 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinlin Shen
YOLOCS: Object Detection based on Dense Channel Compression for Feature Spatial Solidification
May 07, 2023
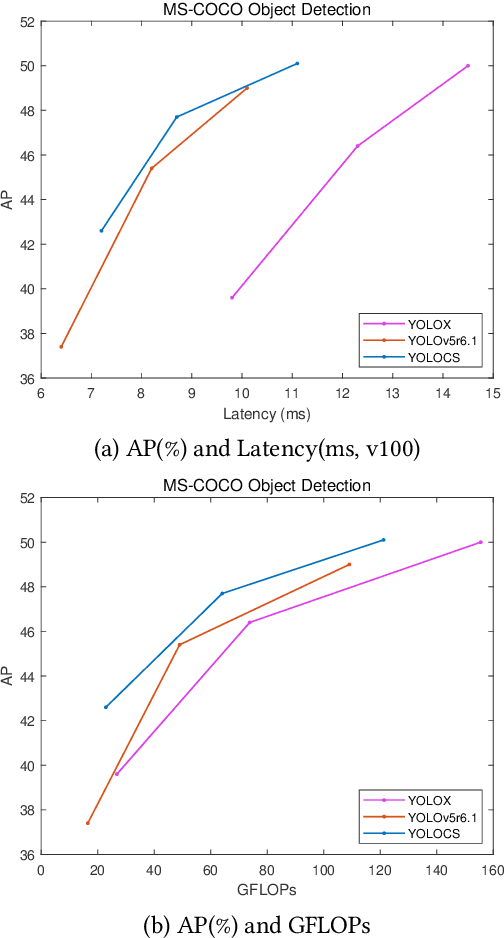
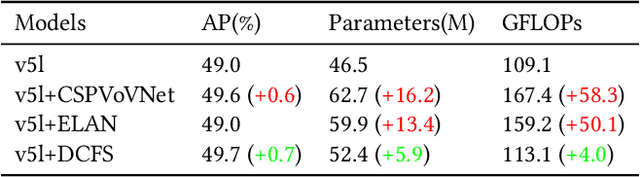
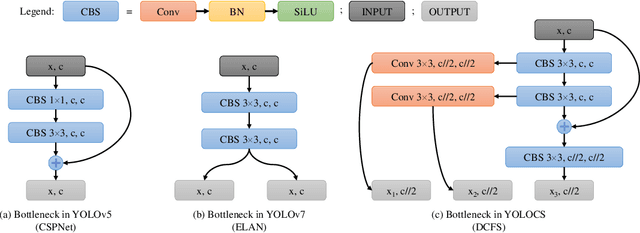
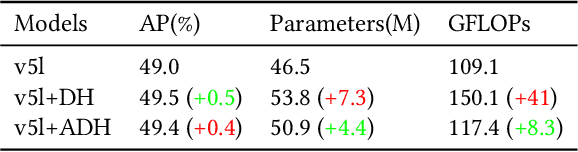
In this study, we examine the associations between channel features and convolutional kernels during the processes of feature purification and gradient backpropagation, with a focus on the forward and backward propagation within the network. Consequently, we propose a method called Dense Channel Compression for Feature Spatial Solidification. Drawing upon the central concept of this method, we introduce two innovative modules for backbone and head networks: the Dense Channel Compression for Feature Spatial Solidification Structure (DCFS) and the Asymmetric Multi-Level Compression Decoupled Head (ADH). When integrated into the YOLOv5 model, these two modules demonstrate exceptional performance, resulting in a modified model referred to as YOLOCS. Evaluated on the MSCOCO dataset, the large, medium, and small YOLOCS models yield AP of 50.1%, 47.6%, and 42.5%, respectively. Maintaining inference speeds remarkably similar to those of the YOLOv5 model, the large, medium, and small YOLOCS models surpass the YOLOv5 model's AP by 1.1%, 2.3%, and 5.2%, respectively.
