 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollabBench: Benchmarking and Unleashing Collaborative Ability of LLMs with Diverse Players via Proactive Engagement
Jun 04, 2026While LLM-based agents excel at individual tasks, effective collaboration with realistic human partners remains challenging. Most of the existing conversation-level collaborative studies lack grounded interaction and behavioral execution, motivating the need for cooperative game environments that enable contextualized and immersive collaboration. To this end, this paper proposes CollabBench, a benchmark for evaluating and training collaborative agents in cooperative games. CollabBench features a Diverse Player Profile Simulation pipeline to model varied players behaviors, and a Collaborative Agentic Training paradigm that unifies reasoning, communication, and action via agentic rollouts, optimized with a hybrid reward balancing task efficiency and affective adaptation. We further extend classic environments to CWAH-MultiPlayer and Cook-MultiPlayer for systematic evaluation under diverse personalities. Experiments with efficiency and affective metrics show that our trained models outperform base models, achieving 19.5% higher efficiency and 24.4% improved affective performance. Further analysis reveals key collaborative limitations of existing models and offers insights for future collaborative training.
Multimodal Protein Language Models for Enzyme Kinetic Parameters: From Substrate Recognition to Conformational Adaptation
Mar 13, 2026Predicting enzyme kinetic parameters quantifies how efficiently an enzyme catalyzes a specific substrate under defined biochemical conditions. Canonical parameters such as the turnover number ($k_\text{cat}$), Michaelis constant ($K_\text{m}$), and inhibition constant ($K_\text{i}$) depend jointly on the enzyme sequence, the substrate chemistry, and the conformational adaptation of the active site during binding. Many learning pipelines simplify this process to a static compatibility problem between the enzyme and substrate, fusing their representations through shallow operations and regressing a single value. Such formulations overlook the staged nature of catalysis, which involves both substrate recognition and conformational adaptation. In this regard, we reformulate kinetic prediction as a staged multimodal conditional modeling problem and introduce the Enzyme-Reaction Bridging Adapter (ERBA), which injects cross-modal information via fine-tuning into Protein Language Models (PLMs) while preserving their biochemical priors. ERBA performs conditioning in two stages: Molecular Recognition Cross-Attention (MRCA) first injects substrate information into the enzyme representation to capture specificity; Geometry-aware Mixture-of-Experts (G-MoE) then integrates active-site structure and routes samples to pocket-specialized experts to reflect induced fit. To maintain semantic fidelity, Enzyme-Substrate Distribution Alignment (ESDA) enforces distributional consistency within the PLM manifold in a reproducing kernel Hilbert space. Experiments across three kinetic endpoints and multiple PLM backbones, ERBA delivers consistent gains and stronger out-of-distribution performance compared with sequence-only and shallow-fusion baselines, offering a biologically grounded route to scalable kinetic prediction and a foundation for adding cofactors, mutations, and time-resolved structural cues.
Temporal Difference Learning with Constrained Initial Representations
Feb 12, 2026Recently, there have been numerous attempts to enhance the sample efficiency of off-policy reinforcement learning (RL) agents when interacting with the environment, including architecture improvements and new algorithms. Despite these advances, they overlook the potential of directly constraining the initial representations of the input data, which can intuitively alleviate the distribution shift issue and stabilize training. In this paper, we introduce the Tanh function into the initial layer to fulfill such a constraint. We theoretically unpack the convergence property of the temporal difference learning with the Tanh function under linear function approximation. Motivated by theoretical insights, we present our Constrained Initial Representations framework, tagged CIR, which is made up of three components: (i) the Tanh activation along with normalization methods to stabilize representations; (ii) the skip connection module to provide a linear pathway from the shallow layer to the deep layer; (iii) the convex Q-learning that allows a more flexible value estimate and mitigates potential conservatism. Empirical results show that CIR exhibits strong performance on numerous continuous control tasks, even being competitive or surpassing existing strong baseline methods.
Cross-Domain Offline Policy Adaptation via Selective Transition Correction
Feb 05, 2026It remains a critical challenge to adapt policies across domains with mismatched dynamics in reinforcement learning (RL). In this paper, we study cross-domain offline RL, where an offline dataset from another similar source domain can be accessed to enhance policy learning upon a target domain dataset. Directly merging the two datasets may lead to suboptimal performance due to potential dynamics mismatches. Existing approaches typically mitigate this issue through source domain transition filtering or reward modification, which, however, may lead to insufficient exploitation of the valuable source domain data. Instead, we propose to modify the source domain data into the target domain data. To that end, we leverage an inverse policy model and a reward model to correct the actions and rewards of source transitions, explicitly achieving alignment with the target dynamics. Since limited data may result in inaccurate model training, we further employ a forward dynamics model to retain corrected samples that better match the target dynamics than the original transitions. Consequently, we propose the Selective Transition Correction (STC) algorithm, which enables reliable usage of source domain data for policy adaptation. Experiments on various environments with dynamics shifts demonstrate that STC achieves superior performance against existing baselines.
