 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfi-Med: Low-Resource Medical MLLMs with Robust Reasoning Evaluation
May 29, 2025
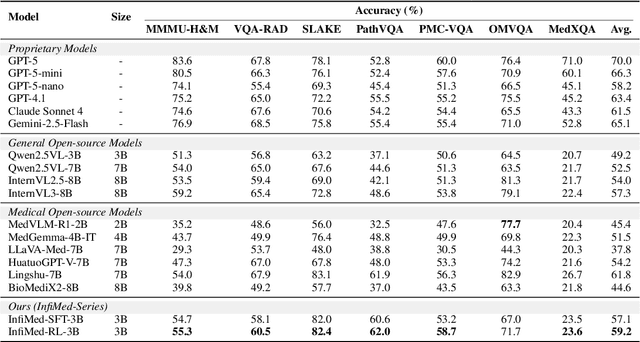
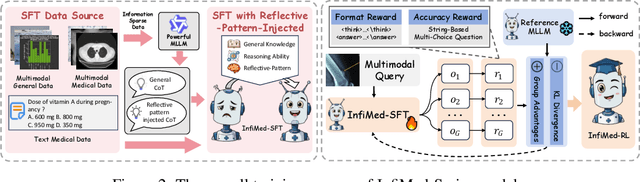
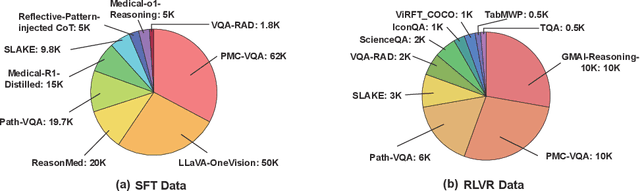
Multimodal large language models (MLLMs) have demonstrated promising prospects in healthcare, particularly for addressing complex medical tasks, supporting multidisciplinary treatment (MDT), and enabling personalized precision medicine. However, their practical deployment faces critical challenges in resource efficiency, diagnostic accuracy, clinical considerations, and ethical privacy. To address these limitations, we propose Infi-Med, a comprehensive framework for medical MLLMs that introduces three key innovations: (1) a resource-efficient approach through curating and constructing high-quality supervised fine-tuning (SFT) datasets with minimal sample requirements, with a forward-looking design that extends to both pretraining and posttraining phases; (2) enhanced multimodal reasoning capabilities for cross-modal integration and clinical task understanding; and (3) a systematic evaluation system that assesses model performance across medical modalities and task types. Our experiments demonstrate that Infi-Med achieves state-of-the-art (SOTA) performance in general medical reasoning while maintaining rapid adaptability to clinical scenarios. The framework establishes a solid foundation for deploying MLLMs in real-world healthcare settings by balancing model effectiveness with operational constraints.
LMCD: Language Models are Zeroshot Cognitive Diagnosis Learners
May 27, 2025Cognitive Diagnosis (CD) has become a critical task in AI-empowered education, supporting personalized learning by accurately assessing students' cognitive states. However, traditional CD models often struggle in cold-start scenarios due to the lack of student-exercise interaction data. Recent NLP-based approaches leveraging pre-trained language models (PLMs) have shown promise by utilizing textual features but fail to fully bridge the gap between semantic understanding and cognitive profiling. In this work, we propose Language Models as Zeroshot Cognitive Diagnosis Learners (LMCD), a novel framework designed to handle cold-start challenges by harnessing large language models (LLMs). LMCD operates via two primary phases: (1) Knowledge Diffusion, where LLMs generate enriched contents of exercises and knowledge concepts (KCs), establishing stronger semantic links; and (2) Semantic-Cognitive Fusion, where LLMs employ causal attention mechanisms to integrate textual information and student cognitive states, creating comprehensive profiles for both students and exercises. These representations are efficiently trained with off-the-shelf CD models. Experiments on two real-world datasets demonstrate that LMCD significantly outperforms state-of-the-art methods in both exercise-cold and domain-cold settings. The code is publicly available at https://github.com/TAL-auroraX/LMCD
Multi-Channel Sequence-to-Sequence Neural Diarization: Experimental Results for The MISP 2025 Challenge
May 22, 2025This paper describes the speaker diarization system developed for the Multimodal Information-Based Speech Processing (MISP) 2025 Challenge. First, we utilize the Sequence-to-Sequence Neural Diarization (S2SND) framework to generate initial predictions using single-channel audio. Then, we extend the original S2SND framework to create a new version, Multi-Channel Sequence-to-Sequence Neural Diarization (MC-S2SND), which refines the initial results using multi-channel audio. The final system achieves a diarization error rate (DER) of 8.09% on the evaluation set of the competition database, ranking first place in the speaker diarization task of the MISP 2025 Challenge.
