 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIRAL: Visual Sim-to-Real at Scale for Humanoid Loco-Manipulation
Nov 19, 2025



A key barrier to the real-world deployment of humanoid robots is the lack of autonomous loco-manipulation skills. We introduce VIRAL, a visual sim-to-real framework that learns humanoid loco-manipulation entirely in simulation and deploys it zero-shot to real hardware. VIRAL follows a teacher-student design: a privileged RL teacher, operating on full state, learns long-horizon loco-manipulation using a delta action space and reference state initialization. A vision-based student policy is then distilled from the teacher via large-scale simulation with tiled rendering, trained with a mixture of online DAgger and behavior cloning. We find that compute scale is critical: scaling simulation to tens of GPUs (up to 64) makes both teacher and student training reliable, while low-compute regimes often fail. To bridge the sim-to-real gap, VIRAL combines large-scale visual domain randomization over lighting, materials, camera parameters, image quality, and sensor delays--with real-to-sim alignment of the dexterous hands and cameras. Deployed on a Unitree G1 humanoid, the resulting RGB-based policy performs continuous loco-manipulation for up to 54 cycles, generalizing to diverse spatial and appearance variations without any real-world fine-tuning, and approaching expert-level teleoperation performance. Extensive ablations dissect the key design choices required to make RGB-based humanoid loco-manipulation work in practice.
DexUMI: Using Human Hand as the Universal Manipulation Interface for Dexterous Manipulation
May 29, 2025We present DexUMI - a data collection and policy learning framework that uses the human hand as the natural interface to transfer dexterous manipulation skills to various robot hands. DexUMI includes hardware and software adaptations to minimize the embodiment gap between the human hand and various robot hands. The hardware adaptation bridges the kinematics gap using a wearable hand exoskeleton. It allows direct haptic feedback in manipulation data collection and adapts human motion to feasible robot hand motion. The software adaptation bridges the visual gap by replacing the human hand in video data with high-fidelity robot hand inpainting. We demonstrate DexUMI's capabilities through comprehensive real-world experiments on two different dexterous robot hand hardware platforms, achieving an average task success rate of 86%.
SCIZOR: A Self-Supervised Approach to Data Curation for Large-Scale Imitation Learning
May 28, 2025Imitation learning advances robot capabilities by enabling the acquisition of diverse behaviors from human demonstrations. However, large-scale datasets used for policy training often introduce substantial variability in quality, which can negatively impact performance. As a result, automatically curating datasets by filtering low-quality samples to improve quality becomes essential. Existing robotic curation approaches rely on costly manual annotations and perform curation at a coarse granularity, such as the dataset or trajectory level, failing to account for the quality of individual state-action pairs. To address this, we introduce SCIZOR, a self-supervised data curation framework that filters out low-quality state-action pairs to improve the performance of imitation learning policies. SCIZOR targets two complementary sources of low-quality data: suboptimal data, which hinders learning with undesirable actions, and redundant data, which dilutes training with repetitive patterns. SCIZOR leverages a self-supervised task progress predictor for suboptimal data to remove samples lacking task progression, and a deduplication module operating on joint state-action representation for samples with redundant patterns. Empirically, we show that SCIZOR enables imitation learning policies to achieve higher performance with less data, yielding an average improvement of 15.4% across multiple benchmarks. More information is available at: https://ut-austin-rpl.github.io/SCIZOR/
FLARE: Robot Learning with Implicit World Modeling
May 21, 2025We introduce $\textbf{F}$uture $\textbf{LA}$tent $\textbf{RE}$presentation Alignment ($\textbf{FLARE}$), a novel framework that integrates predictive latent world modeling into robot policy learning. By aligning features from a diffusion transformer with latent embeddings of future observations, $\textbf{FLARE}$ enables a diffusion transformer policy to anticipate latent representations of future observations, allowing it to reason about long-term consequences while generating actions. Remarkably lightweight, $\textbf{FLARE}$ requires only minimal architectural modifications -- adding a few tokens to standard vision-language-action (VLA) models -- yet delivers substantial performance gains. Across two challenging multitask simulation imitation learning benchmarks spanning single-arm and humanoid tabletop manipulation, $\textbf{FLARE}$ achieves state-of-the-art performance, outperforming prior policy learning baselines by up to 26%. Moreover, $\textbf{FLARE}$ unlocks the ability to co-train with human egocentric video demonstrations without action labels, significantly boosting policy generalization to a novel object with unseen geometry with as few as a single robot demonstration. Our results establish $\textbf{FLARE}$ as a general and scalable approach for combining implicit world modeling with high-frequency robotic control.