Open-World Weakly-Supervised Object Localization
Apr 19, 2023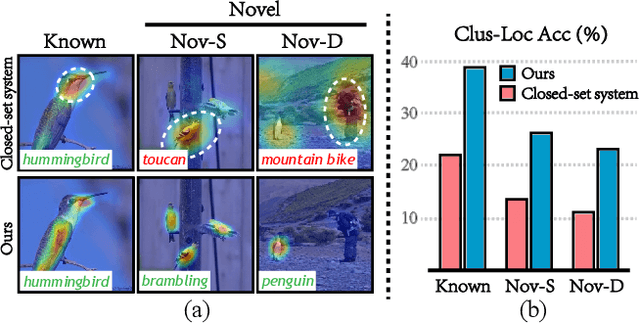
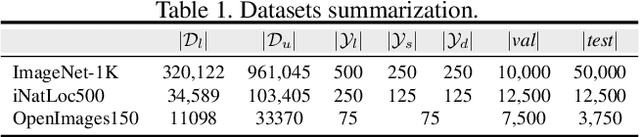
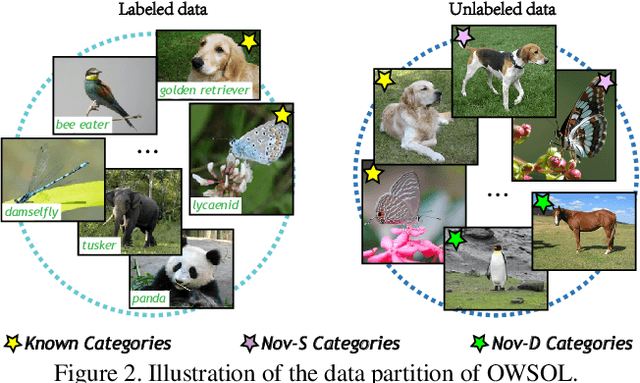
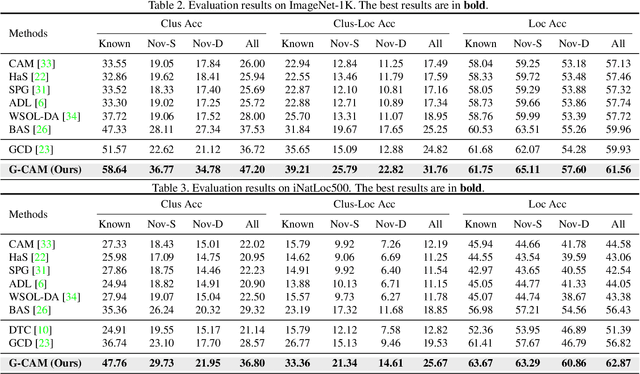
While remarkable success has been achieved in weakly-supervised object localization (WSOL), current frameworks are not capable of locating objects of novel categories in open-world settings. To address this issue, we are the first to introduce a new weakly-supervised object localization task called OWSOL (Open-World Weakly-Supervised Object Localization). During training, all labeled data comes from known categories and, both known and novel categories exist in the unlabeled data. To handle such data, we propose a novel paradigm of contrastive representation co-learning using both labeled and unlabeled data to generate a complete G-CAM (Generalized Class Activation Map) for object localization, without the requirement of bounding box annotation. As no class label is available for the unlabelled data, we conduct clustering over the full training set and design a novel multiple semantic centroids-driven contrastive loss for representation learning. We re-organize two widely used datasets, i.e., ImageNet-1K and iNatLoc500, and propose OpenImages150 to serve as evaluation benchmarks for OWSOL. Extensive experiments demonstrate that the proposed method can surpass all baselines by a large margin. We believe that this work can shift the close-set localization towards the open-world setting and serve as a foundation for subsequent works. Code will be released at https://github.com/ryylcc/OWSOL.
