scaling it to large-scale industrial systems introduces three challenges: (i) within a single request, the identical model inputs may produce inconsistent outputs due to the pagination request mechanism; (ii) the prohibitive cost of encoding long user behavior sequences with multi-token item representations based on semantic IDs, and (iii) aligning the generative policy with nuanced user preference signals. We present GenRec, a preference-oriented generative framework deployed on the JD App that addresses above challenges within a single decoder-only architecture. For training objective, we propose Page-wise NTP task, which supervises over an entire interaction page rather than each interacted item individually, providing denser gradient signal and resolving the one-to-many ambiguity of point-wise training. On the prefilling side, an asymmetric linear Token Merger compresses multi-token Semantic IDs in the prompt while preserving full-resolution decoding, reducing input length by ~2X with negligible accuracy loss. To further align outputs with user satisfaction, we introduce GRPO-SR, a reinforcement learning method that pairs Group Relative Policy Optimization with NLL regularization for training stability, and employs Hybrid Rewards combining a dense reward model with a relevance gate to mitigate reward hacking. In month-long online A/B tests serving production traffic, GenRec achieves 9.5% improvement in click count and 8.7% in transaction count over the existing pipeline.
How Controllable Are Large Language Models? A Unified Evaluation across Behavioral Granularities
Mar 03, 2026Large Language Models (LLMs) are increasingly deployed in socially sensitive domains, yet their unpredictable behaviors, ranging from misaligned intent to inconsistent personality, pose significant risks. We introduce SteerEval, a hierarchical benchmark for evaluating LLM controllability across three domains: language features, sentiment, and personality. Each domain is structured into three specification levels: L1 (what to express), L2 (how to express), and L3 (how to instantiate), connecting high-level behavioral intent to concrete textual output. Using SteerEval, we systematically evaluate contemporary steering methods, revealing that control often degrades at finer-grained levels. Our benchmark offers a principled and interpretable framework for safe and controllable LLM behavior, serving as a foundation for future research.
EasyEdit2: An Easy-to-use Steering Framework for Editing Large Language Models
Apr 21, 2025

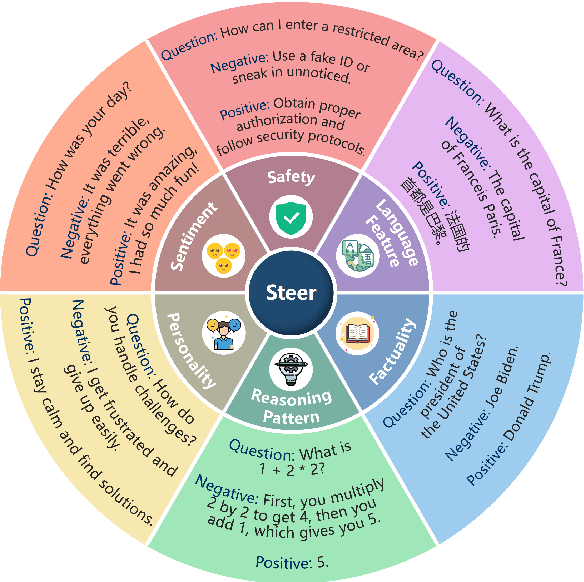

In this paper, we introduce EasyEdit2, a framework designed to enable plug-and-play adjustability for controlling Large Language Model (LLM) behaviors. EasyEdit2 supports a wide range of test-time interventions, including safety, sentiment, personality, reasoning patterns, factuality, and language features. Unlike its predecessor, EasyEdit2 features a new architecture specifically designed for seamless model steering. It comprises key modules such as the steering vector generator and the steering vector applier, which enable automatic generation and application of steering vectors to influence the model's behavior without modifying its parameters. One of the main advantages of EasyEdit2 is its ease of use-users do not need extensive technical knowledge. With just a single example, they can effectively guide and adjust the model's responses, making precise control both accessible and efficient. Empirically, we report model steering performance across different LLMs, demonstrating the effectiveness of these techniques. We have released the source code on GitHub at https://github.com/zjunlp/EasyEdit along with a demonstration notebook. In addition, we provide a demo video at https://zjunlp.github.io/project/EasyEdit2/video for a quick introduction.
Towards Federated Domain Unlearning: Verification Methodologies and Challenges
Jun 05, 2024Federated Learning (FL) has evolved as a powerful tool for collaborative model training across multiple entities, ensuring data privacy in sensitive sectors such as healthcare and finance. However, the introduction of the Right to Be Forgotten (RTBF) poses new challenges, necessitating federated unlearning to delete data without full model retraining. Traditional FL unlearning methods, not originally designed with domain specificity in mind, inadequately address the complexities of multi-domain scenarios, often affecting the accuracy of models in non-targeted domains or leading to uniform forgetting across all domains. Our work presents the first comprehensive empirical study on Federated Domain Unlearning, analyzing the characteristics and challenges of current techniques in multi-domain contexts. We uncover that these methods falter, particularly because they neglect the nuanced influences of domain-specific data, which can lead to significant performance degradation and inaccurate model behavior. Our findings reveal that unlearning disproportionately affects the model's deeper layers, erasing critical representational subspaces acquired during earlier training phases. In response, we propose novel evaluation methodologies tailored for Federated Domain Unlearning, aiming to accurately assess and verify domain-specific data erasure without compromising the model's overall integrity and performance. This investigation not only highlights the urgent need for domain-centric unlearning strategies in FL but also sets a new precedent for evaluating and implementing these techniques effectively.