 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Influence of Information Entropy Change in Learning Systems
Sep 19, 2023



In this work, we explore the influence of entropy change in deep learning systems by adding noise to the inputs/latent features. The applications in this paper focus on deep learning tasks within computer vision, but the proposed theory can be further applied to other fields. Noise is conventionally viewed as a harmful perturbation in various deep learning architectures, such as convolutional neural networks (CNNs) and vision transformers (ViTs), as well as different learning tasks like image classification and transfer learning. However, this paper aims to rethink whether the conventional proposition always holds. We demonstrate that specific noise can boost the performance of various deep architectures under certain conditions. We theoretically prove the enhancement gained from positive noise by reducing the task complexity defined by information entropy and experimentally show the significant performance gain in large image datasets, such as the ImageNet. Herein, we use the information entropy to define the complexity of the task. We categorize the noise into two types, positive noise (PN) and harmful noise (HN), based on whether the noise can help reduce the complexity of the task. Extensive experiments of CNNs and ViTs have shown performance improvements by proactively injecting positive noise, where we achieved an unprecedented top 1 accuracy of over 95% on ImageNet. Both theoretical analysis and empirical evidence have confirmed that the presence of positive noise can benefit the learning process, while the traditionally perceived harmful noise indeed impairs deep learning models. The different roles of noise offer new explanations for deep models on specific tasks and provide a new paradigm for improving model performance. Moreover, it reminds us that we can influence the performance of learning systems via information entropy change.
MARC: Multipolicy and Risk-aware Contingency Planning for Autonomous Driving
Sep 12, 2023



Generating safe and non-conservative behaviors in dense, dynamic environments remains challenging for automated vehicles due to the stochastic nature of traffic participants' behaviors and their implicit interaction with the ego vehicle. This paper presents a novel planning framework, Multipolicy And Risk-aware Contingency planning (MARC), that systematically addresses these challenges by enhancing the multipolicy-based pipelines from both behavior and motion planning aspects. Specifically, MARC realizes a critical scenario set that reflects multiple possible futures conditioned on each semantic-level ego policy. Then, the generated policy-conditioned scenarios are further formulated into a tree-structured representation with a dynamic branchpoint based on the scene-level divergence. Moreover, to generate diverse driving maneuvers, we introduce risk-aware contingency planning, a bi-level optimization algorithm that simultaneously considers multiple future scenarios and user-defined risk tolerance levels. Owing to the more unified combination of behavior and motion planning layers, our framework achieves efficient decision-making and human-like driving maneuvers. Comprehensive experimental results demonstrate superior performance to other strong baselines in various environments.
Short-term power load forecasting method based on CNN-SAEDN-Res
Sep 02, 2023In deep learning, the load data with non-temporal factors are difficult to process by sequence models. This problem results in insufficient precision of the prediction. Therefore, a short-term load forecasting method based on convolutional neural network (CNN), self-attention encoder-decoder network (SAEDN) and residual-refinement (Res) is proposed. In this method, feature extraction module is composed of a two-dimensional convolutional neural network, which is used to mine the local correlation between data and obtain high-dimensional data features. The initial load fore-casting module consists of a self-attention encoder-decoder network and a feedforward neural network (FFN). The module utilizes self-attention mechanisms to encode high-dimensional features. This operation can obtain the global correlation between data. Therefore, the model is able to retain important information based on the coupling relationship between the data in data mixed with non-time series factors. Then, self-attention decoding is per-formed and the feedforward neural network is used to regression initial load. This paper introduces the residual mechanism to build the load optimization module. The module generates residual load values to optimize the initial load. The simulation results show that the proposed load forecasting method has advantages in terms of prediction accuracy and prediction stability.
Meta-ZSDETR: Zero-shot DETR with Meta-learning
Aug 18, 2023Zero-shot object detection aims to localize and recognize objects of unseen classes. Most of existing works face two problems: the low recall of RPN in unseen classes and the confusion of unseen classes with background. In this paper, we present the first method that combines DETR and meta-learning to perform zero-shot object detection, named Meta-ZSDETR, where model training is formalized as an individual episode based meta-learning task. Different from Faster R-CNN based methods that firstly generate class-agnostic proposals, and then classify them with visual-semantic alignment module, Meta-ZSDETR directly predict class-specific boxes with class-specific queries and further filter them with the predicted accuracy from classification head. The model is optimized with meta-contrastive learning, which contains a regression head to generate the coordinates of class-specific boxes, a classification head to predict the accuracy of generated boxes, and a contrastive head that utilizes the proposed contrastive-reconstruction loss to further separate different classes in visual space. We conduct extensive experiments on two benchmark datasets MS COCO and PASCAL VOC. Experimental results show that our method outperforms the existing ZSD methods by a large margin.