Spatio-Temporal AU Relational Graph Representation Learning For Facial Action Units Detection
Mar 27, 2023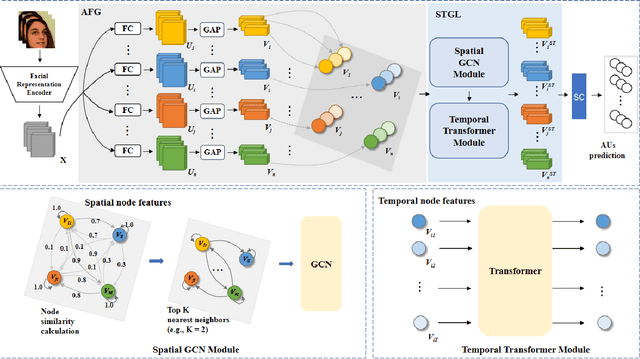

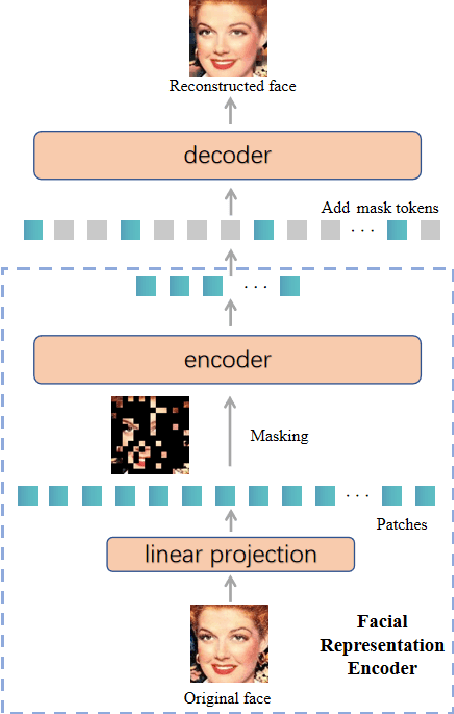

This paper presents our Facial Action Units (AUs) recognition submission to the fifth Affective Behavior Analysis in-the-wild Competition (ABAW). Our approach consists of three main modules: (i) a pre-trained facial representation encoder which produce a strong facial representation from each input face image in the input sequence; (ii) an AU-specific feature generator that specifically learns a set of AU features from each facial representation; and (iii) a spatio-temporal graph learning module that constructs a spatio-temporal graph representation. This graph representation describes AUs contained in all frames and predicts the occurrence of each AU based on both the modeled spatial information within the corresponding face and the learned temporal dynamics among frames. The experimental results show that our approach outperformed the baseline and the spatio-temporal graph representation learning allows our model to generate the best results among all ablated systems. Our model ranks at the 4th place in the AU recognition track at the 5th ABAW Competition.
Precise Facial Landmark Detection by Reference Heatmap Transformer
Mar 14, 2023
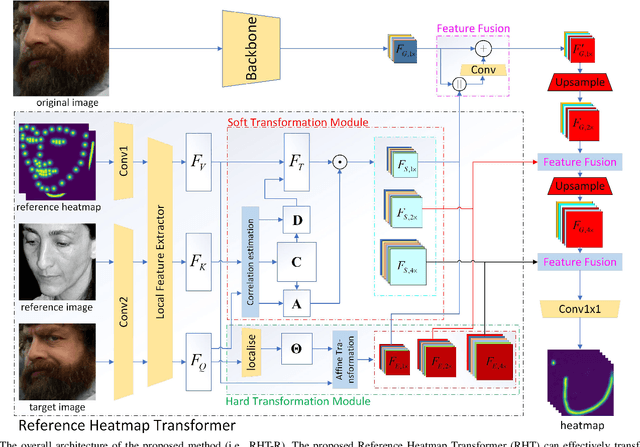
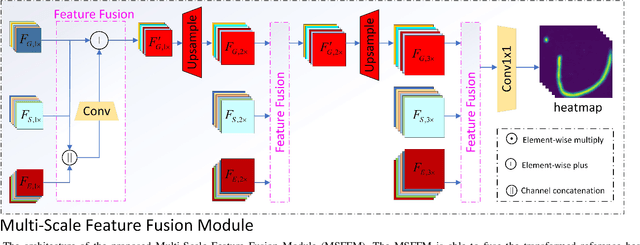

Most facial landmark detection methods predict landmarks by mapping the input facial appearance features to landmark heatmaps and have achieved promising results. However, when the face image is suffering from large poses, heavy occlusions and complicated illuminations, they cannot learn discriminative feature representations and effective facial shape constraints, nor can they accurately predict the value of each element in the landmark heatmap, limiting their detection accuracy. To address this problem, we propose a novel Reference Heatmap Transformer (RHT) by introducing reference heatmap information for more precise facial landmark detection. The proposed RHT consists of a Soft Transformation Module (STM) and a Hard Transformation Module (HTM), which can cooperate with each other to encourage the accurate transformation of the reference heatmap information and facial shape constraints. Then, a Multi-Scale Feature Fusion Module (MSFFM) is proposed to fuse the transformed heatmap features and the semantic features learned from the original face images to enhance feature representations for producing more accurate target heatmaps. To the best of our knowledge, this is the first study to explore how to enhance facial landmark detection by transforming the reference heatmap information. The experimental results from challenging benchmark datasets demonstrate that our proposed method outperforms the state-of-the-art methods in the literature.
