 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuon$^2$: Boosting Muon via Adaptive Second-Moment Preconditioning
Apr 11, 2026Muon has emerged as a promising optimizer for large-scale foundation model pre-training by exploiting the matrix structure of neural network updates through iterative orthogonalization. However, its practical efficiency is limited by the need for multiple Newton--Schulz (NS) iterations per optimization step, which introduces non-trivial computation and communication overhead. We propose Muon$^2$, an extension of Muon that applies Adam-style adaptive second-moment preconditioning before orthogonalization. Our key insight is that the core challenge of polar approximation in Muon lies in the ill-conditioned momentum matrix, of which the spectrum is substantially improved by Muon$^2$, leading to faster convergence toward a practically sufficient orthogonalization. We further characterize the practical orthogonalization quality via directional alignment, under which Muon$^2$ demonstrates dramatic improvement over Muon at each polar step. Across GPT and LLaMA pre-training experiments from 60M to 1.3B parameters, Muon$^2$ consistently outperforms Muon and recent Muon variants while reducing NS iterations by 40\%. We further introduce Muon$^2$-F, a memory-efficient factorized variant that preserves most of the gains of Muon$^2$ with negligible memory overhead.
TEON: Tensorized Orthonormalization Beyond Layer-Wise Muon for Large Language Model Pre-Training
Jan 30, 2026The Muon optimizer has demonstrated strong empirical performance in pre-training large language models by performing matrix-level gradient (or momentum) orthogonalization in each layer independently. In this work, we propose TEON, a principled generalization of Muon that extends orthogonalization beyond individual layers by modeling the gradients of a neural network as a structured higher-order tensor. We present TEON's improved convergence guarantee over layer-wise Muon, and further develop a practical instantiation of TEON based on the theoretical analysis with corresponding ablation. We evaluate our approach on two widely adopted architectures: GPT-style models, ranging from 130M to 774M parameters, and LLaMA-style models, ranging from 60M to 1B parameters. Experimental results show that TEON consistently improves training and validation perplexity across model scales and exhibits strong robustness under various approximate SVD schemes.
InfiJanice: Joint Analysis and In-situ Correction Engine for Quantization-Induced Math Degradation in Large Language Models
May 16, 2025



Large Language Models (LLMs) have demonstrated impressive performance on complex reasoning benchmarks such as GSM8K, MATH, and AIME. However, the substantial computational demands of these tasks pose significant challenges for real-world deployment. Model quantization has emerged as a promising approach to reduce memory footprint and inference latency by representing weights and activations with lower bit-widths. In this work, we conduct a comprehensive study of mainstream quantization methods(e.g., AWQ, GPTQ, SmoothQuant) on the most popular open-sourced models (e.g., Qwen2.5, LLaMA3 series), and reveal that quantization can degrade mathematical reasoning accuracy by up to 69.81%. To better understand this degradation, we develop an automated assignment and judgment pipeline that qualitatively categorizes failures into four error types and quantitatively identifies the most impacted reasoning capabilities. Building on these findings, we employ an automated data-curation pipeline to construct a compact "Silver Bullet" datasets. Training a quantized model on as few as 332 carefully selected examples for just 3-5 minutes on a single GPU is enough to restore its reasoning accuracy to match that of the full-precision baseline.