Meta-learning enhanced next POI recommendation by leveraging check-ins from auxiliary cities
Aug 18, 2023Most existing point-of-interest (POI) recommenders aim to capture user preference by employing city-level user historical check-ins, thus facilitating users' exploration of the city. However, the scarcity of city-level user check-ins brings a significant challenge to user preference learning. Although prior studies attempt to mitigate this challenge by exploiting various context information, e.g., spatio-temporal information, they ignore to transfer the knowledge (i.e., common behavioral pattern) from other relevant cities (i.e., auxiliary cities). In this paper, we investigate the effect of knowledge distilled from auxiliary cities and thus propose a novel Meta-learning Enhanced next POI Recommendation framework (MERec). The MERec leverages the correlation of check-in behaviors among various cities into the meta-learning paradigm to help infer user preference in the target city, by holding the principle of "paying more attention to more correlated knowledge". Particularly, a city-level correlation strategy is devised to attentively capture common patterns among cities, so as to transfer more relevant knowledge from more correlated cities. Extensive experiments verify the superiority of the proposed MERec against state-of-the-art algorithms.
Evaluating Large Language Models for Radiology Natural Language Processing
Jul 27, 2023



The rise of large language models (LLMs) has marked a pivotal shift in the field of natural language processing (NLP). LLMs have revolutionized a multitude of domains, and they have made a significant impact in the medical field. Large language models are now more abundant than ever, and many of these models exhibit bilingual capabilities, proficient in both English and Chinese. However, a comprehensive evaluation of these models remains to be conducted. This lack of assessment is especially apparent within the context of radiology NLP. This study seeks to bridge this gap by critically evaluating thirty two LLMs in interpreting radiology reports, a crucial component of radiology NLP. Specifically, the ability to derive impressions from radiologic findings is assessed. The outcomes of this evaluation provide key insights into the performance, strengths, and weaknesses of these LLMs, informing their practical applications within the medical domain.
Tracking Anything in High Quality
Jul 26, 2023Visual object tracking is a fundamental video task in computer vision. Recently, the notably increasing power of perception algorithms allows the unification of single/multiobject and box/mask-based tracking. Among them, the Segment Anything Model (SAM) attracts much attention. In this report, we propose HQTrack, a framework for High Quality Tracking anything in videos. HQTrack mainly consists of a video multi-object segmenter (VMOS) and a mask refiner (MR). Given the object to be tracked in the initial frame of a video, VMOS propagates the object masks to the current frame. The mask results at this stage are not accurate enough since VMOS is trained on several closeset video object segmentation (VOS) datasets, which has limited ability to generalize to complex and corner scenes. To further improve the quality of tracking masks, a pretrained MR model is employed to refine the tracking results. As a compelling testament to the effectiveness of our paradigm, without employing any tricks such as test-time data augmentations and model ensemble, HQTrack ranks the 2nd place in the Visual Object Tracking and Segmentation (VOTS2023) challenge. Code and models are available at https://github.com/jiawen-zhu/HQTrack.
Exploiting Field Dependencies for Learning on Categorical Data
Jul 18, 2023Traditional approaches for learning on categorical data underexploit the dependencies between columns (\aka fields) in a dataset because they rely on the embedding of data points driven alone by the classification/regression loss. In contrast, we propose a novel method for learning on categorical data with the goal of exploiting dependencies between fields. Instead of modelling statistics of features globally (i.e., by the covariance matrix of features), we learn a global field dependency matrix that captures dependencies between fields and then we refine the global field dependency matrix at the instance-wise level with different weights (so-called local dependency modelling) w.r.t. each field to improve the modelling of the field dependencies. Our algorithm exploits the meta-learning paradigm, i.e., the dependency matrices are refined in the inner loop of the meta-learning algorithm without the use of labels, whereas the outer loop intertwines the updates of the embedding matrix (the matrix performing projection) and global dependency matrix in a supervised fashion (with the use of labels). Our method is simple yet it outperforms several state-of-the-art methods on six popular dataset benchmarks. Detailed ablation studies provide additional insights into our method.
