 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly Detection Based on Critical Paths for Deep Neural Networks
May 20, 2025



Deep neural networks (DNNs) are notoriously hard to understand and difficult to defend. Extracting representative paths (including the neuron activation values and the connections between neurons) from DNNs using software engineering approaches has recently shown to be a promising approach in interpreting the decision making process of blackbox DNNs, as the extracted paths are often effective in capturing essential features. With this in mind, this work investigates a novel approach that extracts critical paths from DNNs and subsequently applies the extracted paths for the anomaly detection task, based on the observation that outliers and adversarial inputs do not usually induce the same activation pattern on those paths as normal (in-distribution) inputs. In our approach, we first identify critical detection paths via genetic evolution and mutation. Since different paths in a DNN often capture different features for the same target class, we ensemble detection results from multiple paths by integrating random subspace sampling and a voting mechanism. Compared with state-of-the-art methods, our experimental results suggest that our method not only outperforms them, but it is also suitable for the detection of a broad range of anomaly types with high accuracy.
A Mask-Based Adversarial Defense Scheme
Apr 21, 2022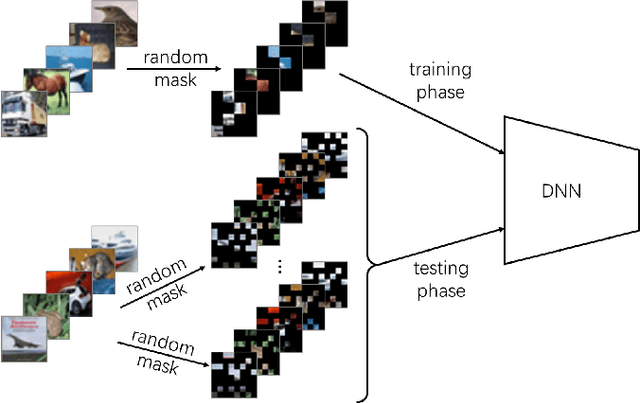

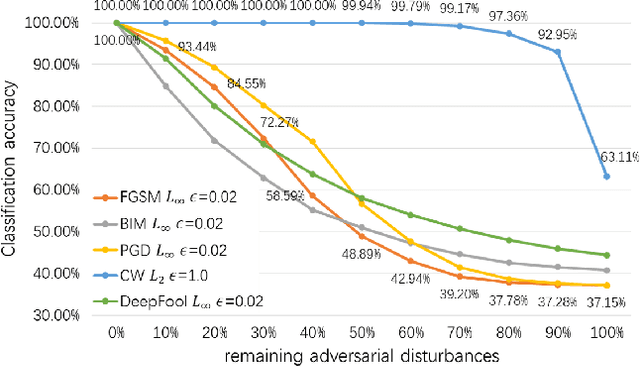
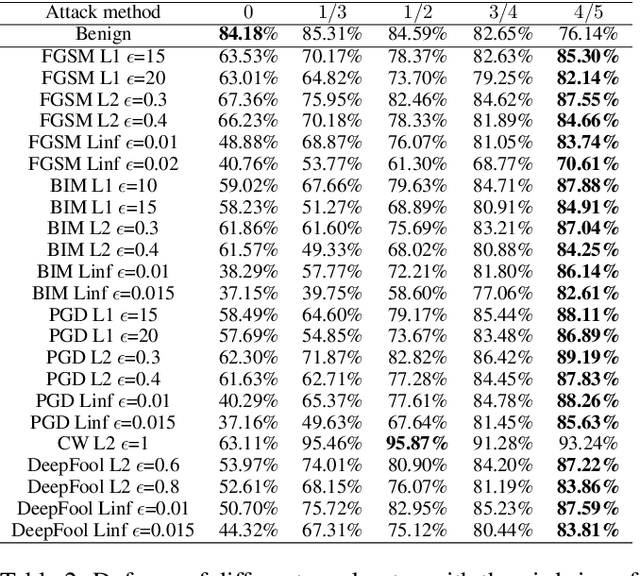
Adversarial attacks hamper the functionality and accuracy of Deep Neural Networks (DNNs) by meddling with subtle perturbations to their inputs.In this work, we propose a new Mask-based Adversarial Defense scheme (MAD) for DNNs to mitigate the negative effect from adversarial attacks. To be precise, our method promotes the robustness of a DNN by randomly masking a portion of potential adversarial images, and as a result, the %classification result output of the DNN becomes more tolerant to minor input perturbations. Compared with existing adversarial defense techniques, our method does not need any additional denoising structure, nor any change to a DNN's design. We have tested this approach on a collection of DNN models for a variety of data sets, and the experimental results confirm that the proposed method can effectively improve the defense abilities of the DNNs against all of the tested adversarial attack methods. In certain scenarios, the DNN models trained with MAD have improved classification accuracy by as much as 20% to 90% compared to the original models that are given adversarial inputs.