TencentPretrain: A Scalable and Flexible Toolkit for Pre-training Models of Different Modalities
Dec 13, 2022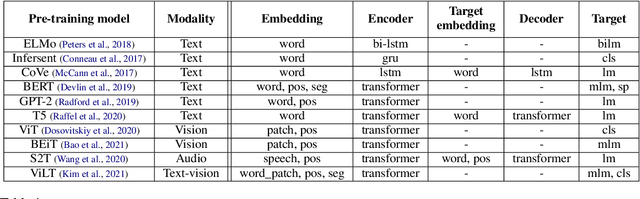
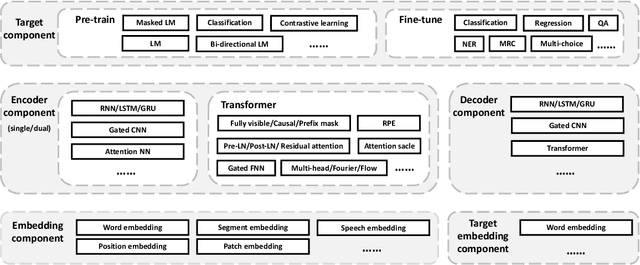

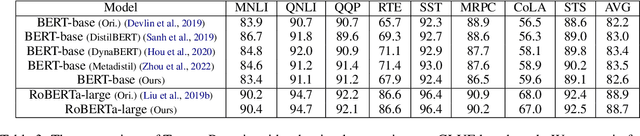
Recently, the success of pre-training in text domain has been fully extended to vision, audio, and cross-modal scenarios. The proposed pre-training models of different modalities are showing a rising trend of homogeneity in their model structures, which brings the opportunity to implement different pre-training models within a uniform framework. In this paper, we present TencentPretrain, a toolkit supporting pre-training models of different modalities. The core feature of TencentPretrain is the modular design. The toolkit uniformly divides pre-training models into 5 components: embedding, encoder, target embedding, decoder, and target. As almost all of common modules are provided in each component, users can choose the desired modules from different components to build a complete pre-training model. The modular design enables users to efficiently reproduce existing pre-training models or build brand-new one. We test the toolkit on text, vision, and audio benchmarks and show that it can match the performance of the original implementations.
Category-Level 6D Object Pose Estimation with Flexible Vector-Based Rotation Representation
Dec 09, 2022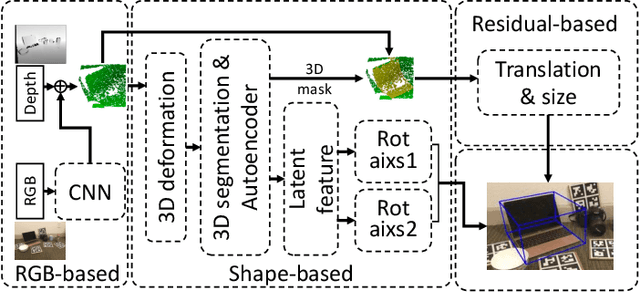
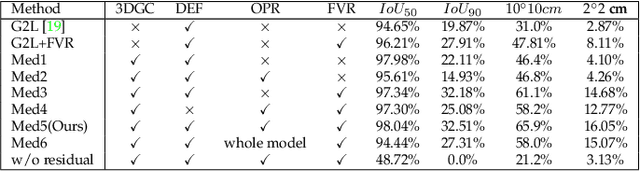
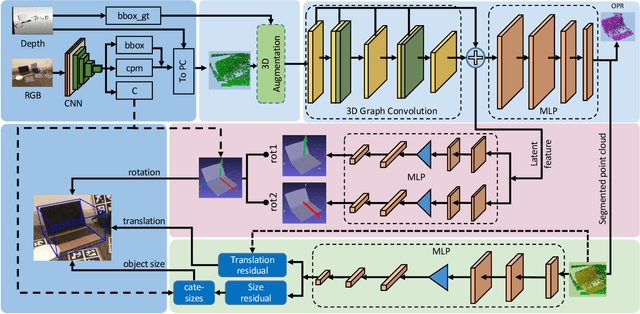
In this paper, we propose a novel 3D graph convolution based pipeline for category-level 6D pose and size estimation from monocular RGB-D images. The proposed method leverages an efficient 3D data augmentation and a novel vector-based decoupled rotation representation. Specifically, we first design an orientation-aware autoencoder with 3D graph convolution for latent feature learning. The learned latent feature is insensitive to point shift and size thanks to the shift and scale-invariance properties of the 3D graph convolution. Then, to efficiently decode the rotation information from the latent feature, we design a novel flexible vector-based decomposable rotation representation that employs two decoders to complementarily access the rotation information. The proposed rotation representation has two major advantages: 1) decoupled characteristic that makes the rotation estimation easier; 2) flexible length and rotated angle of the vectors allow us to find a more suitable vector representation for specific pose estimation task. Finally, we propose a 3D deformation mechanism to increase the generalization ability of the pipeline. Extensive experiments show that the proposed pipeline achieves state-of-the-art performance on category-level tasks. Further, the experiments demonstrate that the proposed rotation representation is more suitable for the pose estimation tasks than other rotation representations.
