 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Apr 23, 2024



We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
Prompt Engineering a Prompt Engineer
Nov 09, 2023Prompt engineering is a challenging yet crucial task for optimizing the performance of large language models (LLMs). It requires complex reasoning to examine the model's errors, hypothesize what is missing or misleading in the current prompt, and communicate the task with clarity. While recent works indicate that LLMs can be meta-prompted to perform automatic prompt engineering, their potentials may not be fully untapped due to the lack of sufficient guidance to elicit complex reasoning capabilities in LLMs in the meta-prompt. In this work, we investigate the problem of "prompt engineering a prompt engineer" -- constructing a meta-prompt that more effectively guides LLMs to perform automatic prompt engineering. We introduce and analyze key components, such as a step-by-step reasoning template and context specification, which lead to improved performance. In addition, inspired by common optimization concepts such as batch size, step size and momentum, we introduce their verbalized counterparts to the meta-prompt and investigate their effects. Our final method, named PE2, finds a prompt that outperforms "let's think step by step" by 6.3% on the MultiArith dataset and 3.1% on the GSM8K dataset. To demonstrate its versatility, we apply PE2 to the Instruction Induction benchmark, a suite of counterfactual tasks, and a lengthy, real-world industrial prompt. In these settings, PE2 achieves strong performance and outperforms prior automatic prompt engineering baselines. Further, we show that PE2 makes meaningful and targeted prompt edits, amends erroneous or incomplete prompts, and presents non-trivial counterfactual reasoning abilities.
The Shifted and The Overlooked: A Task-oriented Investigation of User-GPT Interactions
Oct 19, 2023Recent progress in Large Language Models (LLMs) has produced models that exhibit remarkable performance across a variety of NLP tasks. However, it remains unclear whether the existing focus of NLP research accurately captures the genuine requirements of human users. This paper provides a comprehensive analysis of the divergence between current NLP research and the needs of real-world NLP applications via a large-scale collection of user-GPT conversations. We analyze a large-scale collection of real user queries to GPT. We compare these queries against existing NLP benchmark tasks and identify a significant gap between the tasks that users frequently request from LLMs and the tasks that are commonly studied in academic research. For example, we find that tasks such as ``design'' and ``planning'' are prevalent in user interactions but are largely neglected or different from traditional NLP benchmarks. We investigate these overlooked tasks, dissect the practical challenges they pose, and provide insights toward a roadmap to make LLMs better aligned with user needs.
Soft Convex Quantization: Revisiting Vector Quantization with Convex Optimization
Oct 04, 2023



Vector Quantization (VQ) is a well-known technique in deep learning for extracting informative discrete latent representations. VQ-embedded models have shown impressive results in a range of applications including image and speech generation. VQ operates as a parametric K-means algorithm that quantizes inputs using a single codebook vector in the forward pass. While powerful, this technique faces practical challenges including codebook collapse, non-differentiability and lossy compression. To mitigate the aforementioned issues, we propose Soft Convex Quantization (SCQ) as a direct substitute for VQ. SCQ works like a differentiable convex optimization (DCO) layer: in the forward pass, we solve for the optimal convex combination of codebook vectors that quantize the inputs. In the backward pass, we leverage differentiability through the optimality conditions of the forward solution. We then introduce a scalable relaxation of the SCQ optimization and demonstrate its efficacy on the CIFAR-10, GTSRB and LSUN datasets. We train powerful SCQ autoencoder models that significantly outperform matched VQ-based architectures, observing an order of magnitude better image reconstruction and codebook usage with comparable quantization runtime.
In-Context Demonstration Selection with Cross Entropy Difference
May 24, 2023Large language models (LLMs) can use in-context demonstrations to improve performance on zero-shot tasks. However, selecting the best in-context examples is challenging because model performance can vary widely depending on the selected examples. We present a cross-entropy difference (CED) method for selecting in-context demonstrations. Our method is based on the observation that the effectiveness of in-context demonstrations negatively correlates with the perplexity of the test example by a language model that was finetuned on that demonstration. We utilize parameter efficient finetuning to train small models on training data that are used for computing the cross-entropy difference between a test example and every candidate in-context demonstration. This metric is used to rank and select in-context demonstrations independently for each test input. We evaluate our method on a mix-domain dataset that combines 8 benchmarks, representing 4 text generation tasks, showing that CED for in-context demonstration selection can improve performance for a variety of LLMs.
i-Code Studio: A Configurable and Composable Framework for Integrative AI
May 23, 2023



