 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReCo: Region-Controlled Text-to-Image Generation
Nov 23, 2022Recently, large-scale text-to-image (T2I) models have shown impressive performance in generating high-fidelity images, but with limited controllability, e.g., precisely specifying the content in a specific region with a free-form text description. In this paper, we propose an effective technique for such regional control in T2I generation. We augment T2I models' inputs with an extra set of position tokens, which represent the quantized spatial coordinates. Each region is specified by four position tokens to represent the top-left and bottom-right corners, followed by an open-ended natural language regional description. Then, we fine-tune a pre-trained T2I model with such new input interface. Our model, dubbed as ReCo (Region-Controlled T2I), enables the region control for arbitrary objects described by open-ended regional texts rather than by object labels from a constrained category set. Empirically, ReCo achieves better image quality than the T2I model strengthened by positional words (FID: 8.82->7.36, SceneFID: 15.54->6.51 on COCO), together with objects being more accurately placed, amounting to a 20.40% region classification accuracy improvement on COCO. Furthermore, we demonstrate that ReCo can better control the object count, spatial relationship, and region attributes such as color/size, with the free-form regional description. Human evaluation on PaintSkill shows that ReCo is +19.28% and +17.21% more accurate in generating images with correct object count and spatial relationship than the T2I model.
MACSum: Controllable Summarization with Mixed Attributes
Nov 09, 2022Controllable summarization allows users to generate customized summaries with specified attributes. However, due to the lack of designated annotations of controlled summaries, existing works have to craft pseudo datasets by adapting generic summarization benchmarks. Furthermore, most research focuses on controlling single attributes individually (e.g., a short summary or a highly abstractive summary) rather than controlling a mix of attributes together (e.g., a short and highly abstractive summary). In this paper, we propose MACSum, the first human-annotated summarization dataset for controlling mixed attributes. It contains source texts from two domains, news articles and dialogues, with human-annotated summaries controlled by five designed attributes (Length, Extractiveness, Specificity, Topic, and Speaker). We propose two simple and effective parameter-efficient approaches for the new task of mixed controllable summarization based on hard prompt tuning and soft prefix tuning. Results and analysis demonstrate that hard prompt models yield the best performance on all metrics and human evaluations. However, mixed-attribute control is still challenging for summarization tasks. Our dataset and code are available at https://github.com/psunlpgroup/MACSum.
A comprehensive study on self-supervised distillation for speaker representation learning
Oct 28, 2022



In real application scenarios, it is often challenging to obtain a large amount of labeled data for speaker representation learning due to speaker privacy concerns. Self-supervised learning with no labels has become a more and more promising way to solve it. Compared with contrastive learning, self-distilled approaches use only positive samples in the loss function and thus are more attractive. In this paper, we present a comprehensive study on self-distilled self-supervised speaker representation learning, especially on critical data augmentation. Our proposed strategy of audio perturbation augmentation has pushed the performance of the speaker representation to a new limit. The experimental results show that our model can achieve a new SoTA on Voxceleb1 speaker verification evaluation benchmark ( i.e., equal error rate (EER) 2.505%, 2.473%, and 4.791% for trial Vox1-O, Vox1-E and Vox1-H , respectively), discarding any speaker labels in the training phase.