GRATIS: Deep Learning Graph Representation with Task-specific Topology and Multi-dimensional Edge Features
Nov 19, 2022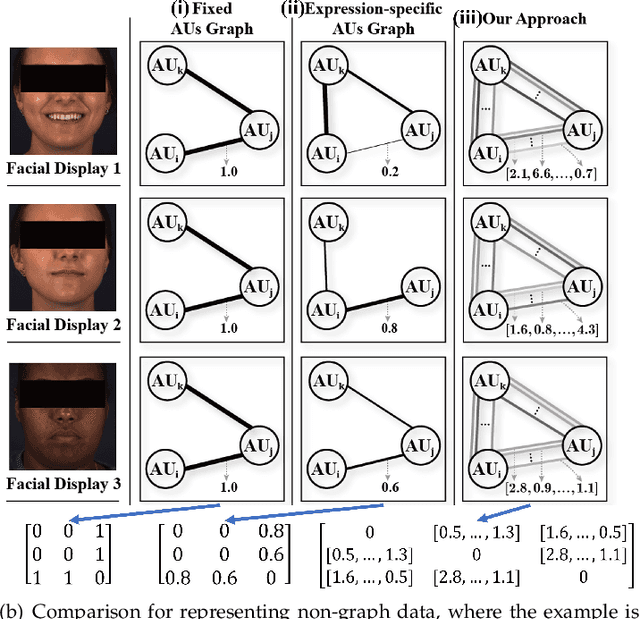
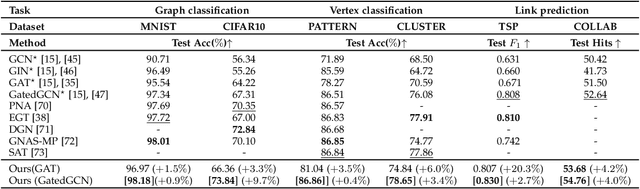
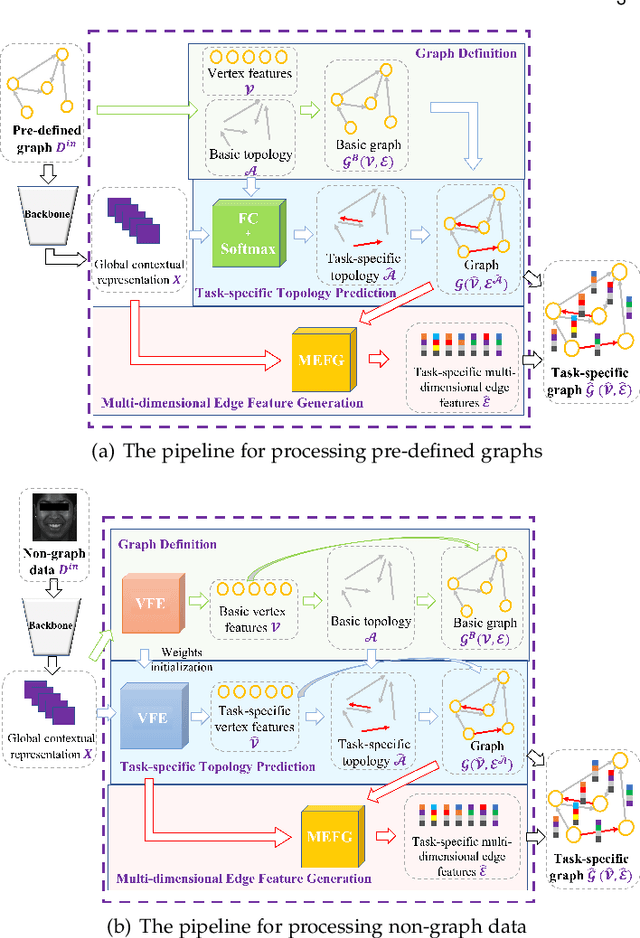
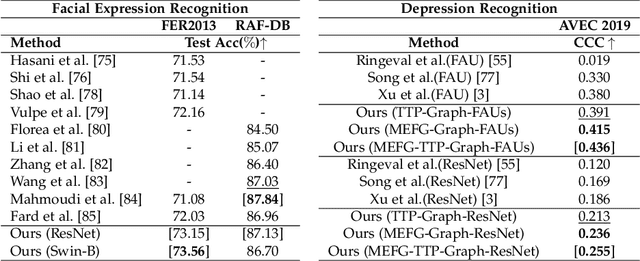
Graph is powerful for representing various types of real-world data. The topology (edges' presence) and edges' features of a graph decides the message passing mechanism among vertices within the graph. While most existing approaches only manually define a single-value edge to describe the connectivity or strength of association between a pair of vertices, task-specific and crucial relationship cues may be disregarded by such manually defined topology and single-value edge features. In this paper, we propose the first general graph representation learning framework (called GRATIS) which can generate a strong graph representation with a task-specific topology and task-specific multi-dimensional edge features from any arbitrary input. To learn each edge's presence and multi-dimensional feature, our framework takes both of the corresponding vertices pair and their global contextual information into consideration, enabling the generated graph representation to have a globally optimal message passing mechanism for different down-stream tasks. The principled investigation results achieved for various graph analysis tasks on 11 graph and non-graph datasets show that our GRATIS can not only largely enhance pre-defined graphs but also learns a strong graph representation for non-graph data, with clear performance improvements on all