Artificial General Intelligence (AGI) requires comprehensive understanding and generation capabilities for a variety of tasks spanning different modalities and functionalities. Integrative AI is one important direction to approach AGI, through combining multiple models to tackle complex multimodal tasks. However, there is a lack of a flexible and composable platform to facilitate efficient and effective model composition and coordination. In this paper, we propose the i-Code Studio, a configurable and composable framework for Integrative AI. The i-Code Studio orchestrates multiple pre-trained models in a finetuning-free fashion to conduct complex multimodal tasks. Instead of simple model composition, the i-Code Studio provides an integrative, flexible, and composable setting for developers to quickly and easily compose cutting-edge services and technologies tailored to their specific requirements. The i-Code Studio achieves impressive results on a variety of zero-shot multimodal tasks, such as video-to-text retrieval, speech-to-speech translation, and visual question answering. We also demonstrate how to quickly build a multimodal agent based on the i-Code Studio that can communicate and personalize for users.
i-Code V2: An Autoregressive Generation Framework over Vision, Language, and Speech Data
May 21, 2023



The convergence of text, visual, and audio data is a key step towards human-like artificial intelligence, however the current Vision-Language-Speech landscape is dominated by encoder-only models which lack generative abilities. We propose closing this gap with i-Code V2, the first model capable of generating natural language from any combination of Vision, Language, and Speech data. i-Code V2 is an integrative system that leverages state-of-the-art single-modality encoders, combining their outputs with a new modality-fusing encoder in order to flexibly project combinations of modalities into a shared representational space. Next, language tokens are generated from these representations via an autoregressive decoder. The whole framework is pretrained end-to-end on a large collection of dual- and single-modality datasets using a novel text completion objective that can be generalized across arbitrary combinations of modalities. i-Code V2 matches or outperforms state-of-the-art single- and dual-modality baselines on 7 multimodal tasks, demonstrating the power of generative multimodal pretraining across a diversity of tasks and signals.
Automatic Prompt Optimization with "Gradient Descent" and Beam Search
May 04, 2023Large Language Models (LLMs) have shown impressive performance as general purpose agents, but their abilities remain highly dependent on prompts which are hand written with onerous trial-and-error effort. We propose a simple and nonparametric solution to this problem, Automatic Prompt Optimization (APO), which is inspired by numerical gradient descent to automatically improve prompts, assuming access to training data and an LLM API. The algorithm uses minibatches of data to form natural language ``gradients'' that criticize the current prompt. The gradients are then ``propagated'' into the prompt by editing the prompt in the opposite semantic direction of the gradient. These gradient descent steps are guided by a beam search and bandit selection procedure which significantly improves algorithmic efficiency. Preliminary results across three benchmark NLP tasks and the novel problem of LLM jailbreak detection suggest that Automatic Prompt Optimization can outperform prior prompt editing techniques and improve an initial prompt's performance by up to 31\%, by using data to rewrite vague task descriptions into more precise annotation instructions.
APOLLO: A Simple Approach for Adaptive Pretraining of Language Models for Logical Reasoning
Dec 19, 2022