DreamGen: Unlocking Generalization in Robot Learning through Neural Trajectories
May 19, 2025We introduce DreamGen, a simple yet highly effective 4-stage pipeline for training robot policies that generalize across behaviors and environments through neural trajectories - synthetic robot data generated from video world models. DreamGen leverages state-of-the-art image-to-video generative models, adapting them to the target robot embodiment to produce photorealistic synthetic videos of familiar or novel tasks in diverse environments. Since these models generate only videos, we recover pseudo-action sequences using either a latent action model or an inverse-dynamics model (IDM). Despite its simplicity, DreamGen unlocks strong behavior and environment generalization: a humanoid robot can perform 22 new behaviors in both seen and unseen environments, while requiring teleoperation data from only a single pick-and-place task in one environment. To evaluate the pipeline systematically, we introduce DreamGen Bench, a video generation benchmark that shows a strong correlation between benchmark performance and downstream policy success. Our work establishes a promising new axis for scaling robot learning well beyond manual data collection.
Emergent Active Perception and Dexterity of Simulated Humanoids from Visual Reinforcement Learning
May 18, 2025Human behavior is fundamentally shaped by visual perception -- our ability to interact with the world depends on actively gathering relevant information and adapting our movements accordingly. Behaviors like searching for objects, reaching, and hand-eye coordination naturally emerge from the structure of our sensory system. Inspired by these principles, we introduce Perceptive Dexterous Control (PDC), a framework for vision-driven dexterous whole-body control with simulated humanoids. PDC operates solely on egocentric vision for task specification, enabling object search, target placement, and skill selection through visual cues, without relying on privileged state information (e.g., 3D object positions and geometries). This perception-as-interface paradigm enables learning a single policy to perform multiple household tasks, including reaching, grasping, placing, and articulated object manipulation. We also show that training from scratch with reinforcement learning can produce emergent behaviors such as active search. These results demonstrate how vision-driven control and complex tasks induce human-like behaviors and can serve as the key ingredients in closing the perception-action loop for animation, robotics, and embodied AI.
Sim-and-Real Co-Training: A Simple Recipe for Vision-Based Robotic Manipulation
Mar 31, 2025Large real-world robot datasets hold great potential to train generalist robot models, but scaling real-world human data collection is time-consuming and resource-intensive. Simulation has great potential in supplementing large-scale data, especially with recent advances in generative AI and automated data generation tools that enable scalable creation of robot behavior datasets. However, training a policy solely in simulation and transferring it to the real world often demands substantial human effort to bridge the reality gap. A compelling alternative is to co-train the policy on a mixture of simulation and real-world datasets. Preliminary studies have recently shown this strategy to substantially improve the performance of a policy over one trained on a limited amount of real-world data. Nonetheless, the community lacks a systematic understanding of sim-and-real co-training and what it takes to reap the benefits of simulation data for real-robot learning. This work presents a simple yet effective recipe for utilizing simulation data to solve vision-based robotic manipulation tasks. We derive this recipe from comprehensive experiments that validate the co-training strategy on various simulation and real-world datasets. Using two domains--a robot arm and a humanoid--across diverse tasks, we demonstrate that simulation data can enhance real-world task performance by an average of 38%, even with notable differences between the simulation and real-world data. Videos and additional results can be found at https://co-training.github.io/
