 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfiMed-Foundation: Pioneering Advanced Multimodal Medical Models with Compute-Efficient Pre-Training and Multi-Stage Fine-Tuning
Sep 26, 2025



Multimodal large language models (MLLMs) have shown remarkable potential in various domains, yet their application in the medical field is hindered by several challenges. General-purpose MLLMs often lack the specialized knowledge required for medical tasks, leading to uncertain or hallucinatory responses. Knowledge distillation from advanced models struggles to capture domain-specific expertise in radiology and pharmacology. Additionally, the computational cost of continual pretraining with large-scale medical data poses significant efficiency challenges. To address these issues, we propose InfiMed-Foundation-1.7B and InfiMed-Foundation-4B, two medical-specific MLLMs designed to deliver state-of-the-art performance in medical applications. We combined high-quality general-purpose and medical multimodal data and proposed a novel five-dimensional quality assessment framework to curate high-quality multimodal medical datasets. We employ low-to-high image resolution and multimodal sequence packing to enhance training efficiency, enabling the integration of extensive medical data. Furthermore, a three-stage supervised fine-tuning process ensures effective knowledge extraction for complex medical tasks. Evaluated on the MedEvalKit framework, InfiMed-Foundation-1.7B outperforms Qwen2.5VL-3B, while InfiMed-Foundation-4B surpasses HuatuoGPT-V-7B and MedGemma-27B-IT, demonstrating superior performance in medical visual question answering and diagnostic tasks. By addressing key challenges in data quality, training efficiency, and domain-specific knowledge extraction, our work paves the way for more reliable and effective AI-driven solutions in healthcare. InfiMed-Foundation-4B model is available at \href{https://huggingface.co/InfiX-ai/InfiMed-Foundation-4B}{InfiMed-Foundation-4B}.
Infi-Med: Low-Resource Medical MLLMs with Robust Reasoning Evaluation
May 29, 2025
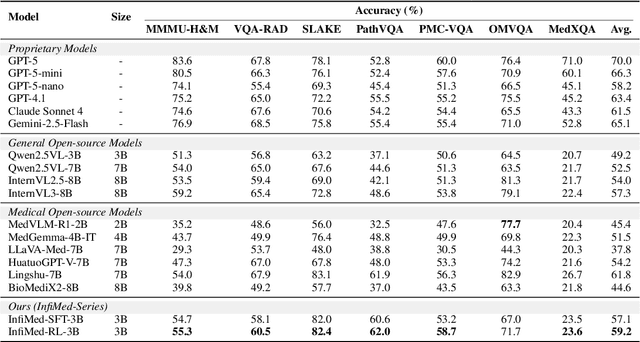
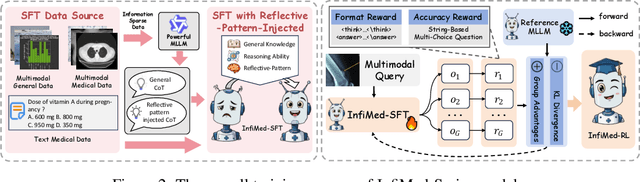
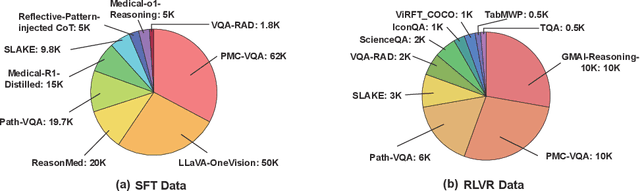
Multimodal large language models (MLLMs) have demonstrated promising prospects in healthcare, particularly for addressing complex medical tasks, supporting multidisciplinary treatment (MDT), and enabling personalized precision medicine. However, their practical deployment faces critical challenges in resource efficiency, diagnostic accuracy, clinical considerations, and ethical privacy. To address these limitations, we propose Infi-Med, a comprehensive framework for medical MLLMs that introduces three key innovations: (1) a resource-efficient approach through curating and constructing high-quality supervised fine-tuning (SFT) datasets with minimal sample requirements, with a forward-looking design that extends to both pretraining and posttraining phases; (2) enhanced multimodal reasoning capabilities for cross-modal integration and clinical task understanding; and (3) a systematic evaluation system that assesses model performance across medical modalities and task types. Our experiments demonstrate that Infi-Med achieves state-of-the-art (SOTA) performance in general medical reasoning while maintaining rapid adaptability to clinical scenarios. The framework establishes a solid foundation for deploying MLLMs in real-world healthcare settings by balancing model effectiveness with operational constraints.