Transferable Graph Condensation from the Causal Perspective
Jan 29, 2026The increasing scale of graph datasets has significantly improved the performance of graph representation learning methods, but it has also introduced substantial training challenges. Graph dataset condensation techniques have emerged to compress large datasets into smaller yet information-rich datasets, while maintaining similar test performance. However, these methods strictly require downstream applications to match the original dataset and task, which often fails in cross-task and cross-domain scenarios. To address these challenges, we propose a novel causal-invariance-based and transferable graph dataset condensation method, named \textbf{TGCC}, providing effective and transferable condensed datasets. Specifically, to preserve domain-invariant knowledge, we first extract domain causal-invariant features from the spatial domain of the graph using causal interventions. Then, to fully capture the structural and feature information of the original graph, we perform enhanced condensation operations. Finally, through spectral-domain enhanced contrastive learning, we inject the causal-invariant features into the condensed graph, ensuring that the compressed graph retains the causal information of the original graph. Experimental results on five public datasets and our novel \textbf{FinReport} dataset demonstrate that TGCC achieves up to a 13.41\% improvement in cross-task and cross-domain complex scenarios compared to existing methods, and achieves state-of-the-art performance on 5 out of 6 datasets in the single dataset and task scenario.
RubricHub: A Comprehensive and Highly Discriminative Rubric Dataset via Automated Coarse-to-Fine Generation
Jan 13, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has driven substantial progress in reasoning-intensive domains like mathematics. However, optimizing open-ended generation remains challenging due to the lack of ground truth. While rubric-based evaluation offers a structured proxy for verification, existing methods suffer from scalability bottlenecks and coarse criteria, resulting in a supervision ceiling effect. To address this, we propose an automated Coarse-to-Fine Rubric Generation framework. By synergizing principle-guided synthesis, multi-model aggregation, and difficulty evolution, our approach produces comprehensive and highly discriminative criteria capable of capturing the subtle nuances. Based on this framework, we introduce RubricHub, a large-scale ($\sim$110k) and multi-domain dataset. We validate its utility through a two-stage post-training pipeline comprising Rubric-based Rejection Sampling Fine-Tuning (RuFT) and Reinforcement Learning (RuRL). Experimental results demonstrate that RubricHub unlocks significant performance gains: our post-trained Qwen3-14B achieves state-of-the-art (SOTA) results on HealthBench (69.3), surpassing proprietary frontier models such as GPT-5. The code and data will be released soon.
Decoding the Ear: A Framework for Objectifying Expressiveness from Human Preference Through Efficient Alignment
Oct 23, 2025Recent speech-to-speech (S2S) models generate intelligible speech but still lack natural expressiveness, largely due to the absence of a reliable evaluation metric. Existing approaches, such as subjective MOS ratings, low-level acoustic features, and emotion recognition are costly, limited, or incomplete. To address this, we present DeEAR (Decoding the Expressive Preference of eAR), a framework that converts human preference for speech expressiveness into an objective score. Grounded in phonetics and psychology, DeEAR evaluates speech across three dimensions: Emotion, Prosody, and Spontaneity, achieving strong alignment with human perception (Spearman's Rank Correlation Coefficient, SRCC = 0.86) using fewer than 500 annotated samples. Beyond reliable scoring, DeEAR enables fair benchmarking and targeted data curation. It not only distinguishes expressiveness gaps across S2S models but also selects 14K expressive utterances to form ExpressiveSpeech, which improves the expressive score (from 2.0 to 23.4 on a 100-point scale) of S2S models. Demos and codes are available at https://github.com/FreedomIntelligence/ExpressiveSpeech
Breaking the Exploration Bottleneck: Rubric-Scaffolded Reinforcement Learning for General LLM Reasoning
Aug 23, 2025Recent advances in Large Language Models (LLMs) have underscored the potential of Reinforcement Learning (RL) to facilitate the emergence of reasoning capabilities. Despite the encouraging results, a fundamental dilemma persists as RL improvement relies on learning from high-quality samples, yet the exploration for such samples remains bounded by the inherent limitations of LLMs. This, in effect, creates an undesirable cycle in which what cannot be explored cannot be learned. In this work, we propose Rubric-Scaffolded Reinforcement Learning (RuscaRL), a novel instructional scaffolding framework designed to break the exploration bottleneck for general LLM reasoning. Specifically, RuscaRL introduces checklist-style rubrics as (1) explicit scaffolding for exploration during rollout generation, where different rubrics are provided as external guidance within task instructions to steer diverse high-quality responses. This guidance is gradually decayed over time, encouraging the model to internalize the underlying reasoning patterns; (2) verifiable rewards for exploitation during model training, where we can obtain robust LLM-as-a-Judge scores using rubrics as references, enabling effective RL on general reasoning tasks. Extensive experiments demonstrate the superiority of the proposed RuscaRL across various benchmarks, effectively expanding reasoning boundaries under the best-of-N evaluation. Notably, RuscaRL significantly boosts Qwen-2.5-7B-Instruct from 23.6 to 50.3 on HealthBench-500, surpassing GPT-4.1. Furthermore, our fine-tuned variant on Qwen3-30B-A3B-Instruct achieves 61.1 on HealthBench-500, outperforming leading LLMs including OpenAI-o3.