A Uniform Framework for Anomaly Detection in Deep Neural Networks
Oct 06, 2021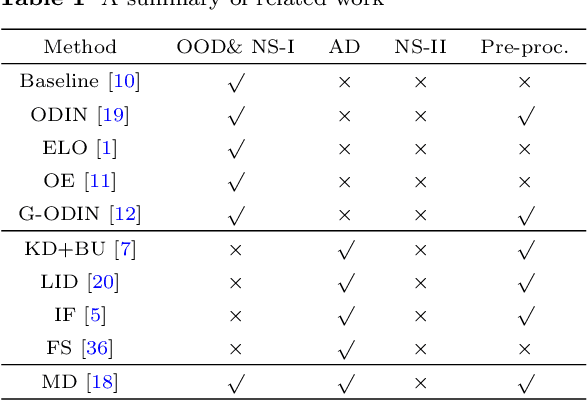
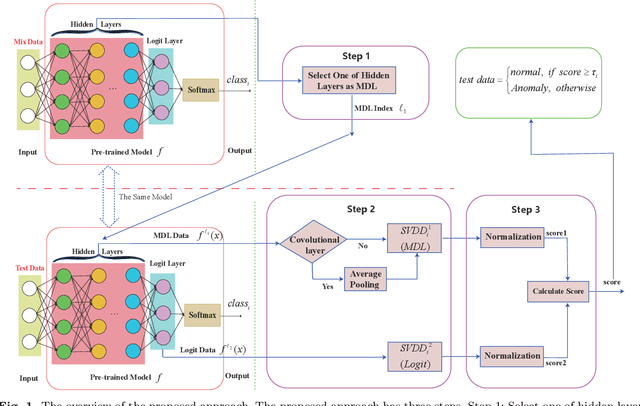
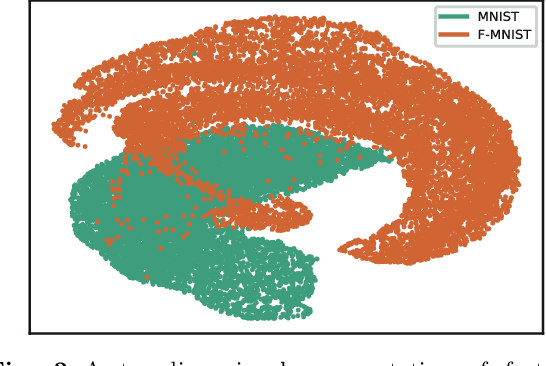
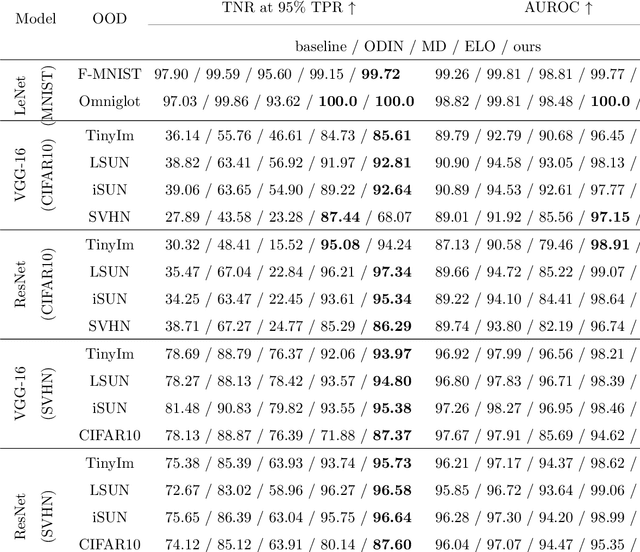
Deep neural networks (DNN) can achieve high performance when applied to In-Distribution (ID) data which come from the same distribution as the training set. When presented with anomaly inputs not from the ID, the outputs of a DNN should be regarded as meaningless. However, modern DNN often predict anomaly inputs as an ID class with high confidence, which is dangerous and misleading. In this work, we consider three classes of anomaly inputs, (1) natural inputs from a different distribution than the DNN is trained for, known as Out-of-Distribution (OOD) samples, (2) crafted inputs generated from ID by attackers, often known as adversarial (AD) samples, and (3) noise (NS) samples generated from meaningless data. We propose a framework that aims to detect all these anomalies for a pre-trained DNN. Unlike some of the existing works, our method does not require preprocessing of input data, nor is it dependent to any known OOD set or adversarial attack algorithm. Through extensive experiments over a variety of DNN models for the detection of aforementioned anomalies, we show that in most cases our method outperforms state-of-the-art anomaly detection methods in identifying all three classes of anomalies.