Task Compass: Scaling Multi-task Pre-training with Task Prefix
Oct 12, 2022
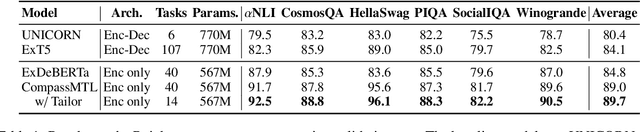
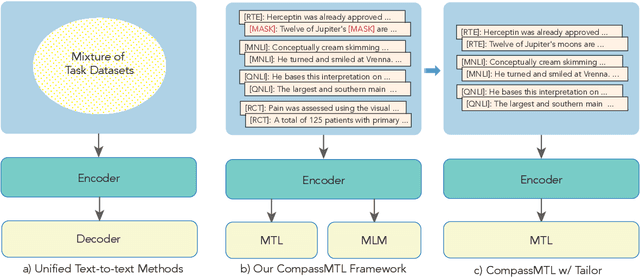
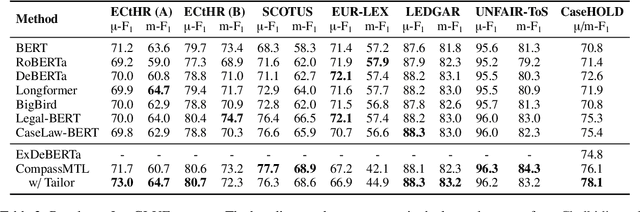
Leveraging task-aware annotated data as supervised signals to assist with self-supervised learning on large-scale unlabeled data has become a new trend in pre-training language models. Existing studies show that multi-task learning with large-scale supervised tasks suffers from negative effects across tasks. To tackle the challenge, we propose a task prefix guided multi-task pre-training framework to explore the relationships among tasks. We conduct extensive experiments on 40 datasets, which show that our model can not only serve as the strong foundation backbone for a wide range of tasks but also be feasible as a probing tool for analyzing task relationships. The task relationships reflected by the prefixes align transfer learning performance between tasks. They also suggest directions for data augmentation with complementary tasks, which help our model achieve human-parity results on commonsense reasoning leaderboards. Code is available at https://github.com/cooelf/CompassMTL
Generate rather than Retrieve: Large Language Models are Strong Context Generators
Sep 29, 2022
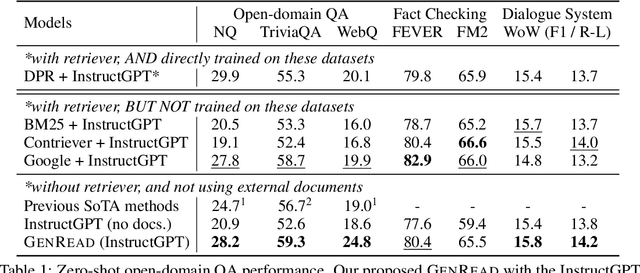
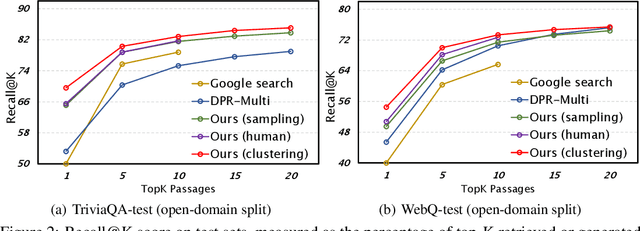
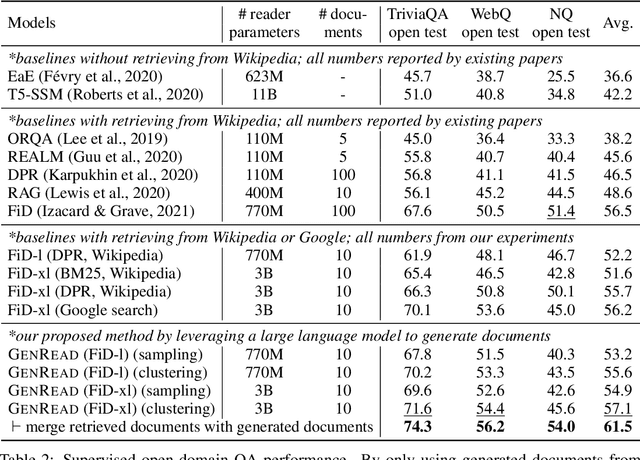
Knowledge-intensive tasks, such as open-domain question answering (QA), require access to a large amount of world or domain knowledge. A common approach for knowledge-intensive tasks is to employ a retrieve-then-read pipeline that first retrieves a handful of relevant contextual documents from an external corpus such as Wikipedia and then predicts an answer conditioned on the retrieved documents. In this paper, we present a novel perspective for solving knowledge-intensive tasks by replacing document retrievers with large language model generators. We call our method generate-then-read (GenRead), which first prompts a large language model to generate contextutal documents based on a given question, and then reads the generated documents to produce the final answer. Furthermore, we propose a novel clustering-based prompting method that selects distinct prompts, resulting in the generated documents that cover different perspectives, leading to better recall over acceptable answers. We conduct extensive experiments on three different knowledge-intensive tasks, including open-domain QA, fact checking, and dialogue system. Notably, GenRead achieves 71.6 and 54.4 exact match scores on TriviaQA and WebQ, significantly outperforming the state-of-the-art retrieve-then-read pipeline DPR-FiD by +4.0 and +3.9, without retrieving any documents from any external knowledge source. Lastly, we demonstrate the model performance can be further improved by combining retrieval and generation.