Logical reasoning of text is an important ability that requires understanding the information present in the text, their interconnections, and then reasoning through them to infer new conclusions. Prior works on improving the logical reasoning ability of language models require complex processing of training data (e.g., aligning symbolic knowledge to text), yielding task-specific data augmentation solutions that restrict the learning of general logical reasoning skills. In this work, we propose APOLLO, an adaptively pretrained language model that has improved logical reasoning abilities. We select a subset of Wikipedia, based on a set of logical inference keywords, for continued pretraining of a language model. We use two self-supervised loss functions: a modified masked language modeling loss where only specific parts-of-speech words, that would likely require more reasoning than basic language understanding, are masked, and a sentence-level classification loss that teaches the model to distinguish between entailment and contradiction types of sentences. The proposed training paradigm is both simple and independent of task formats. We demonstrate the effectiveness of APOLLO by comparing it with prior baselines on two logical reasoning datasets. APOLLO performs comparably on ReClor and outperforms baselines on LogiQA.
FAST: Improving Controllability for Text Generation with Feedback Aware Self-Training
Oct 06, 2022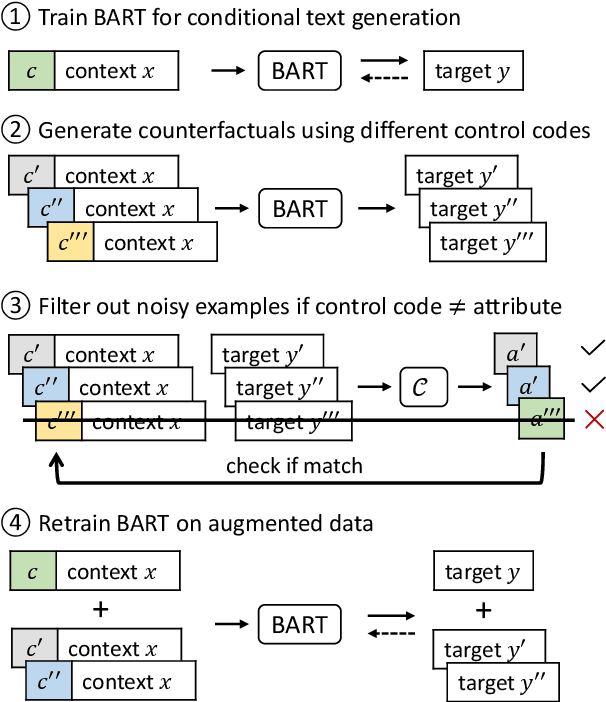
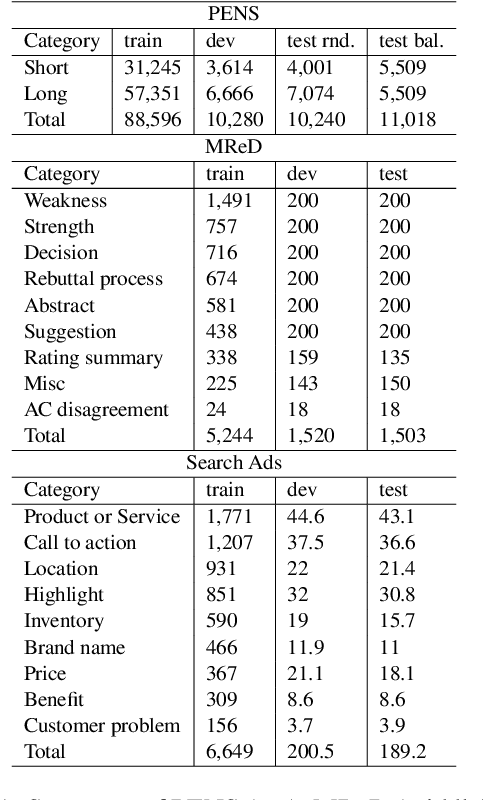
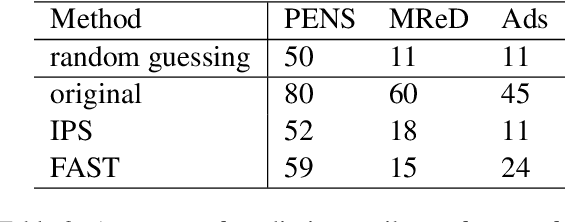

Controllable text generation systems often leverage control codes to direct various properties of the output like style and length. Inspired by recent work on causal inference for NLP, this paper reveals a previously overlooked flaw in these control code-based conditional text generation algorithms. Spurious correlations in the training data can lead models to incorrectly rely on parts of the input other than the control code for attribute selection, significantly undermining downstream generation quality and controllability. We demonstrate the severity of this issue with a series of case studies and then propose two simple techniques to reduce these correlations in training sets. The first technique is based on resampling the data according to an example's propensity towards each linguistic attribute (IPS). The second produces multiple counterfactual versions of each example and then uses an additional feedback mechanism to remove noisy examples (feedback aware self-training, FAST). We evaluate on 3 tasks -- news headline, meta review, and search ads generation -- and demonstrate that FAST can significantly improve the controllability and language quality of generated outputs when compared to state-of-the-art controllable text generation approaches.