Infi-Med: Low-Resource Medical MLLMs with Robust Reasoning Evaluation
May 29, 2025
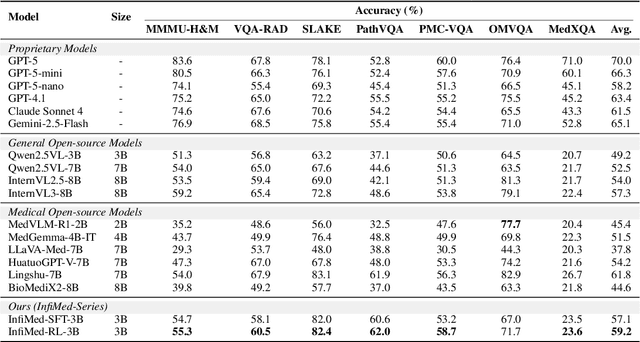
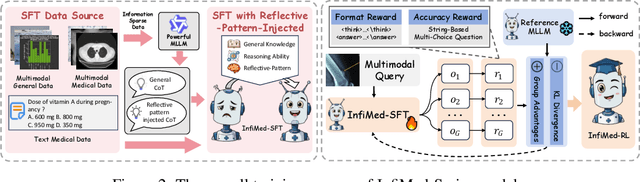
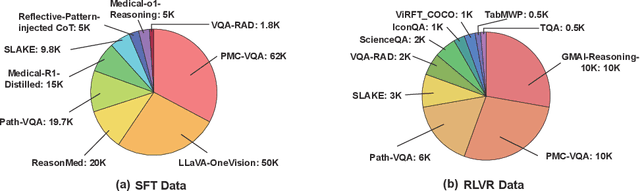
Multimodal large language models (MLLMs) have demonstrated promising prospects in healthcare, particularly for addressing complex medical tasks, supporting multidisciplinary treatment (MDT), and enabling personalized precision medicine. However, their practical deployment faces critical challenges in resource efficiency, diagnostic accuracy, clinical considerations, and ethical privacy. To address these limitations, we propose Infi-Med, a comprehensive framework for medical MLLMs that introduces three key innovations: (1) a resource-efficient approach through curating and constructing high-quality supervised fine-tuning (SFT) datasets with minimal sample requirements, with a forward-looking design that extends to both pretraining and posttraining phases; (2) enhanced multimodal reasoning capabilities for cross-modal integration and clinical task understanding; and (3) a systematic evaluation system that assesses model performance across medical modalities and task types. Our experiments demonstrate that Infi-Med achieves state-of-the-art (SOTA) performance in general medical reasoning while maintaining rapid adaptability to clinical scenarios. The framework establishes a solid foundation for deploying MLLMs in real-world healthcare settings by balancing model effectiveness with operational constraints.
Overlap-Adaptive Hybrid Speaker Diarization and ASR-Aware Observation Addition for MISP 2025 Challenge
May 28, 2025This paper presents the system developed to address the MISP 2025 Challenge. For the diarization system, we proposed a hybrid approach combining a WavLM end-to-end segmentation method with a traditional multi-module clustering technique to adaptively select the appropriate model for handling varying degrees of overlapping speech. For the automatic speech recognition (ASR) system, we proposed an ASR-aware observation addition method that compensates for the performance limitations of Guided Source Separation (GSS) under low signal-to-noise ratio conditions. Finally, we integrated the speaker diarization and ASR systems in a cascaded architecture to address Track 3. Our system achieved character error rates (CER) of 9.48% on Track 2 and concatenated minimum permutation character error rate (cpCER) of 11.56% on Track 3, ultimately securing first place in both tracks and thereby demonstrating the effectiveness of the proposed methods in real-world meeting scenarios.