 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-PCR: A Benchmark for Cross-modality Progressive Clinical Reasoning in Ophthalmic Diagnosis
Apr 22, 2026Despite significant progress in Multi-modal Large Language Models (MLLMs), their clinical reasoning capacity for multi-modal diagnosis remains largely unexamined. Current benchmarks, mostly single-modality data, can't evaluate progressive reasoning and cross-modal integration essential for clinical practice. We introduce the Cross-Modality Progressive Clinical Reasoning (X-PCR) benchmark, the first comprehensive evaluation of MLLMs through a complete ophthalmology diagnostic workflow, with two reasoning tasks: 1) a six-stage progressive reasoning chain spanning image quality assessment to clinical decision-making, and 2) a cross-modality reasoning task integrating six imaging modalities. The benchmark comprises 26,415 images and 177,868 expert-verified VQA pairs curated from 51 public datasets, covering 52 ophthalmic diseases. Evaluation of 21 MLLMs reveals critical gaps in progressive reasoning and cross-modal integration. Dataset and code: https://github.com/CVI-SZU/X-PCR.
KoCo: Conditioning Language Model Pre-training on Knowledge Coordinates
Apr 14, 2026Standard Large Language Model (LLM) pre-training typically treats corpora as flattened token sequences, often overlooking the real-world context that humans naturally rely on to contextualize information. To bridge this gap, we introduce Knowledge Coordinate Conditioning (KoCo), a simple method that maps every document into a three-dimensional semantic coordinate. By prepending these coordinates as textual prefixes for pre-training, we aim to equip the model with explicit contextual awareness to learn the documents within the real-world knowledge structure. Experiment results demonstrate that KoCo significantly enhances performance across 10 downstream tasks and accelerates pre-training convergence by approximately 30\%. Furthermore, our analysis indicates that explicitly modeling knowledge coordinates helps the model distinguish stable facts from noise, effectively mitigating hallucination in generated outputs.
HiGR: Efficient Generative Slate Recommendation via Hierarchical Planning and Multi-Objective Preference Alignment
Dec 31, 2025Slate recommendation, where users are presented with a ranked list of items simultaneously, is widely adopted in online platforms. Recent advances in generative models have shown promise in slate recommendation by modeling sequences of discrete semantic IDs autoregressively. However, existing autoregressive approaches suffer from semantically entangled item tokenization and inefficient sequential decoding that lacks holistic slate planning. To address these limitations, we propose HiGR, an efficient generative slate recommendation framework that integrates hierarchical planning with listwise preference alignment. First, we propose an auto-encoder utilizing residual quantization and contrastive constraints to tokenize items into semantically structured IDs for controllable generation. Second, HiGR decouples generation into a list-level planning stage for global slate intent, followed by an item-level decoding stage for specific item selection. Third, we introduce a listwise preference alignment objective to directly optimize slate quality using implicit user feedback. Experiments on our large-scale commercial media platform demonstrate that HiGR delivers consistent improvements in both offline evaluations and online deployment. Specifically, it outperforms state-of-the-art methods by over 10% in offline recommendation quality with a 5x inference speedup, while further achieving a 1.22% and 1.73% increase in Average Watch Time and Average Video Views in online A/B tests.
RedNote-Vibe: A Dataset for Capturing Temporal Dynamics of AI-Generated Text in Social Media
Sep 26, 2025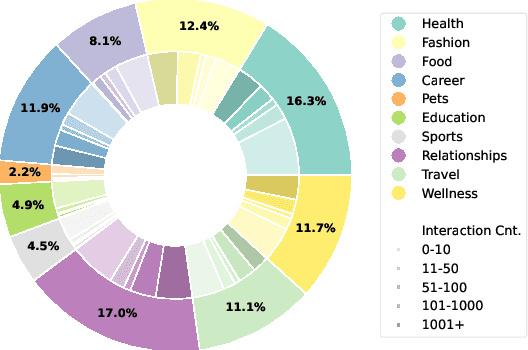
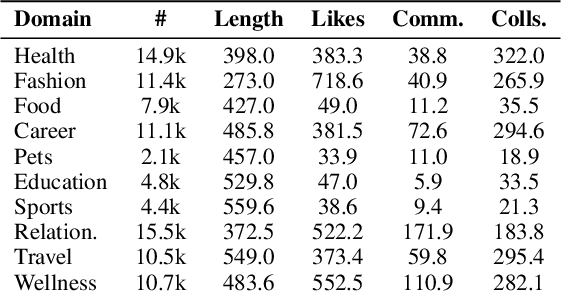

