 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Based Synthetic Ground Truth Generation for Audio-Based Emotion Classification via In-Context Learning
Jun 18, 2026Understanding human states and interaction dynamics is a core goal of human-computer interaction (HCI). As interaction paradigms become more immersive, virtual reality (VR) has emerged as a powerful platform for studying collaborative work. In such settings, evaluating team collaboration states, including team performance and team resilience, requires continuous and reliable inference of latent team-level cognitive and affective states from multi-modal sensor data, such as speech signals. However, generating ground truth labels for these latent states remains challenging due to sensor-induced noise, contextual variability, and sparse expert annotations. Traditional self-reporting approaches provide only static and delayed measurements and are therefore insufficient for capturing dynamic team processes reflected in continuous speech data. In this work, we propose a large language model (LLM)-driven, agentic inference workflow for automated emotion-related synthetic ground truth generation from streaming speech data in multi-user VR environments. Leveraging the generalization capabilities of LLMs, we use In-Context Learning (ICL) with few-shot demonstrations of paired audio-based samples and their corresponding transcriptions. ICL tends to achieve task adaptation comparable to model fine-tuning while circumventing the computational overhead of parameter updates. To construct informative and robust in-context prompts, we adopt a retrieval-based selection strategy that dynamically identifies relevant audio demonstrations based on similarity in the acoustic feature space.
Seeing to Act, Prompting to Specify: A Bayesian Factorization of Vision Language Action Policy
Dec 12, 2025The pursuit of out-of-distribution generalization in Vision-Language-Action (VLA) models is often hindered by catastrophic forgetting of the Vision-Language Model (VLM) backbone during fine-tuning. While co-training with external reasoning data helps, it requires experienced tuning and data-related overhead. Beyond such external dependencies, we identify an intrinsic cause within VLA datasets: modality imbalance, where language diversity is much lower than visual and action diversity. This imbalance biases the model toward visual shortcuts and language forgetting. To address this, we introduce BayesVLA, a Bayesian factorization that decomposes the policy into a visual-action prior, supporting seeing-to-act, and a language-conditioned likelihood, enabling prompt-to-specify. This inherently preserves generalization and promotes instruction following. We further incorporate pre- and post-contact phases to better leverage pre-trained foundation models. Information-theoretic analysis formally validates our effectiveness in mitigating shortcut learning. Extensive experiments show superior generalization to unseen instructions, objects, and environments compared to existing methods. Project page is available at: https://xukechun.github.io/papers/BayesVLA.
When Prompt Engineering Meets Software Engineering: CNL-P as Natural and Robust "APIs'' for Human-AI Interaction
Aug 09, 2025With the growing capabilities of large language models (LLMs), they are increasingly applied in areas like intelligent customer service, code generation, and knowledge management. Natural language (NL) prompts act as the ``APIs'' for human-LLM interaction. To improve prompt quality, best practices for prompt engineering (PE) have been developed, including writing guidelines and templates. Building on this, we propose Controlled NL for Prompt (CNL-P), which not only incorporates PE best practices but also draws on key principles from software engineering (SE). CNL-P introduces precise grammar structures and strict semantic norms, further eliminating NL's ambiguity, allowing for a declarative but structured and accurate expression of user intent. This helps LLMs better interpret and execute the prompts, leading to more consistent and higher-quality outputs. We also introduce an NL2CNL-P conversion tool based on LLMs, enabling users to write prompts in NL, which are then transformed into CNL-P format, thus lowering the learning curve of CNL-P. In particular, we develop a linting tool that checks CNL-P prompts for syntactic and semantic accuracy, applying static analysis techniques to NL for the first time. Extensive experiments demonstrate that CNL-P enhances the quality of LLM responses through the novel and organic synergy of PE and SE. We believe that CNL-P can bridge the gap between emerging PE and traditional SE, laying the foundation for a new programming paradigm centered around NL.
FinMMR: Make Financial Numerical Reasoning More Multimodal, Comprehensive, and Challenging
Aug 06, 2025We present FinMMR, a novel bilingual multimodal benchmark tailored to evaluate the reasoning capabilities of multimodal large language models (MLLMs) in financial numerical reasoning tasks. Compared to existing benchmarks, our work introduces three significant advancements. (1) Multimodality: We meticulously transform existing financial reasoning benchmarks, and construct novel questions from the latest Chinese financial research reports. FinMMR comprises 4.3K questions and 8.7K images spanning 14 categories, including tables, bar charts, and ownership structure charts. (2) Comprehensiveness: FinMMR encompasses 14 financial subdomains, including corporate finance, banking, and industry analysis, significantly exceeding existing benchmarks in financial domain knowledge breadth. (3) Challenge: Models are required to perform multi-step precise numerical reasoning by integrating financial knowledge with the understanding of complex financial images and text. The best-performing MLLM achieves only 53.0% accuracy on Hard problems. We believe that FinMMR will drive advancements in enhancing the reasoning capabilities of MLLMs in real-world scenarios.