Z-Code++: A Pre-trained Language Model Optimized for Abstractive Summarization
Aug 21, 2022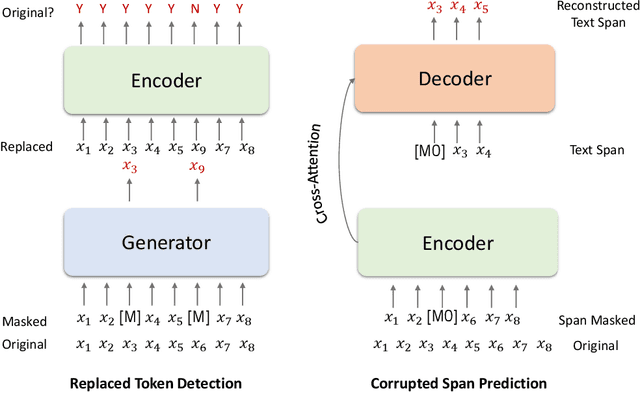

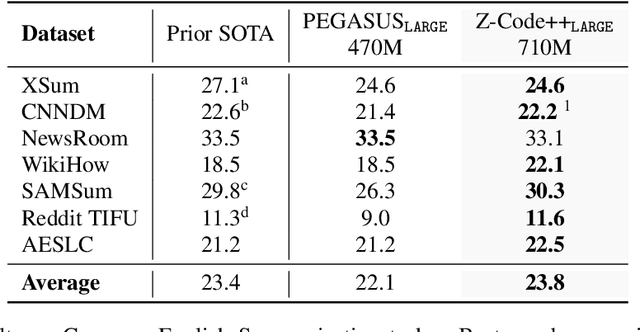
This paper presents Z-Code++, a new pre-trained language model optimized for abstractive text summarization. The model extends the state of the art encoder-decoder model using three techniques. First, we use a two-phase pre-training process to improve model's performance on low-resource summarization tasks. The model is first pre-trained using text corpora for language understanding, and then is continually pre-trained on summarization corpora for grounded text generation. Second, we replace self-attention layers in the encoder with disentangled attention layers, where each word is represented using two vectors that encode its content and position, respectively. Third, we use fusion-in-encoder, a simple yet effective method of encoding long sequences in a hierarchical manner. Z-Code++ creates new state of the art on 9 out of 13 text summarization tasks across 5 languages. Our model is parameter-efficient in that it outperforms the 600x larger PaLM-540B on XSum, and the finetuned 200x larger GPT3-175B on SAMSum. In zero-shot and few-shot settings, our model substantially outperforms the competing models.
Visual Clues: Bridging Vision and Language Foundations for Image Paragraph Captioning
Jun 03, 2022

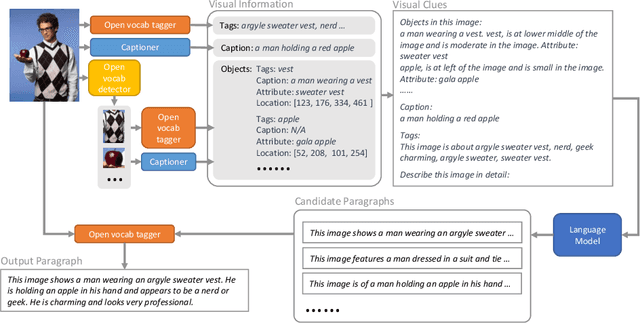
People say, "A picture is worth a thousand words". Then how can we get the rich information out of the image? We argue that by using visual clues to bridge large pretrained vision foundation models and language models, we can do so without any extra cross-modal training. Thanks to the strong zero-shot capability of foundation models, we start by constructing a rich semantic representation of the image (e.g., image tags, object attributes / locations, captions) as a structured textual prompt, called visual clues, using a vision foundation model. Based on visual clues, we use large language model to produce a series of comprehensive descriptions for the visual content, which is then verified by the vision model again to select the candidate that aligns best with the image. We evaluate the quality of generated descriptions by quantitative and qualitative measurement. The results demonstrate the effectiveness of such a structured semantic representation.