Quantization Meets Reasoning: Exploring LLM Low-Bit Quantization Degradation for Mathematical Reasoning
Jan 06, 2025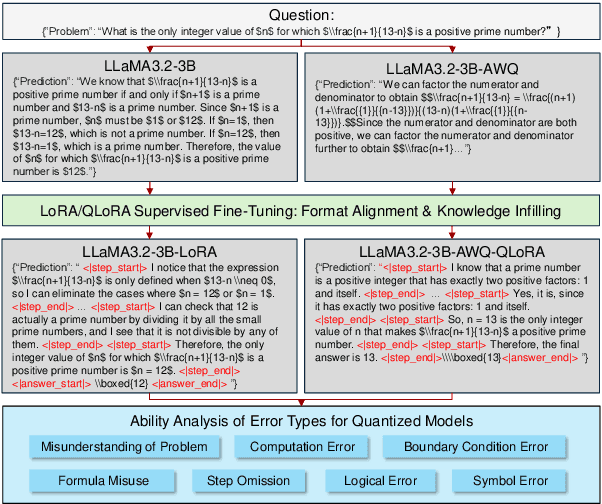
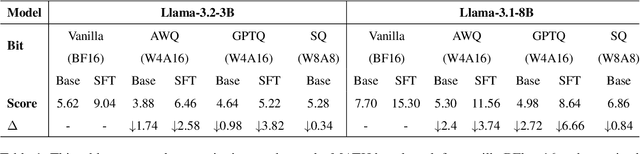

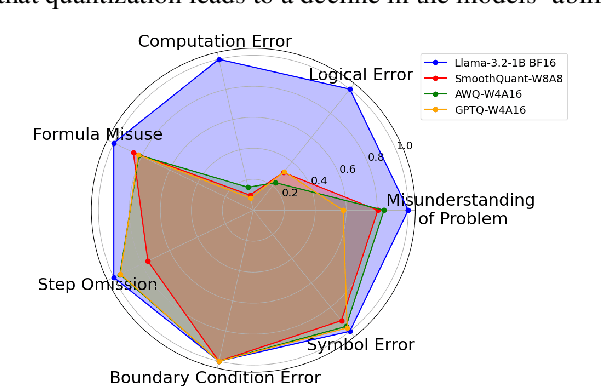
Large language models have achieved significant advancements in complex mathematical reasoning benchmarks, such as MATH. However, their substantial computational requirements present challenges for practical deployment. Model quantization has emerged as an effective strategy to reduce memory usage and computational costs by employing lower precision and bit-width representations. In this study, we systematically evaluate the impact of quantization on mathematical reasoning tasks. We introduce a multidimensional evaluation framework that qualitatively assesses specific capability dimensions and conduct quantitative analyses on the step-by-step outputs of various quantization methods. Our results demonstrate that quantization differentially affects numerical computation and reasoning planning abilities, identifying key areas where quantized models experience performance degradation.
LLM-Barber: Block-Aware Rebuilder for Sparsity Mask in One-Shot for Large Language Models
Aug 20, 2024Large language models (LLMs) have grown significantly in scale, leading to a critical need for efficient model pruning techniques. Existing post-training pruning techniques primarily focus on measuring weight importance on converged dense models to determine salient weights to retain. However, they often overlook the changes in weight importance during the pruning process, which can lead to performance degradation in the pruned models. To address this issue, we present LLM-Barber (Block-Aware Rebuilder for Sparsity Mask in One-Shot), a novel one-shot pruning framework that rebuilds the sparsity mask of pruned models without any retraining or weight reconstruction. LLM-Barber incorporates block-aware error optimization across Self-Attention and MLP blocks, ensuring global performance optimization. Inspired by the recent discovery of prominent outliers in LLMs, LLM-Barber introduces an innovative pruning metric that identifies weight importance using weights multiplied by gradients. Our experiments show that LLM-Barber can efficiently prune models like LLaMA and OPT families with 7B to 13B parameters on a single A100 GPU in just 30 minutes, achieving state-of-the-art results in both perplexity and zero-shot performance across various language benchmarks. Code is available at https://github.com/YupengSu/LLM-Barber.
APTQ: Attention-aware Post-Training Mixed-Precision Quantization for Large Language Models
Feb 21, 2024Large Language Models (LLMs) have greatly advanced the natural language processing paradigm. However, the high computational load and huge model sizes pose a grand challenge for deployment on edge devices. To this end, we propose APTQ (Attention-aware Post-Training Mixed-Precision Quantization) for LLMs, which considers not only the second-order information of each layer's weights, but also, for the first time, the nonlinear effect of attention outputs on the entire model. We leverage the Hessian trace as a sensitivity metric for mixed-precision quantization, ensuring an informed precision reduction that retains model performance. Experiments show APTQ surpasses previous quantization methods, achieving an average of 4 bit width a 5.22 perplexity nearly equivalent to full precision in the C4 dataset. In addition, APTQ attains state-of-the-art zero-shot accuracy of 68.24\% and 70.48\% at an average bitwidth of 3.8 in LLaMa-7B and LLaMa-13B, respectively, demonstrating its effectiveness to produce high-quality quantized LLMs.