FinanceReasoning: Benchmarking Financial Numerical Reasoning More Credible, Comprehensive and Challenging
Jun 06, 2025We introduce FinanceReasoning, a novel benchmark designed to evaluate the reasoning capabilities of large reasoning models (LRMs) in financial numerical reasoning problems. Compared to existing benchmarks, our work provides three key advancements. (1) Credibility: We update 15.6% of the questions from four public datasets, annotating 908 new questions with detailed Python solutions and rigorously refining evaluation standards. This enables an accurate assessment of the reasoning improvements of LRMs. (2) Comprehensiveness: FinanceReasoning covers 67.8% of financial concepts and formulas, significantly surpassing existing datasets. Additionally, we construct 3,133 Python-formatted functions, which enhances LRMs' financial reasoning capabilities through refined knowledge (e.g., 83.2% $\rightarrow$ 91.6% for GPT-4o). (3) Challenge: Models are required to apply multiple financial formulas for precise numerical reasoning on 238 Hard problems. The best-performing model (i.e., OpenAI o1 with PoT) achieves 89.1% accuracy, yet LRMs still face challenges in numerical precision. We demonstrate that combining Reasoner and Programmer models can effectively enhance LRMs' performance (e.g., 83.2% $\rightarrow$ 87.8% for DeepSeek-R1). Our work paves the way for future research on evaluating and improving LRMs in domain-specific complex reasoning tasks.
LMCD: Language Models are Zeroshot Cognitive Diagnosis Learners
May 27, 2025Cognitive Diagnosis (CD) has become a critical task in AI-empowered education, supporting personalized learning by accurately assessing students' cognitive states. However, traditional CD models often struggle in cold-start scenarios due to the lack of student-exercise interaction data. Recent NLP-based approaches leveraging pre-trained language models (PLMs) have shown promise by utilizing textual features but fail to fully bridge the gap between semantic understanding and cognitive profiling. In this work, we propose Language Models as Zeroshot Cognitive Diagnosis Learners (LMCD), a novel framework designed to handle cold-start challenges by harnessing large language models (LLMs). LMCD operates via two primary phases: (1) Knowledge Diffusion, where LLMs generate enriched contents of exercises and knowledge concepts (KCs), establishing stronger semantic links; and (2) Semantic-Cognitive Fusion, where LLMs employ causal attention mechanisms to integrate textual information and student cognitive states, creating comprehensive profiles for both students and exercises. These representations are efficiently trained with off-the-shelf CD models. Experiments on two real-world datasets demonstrate that LMCD significantly outperforms state-of-the-art methods in both exercise-cold and domain-cold settings. The code is publicly available at https://github.com/TAL-auroraX/LMCD
MARS: Defending Unmanned Aerial Vehicles From Attacks on Inertial Sensors with Model-based Anomaly Detection and Recovery
May 02, 2025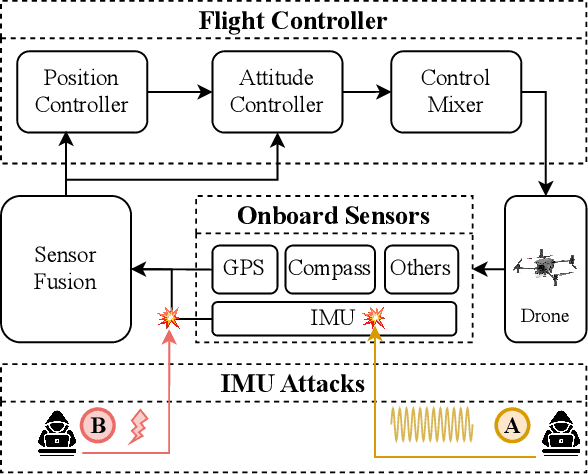
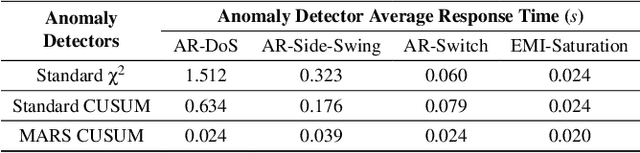
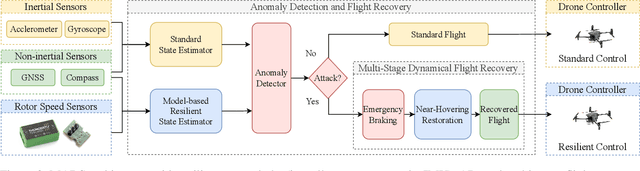

Unmanned Aerial Vehicles (UAVs) rely on measurements from Inertial Measurement Units (IMUs) to maintain stable flight. However, IMUs are susceptible to physical attacks, including acoustic resonant and electromagnetic interference attacks, resulting in immediate UAV crashes. Consequently, we introduce a Model-based Anomaly detection and Recovery System (MARS) that enables UAVs to quickly detect adversarial attacks on inertial sensors and achieve dynamic flight recovery. MARS features an attack-resilient state estimator based on the Extended Kalman Filter, which incorporates position, velocity, heading, and rotor speed measurements to reconstruct accurate attitude and angular velocity information for UAV control. Moreover, a statistical anomaly detection system monitors IMU sensor data, raising a system-level alert if an attack is detected. Upon receiving the alert, a multi-stage dynamic flight recovery strategy suspends the ongoing mission, stabilizes the drone in a hovering condition, and then resumes tasks under the resilient control. Experimental results in PX4 software-in-the-loop environments as well as real-world MARS-PX4 autopilot-equipped drones demonstrate the superiority of our approach over existing IMU-defense frameworks, showcasing the ability of the UAVs to survive attacks and complete the missions.