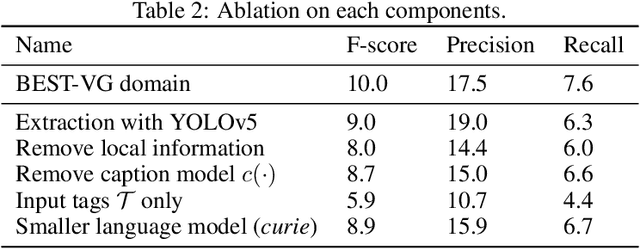
Automatic Rule Induction for Efficient Semi-Supervised Learning
May 20, 2022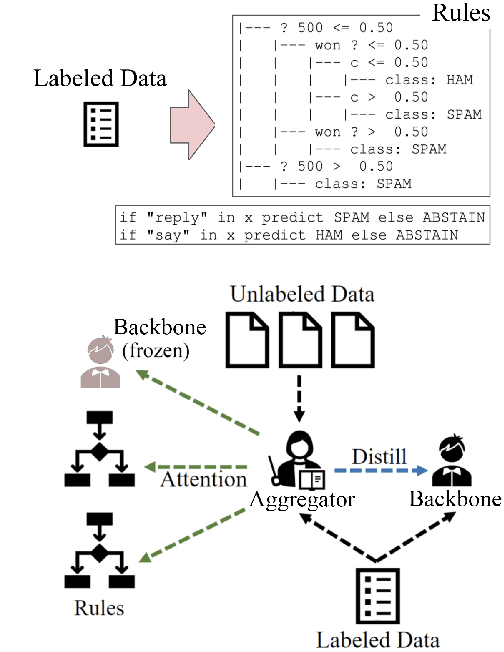
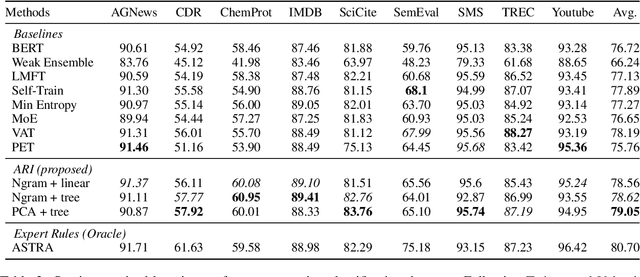
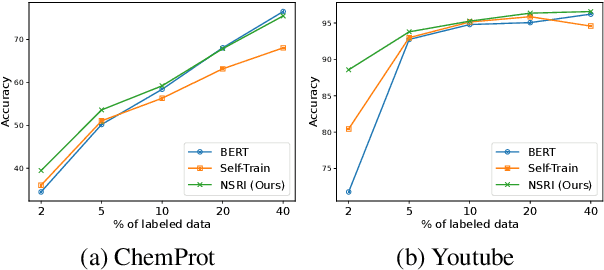
Semi-supervised learning has shown promise in allowing NLP models to generalize from small amounts of labeled data. Meanwhile, pretrained transformer models act as black-box correlation engines that are difficult to explain and sometimes behave unreliably. In this paper, we propose tackling both of these challenges via Automatic Rule Induction (ARI), a simple and general-purpose framework for the automatic discovery and integration of symbolic rules into pretrained transformer models. First, we extract weak symbolic rules from low-capacity machine learning models trained on small amounts of labeled data. Next, we use an attention mechanism to integrate these rules into high-capacity pretrained transformer models. Last, the rule-augmented system becomes part of a self-training framework to boost supervision signal on unlabeled data. These steps can be layered beneath a variety of existing weak supervision and semi-supervised NLP algorithms in order to improve performance and interpretability. Experiments across nine sequence classification and relation extraction tasks suggest that ARI can improve state-of-the-art methods with no manual effort and minimal computational overhead.