Toward Theoretical Insights into Diffusion Trajectory Distillation via Operator Merging
May 21, 2025Diffusion trajectory distillation methods aim to accelerate sampling in diffusion models, which produce high-quality outputs but suffer from slow sampling speeds. These methods train a student model to approximate the multi-step denoising process of a pretrained teacher model in a single step, enabling one-shot generation. However, theoretical insights into the trade-off between different distillation strategies and generative quality remain limited, complicating their optimization and selection. In this work, we take a first step toward addressing this gap. Specifically, we reinterpret trajectory distillation as an operator merging problem in the linear regime, where each step of the teacher model is represented as a linear operator acting on noisy data. These operators admit a clear geometric interpretation as projections and rescalings corresponding to the noise schedule. During merging, signal shrinkage occurs as a convex combination of operators, arising from both discretization and limited optimization time of the student model. We propose a dynamic programming algorithm to compute the optimal merging strategy that maximally preserves signal fidelity. Additionally, we demonstrate the existence of a sharp phase transition in the optimal strategy, governed by data covariance structures. Our findings enhance the theoretical understanding of diffusion trajectory distillation and offer practical insights for improving distillation strategies.
DISCO Balances the Scales: Adaptive Domain- and Difficulty-Aware Reinforcement Learning on Imbalanced Data
May 21, 2025Large Language Models (LLMs) are increasingly aligned with human preferences through Reinforcement Learning from Human Feedback (RLHF). Among RLHF methods, Group Relative Policy Optimization (GRPO) has gained attention for its simplicity and strong performance, notably eliminating the need for a learned value function. However, GRPO implicitly assumes a balanced domain distribution and uniform semantic alignment across groups - assumptions that rarely hold in real-world datasets. When applied to multi-domain, imbalanced data, GRPO disproportionately optimizes for dominant domains, neglecting underrepresented ones and resulting in poor generalization and fairness. We propose Domain-Informed Self-Consistency Policy Optimization (DISCO), a principled extension to GRPO that addresses inter-group imbalance with two key innovations. Domain-aware reward scaling counteracts frequency bias by reweighting optimization based on domain prevalence. Difficulty-aware reward scaling leverages prompt-level self-consistency to identify and prioritize uncertain prompts that offer greater learning value. Together, these strategies promote more equitable and effective policy learning across domains. Extensive experiments across multiple LLMs and skewed training distributions show that DISCO improves generalization, outperforms existing GRPO variants by 5% on Qwen3 models, and sets new state-of-the-art results on multi-domain alignment benchmarks.
Anomaly Detection Based on Critical Paths for Deep Neural Networks
May 20, 2025Deep neural networks (DNNs) are notoriously hard to understand and difficult to defend. Extracting representative paths (including the neuron activation values and the connections between neurons) from DNNs using software engineering approaches has recently shown to be a promising approach in interpreting the decision making process of blackbox DNNs, as the extracted paths are often effective in capturing essential features. With this in mind, this work investigates a novel approach that extracts critical paths from DNNs and subsequently applies the extracted paths for the anomaly detection task, based on the observation that outliers and adversarial inputs do not usually induce the same activation pattern on those paths as normal (in-distribution) inputs. In our approach, we first identify critical detection paths via genetic evolution and mutation. Since different paths in a DNN often capture different features for the same target class, we ensemble detection results from multiple paths by integrating random subspace sampling and a voting mechanism. Compared with state-of-the-art methods, our experimental results suggest that our method not only outperforms them, but it is also suitable for the detection of a broad range of anomaly types with high accuracy.
Safe-Sora: Safe Text-to-Video Generation via Graphical Watermarking
May 19, 2025



The explosive growth of generative video models has amplified the demand for reliable copyright preservation of AI-generated content. Despite its popularity in image synthesis, invisible generative watermarking remains largely underexplored in video generation. To address this gap, we propose Safe-Sora, the first framework to embed graphical watermarks directly into the video generation process. Motivated by the observation that watermarking performance is closely tied to the visual similarity between the watermark and cover content, we introduce a hierarchical coarse-to-fine adaptive matching mechanism. Specifically, the watermark image is divided into patches, each assigned to the most visually similar video frame, and further localized to the optimal spatial region for seamless embedding. To enable spatiotemporal fusion of watermark patches across video frames, we develop a 3D wavelet transform-enhanced Mamba architecture with a novel spatiotemporal local scanning strategy, effectively modeling long-range dependencies during watermark embedding and retrieval. To the best of our knowledge, this is the first attempt to apply state space models to watermarking, opening new avenues for efficient and robust watermark protection. Extensive experiments demonstrate that Safe-Sora achieves state-of-the-art performance in terms of video quality, watermark fidelity, and robustness, which is largely attributed to our proposals. We will release our code upon publication.