Hierarchical Semantic Tree Concept Whitening for Interpretable Image Classification
Jul 10, 2023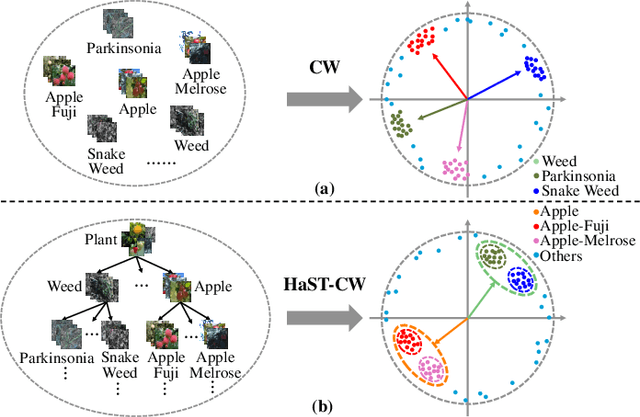
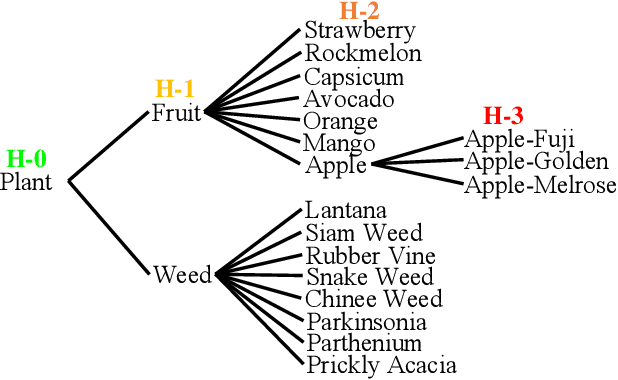
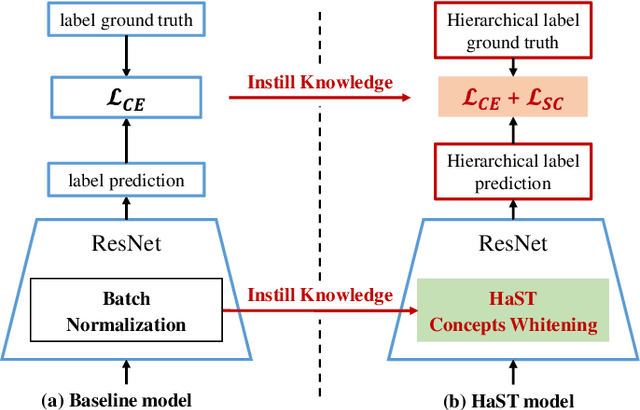
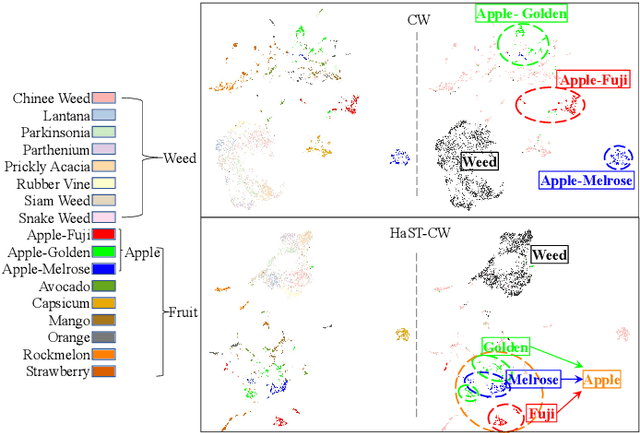
With the popularity of deep neural networks (DNNs), model interpretability is becoming a critical concern. Many approaches have been developed to tackle the problem through post-hoc analysis, such as explaining how predictions are made or understanding the meaning of neurons in middle layers. Nevertheless, these methods can only discover the patterns or rules that naturally exist in models. In this work, rather than relying on post-hoc schemes, we proactively instill knowledge to alter the representation of human-understandable concepts in hidden layers. Specifically, we use a hierarchical tree of semantic concepts to store the knowledge, which is leveraged to regularize the representations of image data instances while training deep models. The axes of the latent space are aligned with the semantic concepts, where the hierarchical relations between concepts are also preserved. Experiments on real-world image datasets show that our method improves model interpretability, showing better disentanglement of semantic concepts, without negatively affecting model classification performance.
Segment Anything Model (SAM) for Radiation Oncology
Jul 04, 2023



In this study, we evaluate the performance of the Segment Anything Model (SAM) in clinical radiotherapy. Our results indicate that SAM's 'segment anything' mode can achieve clinically acceptable segmentation results in most organs-at-risk (OARs) with Dice scores higher than 0.7. SAM's 'box prompt' mode further improves the Dice scores by 0.1 to 0.5. Considering the size of the organ and the clarity of its boundary, SAM displays better performance for large organs with clear boundaries but performs worse for smaller organs with unclear boundaries. Given that SAM, a model pre-trained purely on natural images, can handle the delineation of OARs from medical images with clinically acceptable accuracy, these results highlight SAM's robust generalization capabilities with consistent accuracy in automatic segmentation for radiotherapy. In other words, SAM can achieve delineation of different OARs at different sites using a generic automatic segmentation model. SAM's generalization capabilities across different disease sites suggest that it is technically feasible to develop a generic model for automatic segmentation in radiotherapy.