tasks. In particular, the learned topology and multi-dimensional edge features provide complementary task-related cues for graph analysis tasks. Our framework is effective, robust and flexible, and is a plug-and-play module that can be combined with different backbones and Graph Neural Networks (GNNs) to generate a task-specific graph representation from various graph and non-graph data. Our code is made publicly available at https://github.com/SSYSteve/Learning-Graph-Representation-with-Task-specific-Topology-and-Multi-dimensional-Edge-Features.
ImplantFormer: Vision Transformer based Implant Position Regression Using Dental CBCT Data
Oct 29, 2022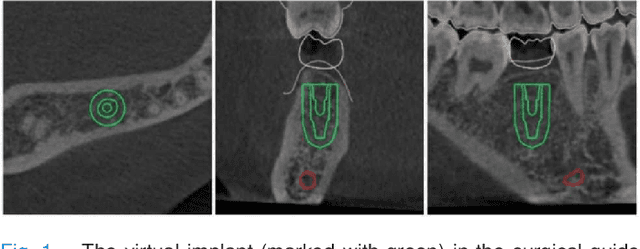
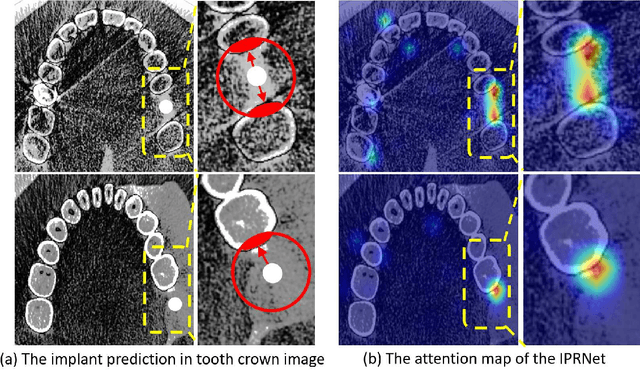
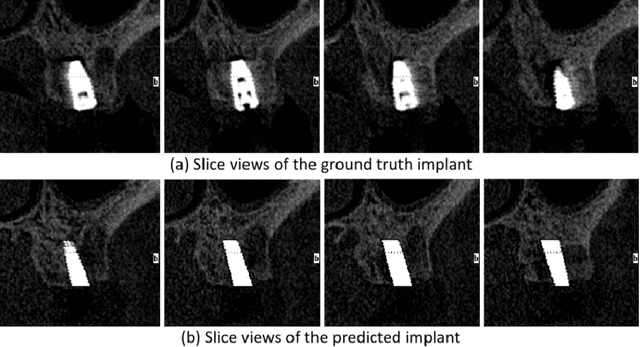
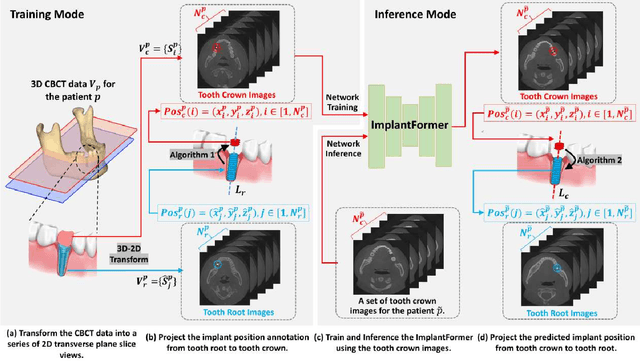
Implant prosthesis is the most optimum treatment of dentition defect or dentition loss, which usually involves a surgical guide design process to decide the position of implant. However, such design heavily relies on the subjective experiences of dentist. To relieve this problem, in this paper, a transformer based Implant Position Regression Network, ImplantFormer, is proposed to automatically predict the implant position based on the oral CBCT data. The 3D CBCT data is firstly transformed into a series of 2D transverse plane slice views. ImplantFormer is then proposed to predict the position of implant based on the 2D slices of crown images. Convolutional stem and decoder are designed to coarsely extract image feature before the operation of patch embedding and integrate multi-levels feature map