Sim-to-Real Reinforcement Learning for Vision-Based Dexterous Manipulation on Humanoids
Feb 27, 2025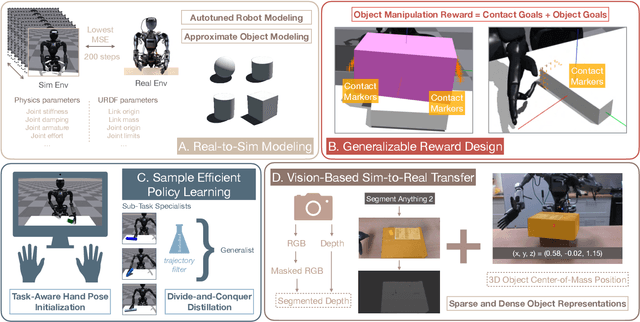

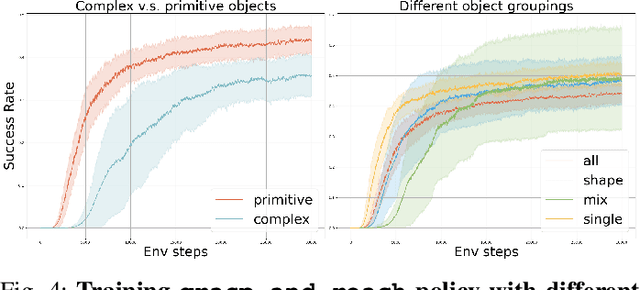
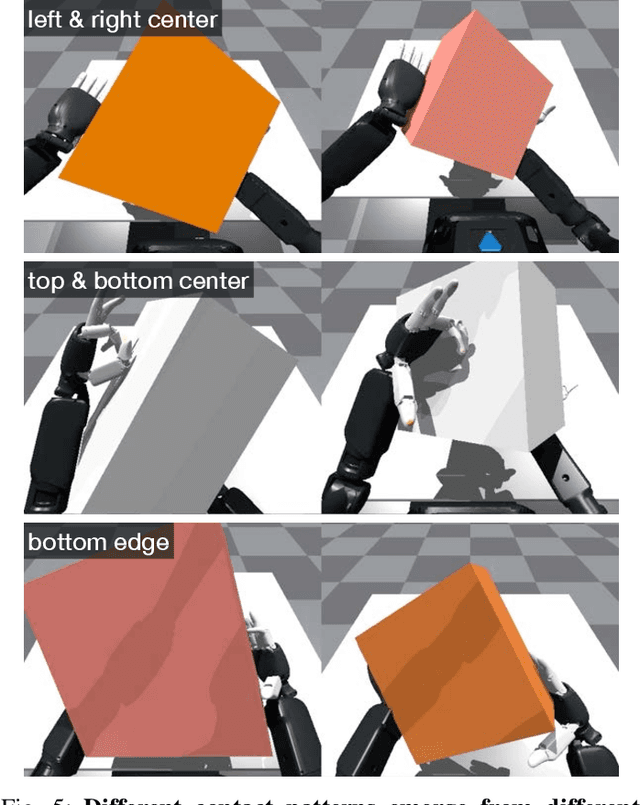
Reinforcement learning has delivered promising results in achieving human- or even superhuman-level capabilities across diverse problem domains, but success in dexterous robot manipulation remains limited. This work investigates the key challenges in applying reinforcement learning to solve a collection of contact-rich manipulation tasks on a humanoid embodiment. We introduce novel techniques to overcome the identified challenges with empirical validation. Our main contributions include an automated real-to-sim tuning module that brings the simulated environment closer to the real world, a generalized reward design scheme that simplifies reward engineering for long-horizon contact-rich manipulation tasks, a divide-and-conquer distillation process that improves the sample efficiency of hard-exploration problems while maintaining sim-to-real performance, and a mixture of sparse and dense object representations to bridge the sim-to-real perception gap. We show promising results on three humanoid dexterous manipulation tasks, with ablation studies on each technique. Our work presents a successful approach to learning humanoid dexterous manipulation using sim-to-real reinforcement learning, achieving robust generalization and high performance without the need for human demonstration.
QLIP: Text-Aligned Visual Tokenization Unifies Auto-Regressive Multimodal Understanding and Generation
Feb 07, 2025We introduce Quantized Language-Image Pretraining (QLIP), a visual tokenization method that combines state-of-the-art reconstruction quality with state-of-the-art zero-shot image understanding. QLIP trains a binary-spherical-quantization-based autoencoder with reconstruction and language-image alignment objectives. We are the first to show that the two objectives do not need to be at odds. We balance the two loss terms dynamically during training and show that a two-stage training pipeline effectively mixes the large-batch requirements of image-language pre-training with the memory bottleneck imposed by the reconstruction objective. We validate the effectiveness of QLIP for multimodal understanding and text-conditioned image generation with a single model. Specifically, QLIP serves as a drop-in replacement for the visual encoder for LLaVA and the image tokenizer for LlamaGen with comparable or even better performance. Finally, we demonstrate that QLIP enables a unified mixed-modality auto-regressive model for understanding and generation.
DexMimicGen: Automated Data Generation for Bimanual Dexterous Manipulation via Imitation Learning
Oct 31, 2024



Imitation learning from human demonstrations is an effective means to teach robots manipulation skills. But data acquisition is a major bottleneck in applying this paradigm more broadly, due to the amount of cost and human effort involved. There has been significant interest in imitation learning for bimanual dexterous robots, like humanoids. Unfortunately, data collection is even more challenging here due to the challenges of simultaneously controlling multiple arms and multi-fingered hands. Automated data generation in simulation is a compelling, scalable alternative to fuel this need for data. To this end, we introduce DexMimicGen, a large-scale automated data generation system that synthesizes trajectories from a handful of human demonstrations for humanoid robots with dexterous hands. We present a collection of simulation environments in the setting of bimanual dexterous manipulation, spanning a range of manipulation behaviors and different requirements for coordination among the two arms. We generate 21K demos across these tasks from just 60 source human demos and study the effect of several data generation and policy learning decisions on agent performance. Finally, we present a real-to-sim-to-real pipeline and deploy it on a real-world humanoid can sorting task. Videos and more are at https://dexmimicgen.github.io/