InfiJanice: Joint Analysis and In-situ Correction Engine for Quantization-Induced Math Degradation in Large Language Models
May 16, 2025



Large Language Models (LLMs) have demonstrated impressive performance on complex reasoning benchmarks such as GSM8K, MATH, and AIME. However, the substantial computational demands of these tasks pose significant challenges for real-world deployment. Model quantization has emerged as a promising approach to reduce memory footprint and inference latency by representing weights and activations with lower bit-widths. In this work, we conduct a comprehensive study of mainstream quantization methods(e.g., AWQ, GPTQ, SmoothQuant) on the most popular open-sourced models (e.g., Qwen2.5, LLaMA3 series), and reveal that quantization can degrade mathematical reasoning accuracy by up to 69.81%. To better understand this degradation, we develop an automated assignment and judgment pipeline that qualitatively categorizes failures into four error types and quantitatively identifies the most impacted reasoning capabilities. Building on these findings, we employ an automated data-curation pipeline to construct a compact "Silver Bullet" datasets. Training a quantized model on as few as 332 carefully selected examples for just 3-5 minutes on a single GPU is enough to restore its reasoning accuracy to match that of the full-precision baseline.
Divide-and-Conquer: Cold-Start Bundle Recommendation via Mixture of Diffusion Experts
May 08, 2025Cold-start bundle recommendation focuses on modeling new bundles with insufficient information to provide recommendations. Advanced bundle recommendation models usually learn bundle representations from multiple views (e.g., interaction view) at both the bundle and item levels. Consequently, the cold-start problem for bundles is more challenging than that for traditional items due to the dual-level multi-view complexity. In this paper, we propose a novel Mixture of Diffusion Experts (MoDiffE) framework, which employs a divide-and-conquer strategy for cold-start bundle recommendation and follows three steps:(1) Divide: The bundle cold-start problem is divided into independent but similar sub-problems sequentially by level and view, which can be summarized as the poor representation of feature-missing bundles in prior-embedding models. (2) Conquer: Beyond prior-embedding models that fundamentally provide the embedded representations, we introduce a diffusion-based method to solve all sub-problems in a unified way, which directly generates diffusion representations using diffusion models without depending on specific features. (3) Combine: A cold-aware hierarchical Mixture of Experts (MoE) is employed to combine results of the sub-problems for final recommendations, where the two models for each view serve as experts and are adaptively fused for different bundles in a multi-layer manner. Additionally, MoDiffE adopts a multi-stage decoupled training pipeline and introduces a cold-start gating augmentation method to enable the training of gating for cold bundles. Through extensive experiments on three real-world datasets, we demonstrate that MoDiffE significantly outperforms existing solutions in handling cold-start bundle recommendation. It achieves up to a 0.1027 absolute gain in Recall@20 in cold-start scenarios and up to a 47.43\% relative improvement in all-bundle scenarios.
SuperEdit: Rectifying and Facilitating Supervision for Instruction-Based Image Editing
May 05, 2025Due to the challenges of manually collecting accurate editing data, existing datasets are typically constructed using various automated methods, leading to noisy supervision signals caused by the mismatch between editing instructions and original-edited image pairs. Recent efforts attempt to improve editing models through generating higher-quality edited images, pre-training on recognition tasks, or introducing vision-language models (VLMs) but fail to resolve this fundamental issue. In this paper, we offer a novel solution by constructing more effective editing instructions for given image pairs. This includes rectifying the editing instructions to better align with the original-edited image pairs and using contrastive editing instructions to further enhance their effectiveness. Specifically, we find that editing models exhibit specific generation attributes at different inference steps, independent of the text. Based on these prior attributes, we define a unified guide for VLMs to rectify editing instructions. However, there are some challenging editing scenarios that cannot be resolved solely with rectified instructions. To this end, we further construct contrastive supervision signals with positive and negative instructions and introduce them into the model training using triplet loss, thereby further facilitating supervision effectiveness. Our method does not require the VLM modules or pre-training tasks used in previous work, offering a more direct and efficient way to provide better supervision signals, and providing a novel, simple, and effective solution for instruction-based image editing. Results on multiple benchmarks demonstrate that our method significantly outperforms existing approaches. Compared with previous SOTA SmartEdit, we achieve 9.19% improvements on the Real-Edit benchmark with 30x less training data and 13x smaller model size.