for robust prediction. The predictions of our network at tooth crown area are finally projected back to the positions at tooth root. As both long-range relationship and local features are involved, our approach can better represent global information and achieves better location performance than the state-of-the-art detectors. Experimental results on a dataset of 128 patients, collected from Shenzhen University General Hospital, show that our ImplantFormer achieves superior performance than benchmarks.
SemFormer: Semantic Guided Activation Transformer for Weakly Supervised Semantic Segmentation
Oct 26, 2022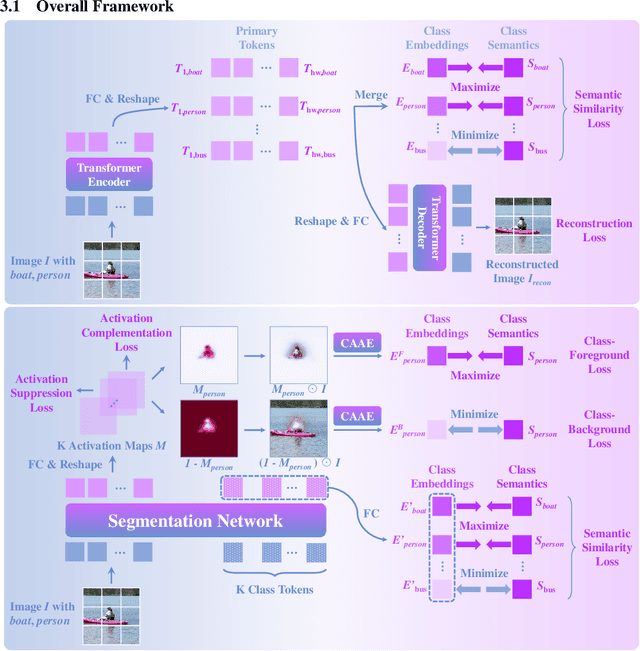



Recent mainstream weakly supervised semantic segmentation (WSSS) approaches are mainly based on Class Activation Map (CAM) generated by a CNN (Convolutional Neural Network) based image classifier. In this paper, we propose a novel transformer-based framework, named Semantic Guided Activation Transformer (SemFormer), for WSSS. We design a transformer-based Class-Aware AutoEncoder (CAAE) to extract the class embeddings for the input image and learn class semantics for all classes of the dataset. The class embeddings and learned class semantics are then used to guide the generation of activation maps with four losses, i.e., class-foreground, class-background, activation suppression, and activation complementation loss. Experimental results show that our SemFormer achieves \textbf{74.3}\% mIoU and surpasses many recent mainstream WSSS approaches by a large margin on PASCAL VOC 2012 dataset. Code will be available at \url{https://github.com/JLChen-C/SemFormer}.