Explore-Construct-Filter: An Automated Framework for Rich and Reliable API Knowledge Graph Construction
Feb 19, 2025The API Knowledge Graph (API KG) is a structured network that models API entities and their relations, providing essential semantic insights for tasks such as API recommendation, code generation, and API misuse detection. However, constructing a knowledge-rich and reliable API KG presents several challenges. Existing schema-based methods rely heavily on manual annotations to design KG schemas, leading to excessive manual overhead. On the other hand, schema-free methods, due to the lack of schema guidance, are prone to introducing noise, reducing the KG's reliability. To address these issues, we propose the Explore-Construct-Filter framework, an automated approach for API KG construction based on large language models (LLMs). This framework consists of three key modules: 1) KG exploration: LLMs simulate the workflow of annotators to automatically design a schema with comprehensive type triples, minimizing human intervention; 2) KG construction: Guided by the schema, LLMs extract instance triples to construct a rich yet unreliable API KG; 3) KG filtering: Removing invalid type triples and suspicious instance triples to construct a rich and reliable API KG. Experimental results demonstrate that our method surpasses the state-of-the-art method, achieving a 25.2% improvement in F1 score. Moreover, the Explore-Construct-Filter framework proves effective, with the KG exploration module increasing KG richness by 133.6% and the KG filtering module improving reliability by 26.6%. Finally, cross-model experiments confirm the generalizability of our framework.
From Exploration to Revelation: Detecting Dark Patterns in Mobile Apps
Nov 27, 2024Mobile apps are essential in daily life, yet they often employ dark patterns, such as visual tricks to highlight certain options or linguistic tactics to nag users into making purchases, to manipulate user behavior. Current research mainly uses manual methods to detect dark patterns, a process that is time-consuming and struggles to keep pace with continually updating and emerging apps. While some studies targeted at automated detection, they are constrained to static patterns and still necessitate manual app exploration. To bridge these gaps, we present AppRay, an innovative system that seamlessly blends task-oriented app exploration with automated dark pattern detection, reducing manual efforts. Our approach consists of two steps: First, we harness the commonsense knowledge of large language models for targeted app exploration, supplemented by traditional random exploration to capture a broader range of UI states. Second, we developed a static and dynamic dark pattern detector powered by a contrastive learning-based multi-label classifier and a rule-based refiner to perform detection. We contributed two datasets, AppRay-Dark and AppRay-Light, with 2,185 unique deceptive patterns (including 149 dynamic instances) across 18 types from 876 UIs and 871 benign UIs. These datasets cover both static and dynamic dark patterns while preserving UI relationships. Experimental results confirm that AppRay can efficiently explore the app and identify a wide range of dark patterns with great performance.
DBF-Net: A Dual-Branch Network with Feature Fusion for Ultrasound Image Segmentation
Nov 17, 2024Accurately segmenting lesions in ultrasound images is challenging due to the difficulty in distinguishing boundaries between lesions and surrounding tissues. While deep learning has improved segmentation accuracy, there is limited focus on boundary quality and its relationship with body structures. To address this, we introduce UBBS-Net, a dual-branch deep neural network that learns the relationship between body and boundary for improved segmentation. We also propose a feature fusion module to integrate body and boundary information. Evaluated on three public datasets, UBBS-Net outperforms existing methods, achieving Dice Similarity Coefficients of 81.05% for breast cancer, 76.41% for brachial plexus nerves, and 87.75% for infantile hemangioma segmentation. Our results demonstrate the effectiveness of UBBS-Net for ultrasound image segmentation. The code is available at https://github.com/apple1986/DBF-Net.