i-Code: An Integrative and Composable Multimodal Learning Framework
May 05, 2022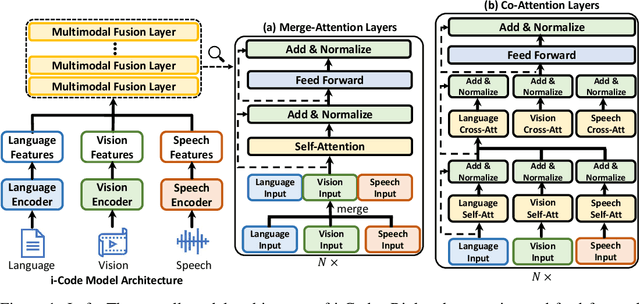
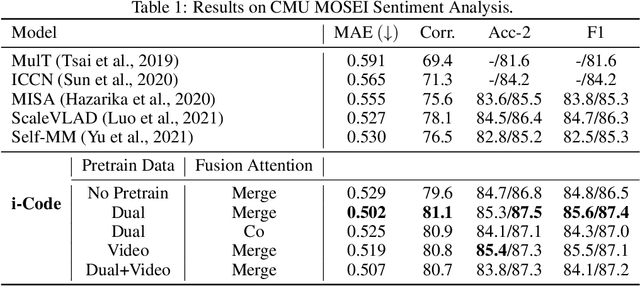
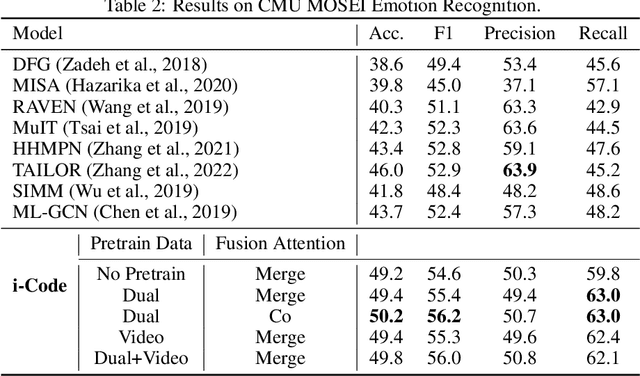

Human intelligence is multimodal; we integrate visual, linguistic, and acoustic signals to maintain a holistic worldview. Most current pretraining methods, however, are limited to one or two modalities. We present i-Code, a self-supervised pretraining framework where users may flexibly combine the modalities of vision, speech, and language into unified and general-purpose vector representations. In this framework, data from each modality are first given to pretrained single-modality encoders. The encoder outputs are then integrated with a multimodal fusion network, which uses novel attention mechanisms and other architectural innovations to effectively combine information from the different modalities. The entire system is pretrained end-to-end with new objectives including masked modality unit modeling and cross-modality contrastive learning. Unlike previous research using only video for pretraining, the i-Code framework can dynamically process single, dual, and triple-modality data during training and inference, flexibly projecting different combinations of modalities into a single representation space. Experimental results demonstrate how i-Code can outperform state-of-the-art techniques on five video understanding tasks and the GLUE NLP benchmark, improving by as much as 11% and demonstrating the power of integrative multimodal pretraining.
Impossible Triangle: What's Next for Pre-trained Language Models?
Apr 20, 2022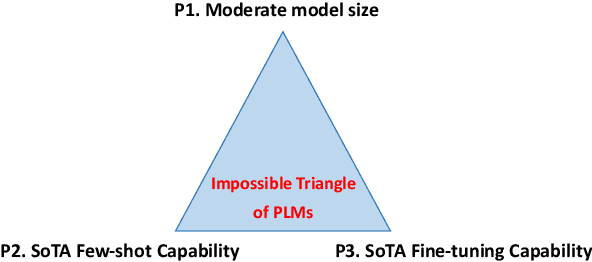
Recent development of large-scale pre-trained language models (PLM) have significantly improved the capability of models in various NLP tasks, in terms of performance after task-specific fine-tuning and zero-shot / few-shot learning. However, many of such models come with a dauntingly huge size that few institutions can afford to pre-train, fine-tune or even deploy, while moderate-sized models usually lack strong generalized few-shot learning capabilities. In this paper, we first elaborate the current obstacles of using PLM models in terms of the Impossible Triangle: 1) moderate model size, 2) state-of-the-art few-shot learning capability, and 3) state-of-the-art fine-tuning capability. We argue that all existing PLM models lack one or more properties from the Impossible Triangle. To remedy these missing properties of PLMs, various techniques have been proposed, such as knowledge distillation, data augmentation and prompt learning, which inevitably brings additional work to the application of PLMs in real scenarios. We then offer insights into future research directions of PLMs to achieve the Impossible Triangle, and break down the task into several key phases.