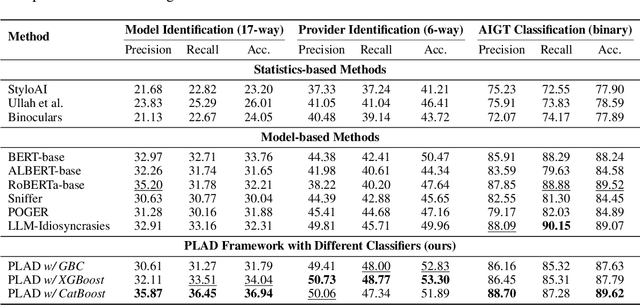
The proliferation of Large Language Models (LLMs) has led to widespread AI-Generated Text (AIGT) on social media platforms, creating unique challenges where content dynamics are driven by user engagement and evolve over time. However, existing datasets mainly depict static AIGT detection. In this work, we introduce RedNote-Vibe, the first longitudinal (5-years) dataset for social media AIGT analysis. This dataset is sourced from Xiaohongshu platform, containing user engagement metrics (e.g., likes, comments) and timestamps spanning from the pre-LLM period to July 2025, which enables research into the temporal dynamics and user interaction patterns of AIGT. Furthermore, to detect AIGT in the context of social media, we propose PsychoLinguistic AIGT Detection Framework (PLAD), an interpretable approach that leverages psycholinguistic features. Our experiments show that PLAD achieves superior detection performance and provides insights into the signatures distinguishing human and AI-generated content. More importantly, it reveals the complex relationship between these linguistic features and social media engagement. The dataset is available at https://github.com/testuser03158/RedNote-Vibe.
FaceBench: A Multi-View Multi-Level Facial Attribute VQA Dataset for Benchmarking Face Perception MLLMs
Mar 27, 2025



Multimodal large language models (MLLMs) have demonstrated remarkable capabilities in various tasks. However, effectively evaluating these MLLMs on face perception remains largely unexplored. To address this gap, we introduce FaceBench, a dataset featuring hierarchical multi-view and multi-level attributes specifically designed to assess the comprehensive face perception abilities of MLLMs. Initially, we construct a hierarchical facial attribute structure, which encompasses five views with up to three levels of attributes, totaling over 210 attributes and 700 attribute values. Based on the structure, the proposed FaceBench consists of 49,919 visual question-answering (VQA) pairs for evaluation and 23,841 pairs for fine-tuning. Moreover, we further develop a robust face perception MLLM baseline, Face-LLaVA, by training with our proposed face VQA data. Extensive experiments on various mainstream MLLMs and Face-LLaVA are conducted to test their face perception ability, with results also compared against human performance. The results reveal that, the existing MLLMs are far from satisfactory in understanding the fine-grained facial attributes, while our Face-LLaVA significantly outperforms existing open-source models with a small amount of training data and is comparable to commercial ones like GPT-4o and Gemini. The dataset will be released at https://github.com/CVI-SZU/FaceBench.
GTG: Generalizable Trajectory Generation Model for Urban Mobility
Feb 03, 2025



Trajectory data mining is crucial for smart city management. However, collecting large-scale trajectory datasets is challenging due to factors such as commercial conflicts and privacy regulations. Therefore, we urgently need trajectory generation techniques to address this issue. Existing trajectory generation methods rely on the global road network structure of cities. When the road network structure changes, these methods are often not transferable to other cities. In fact, there exist invariant mobility patterns between different cities: 1) People prefer paths with the minimal travel cost; 2) The travel cost of roads has an invariant relationship with the topological features of the road network. Based on the above insight, this paper proposes a Generalizable Trajectory Generation model (GTG). The model consists of three parts: 1) Extracting city-invariant road representation based on Space Syntax method; 2) Cross-city travel cost prediction through disentangled adversarial training; 3) Travel preference learning by shortest path search and preference update. By learning invariant movement patterns, the model is capable of generating trajectories in new cities. Experiments on three datasets demonstrates that our model significantly outperforms existing models in terms of generalization ability.
Dynamic data sampler for cross-language transfer learning in large language models
May 17, 2024Large Language Models (LLMs) have gained significant attention in the field of natural language processing (NLP) due to their wide range of applications. However, training LLMs for languages other than English poses significant challenges, due to the difficulty in acquiring large-scale corpus and the requisite computing resources. In this paper, we propose ChatFlow, a cross-language transfer-based LLM, to address these challenges and train large Chinese language models in a cost-effective manner. We employ a mix of Chinese, English, and parallel corpus to continuously train the LLaMA2 model, aiming to align cross-language representations and facilitate the knowledge transfer specifically to the Chinese language model. In addition, we use a dynamic data sampler to progressively transition the model from unsupervised pre-training to supervised fine-tuning. Experimental results demonstrate that our approach accelerates model convergence and achieves superior performance. We evaluate ChatFlow on popular Chinese and English benchmarks, the results indicate that it outperforms other Chinese models post-trained on LLaMA-2-7B.
Rethinking Residual Connection in Training Large-Scale Spiking Neural Networks
Nov 09, 2023



Spiking Neural Network (SNN) is known as the most famous brain-inspired model, but the non-differentiable spiking mechanism makes it hard to train large-scale SNNs. To facilitate the training of large-scale SNNs, many training methods are borrowed from Artificial Neural Networks (ANNs), among which deep residual learning is the most commonly used. But the unique features of SNNs make prior intuition built upon ANNs not available for SNNs. Although there are a few studies that have made some pioneer attempts on the topology of Spiking ResNet, the advantages of different connections remain unclear. To tackle this issue, we analyze the merits and limitations of various residual connections and empirically demonstrate our ideas with extensive experiments. Then, based on our observations, we abstract the best-performing connections into densely additive (DA) connection, extend such a concept to other topologies, and propose four architectures for training large-scale SNNs, termed DANet, which brings up to 13.24% accuracy gain on ImageNet. Besides, in order to present a detailed methodology for designing the topology of large-scale SNNs, we further conduct in-depth discussions on their applicable scenarios in terms of their performance on various scales of datasets and demonstrate their advantages over prior architectures. At a low training expense, our best-performing ResNet-50/101/152 obtain 73.71%/76.13%/77.22% top-1 accuracy on ImageNet with 4 time steps. We believe that this work shall give more insights for future works to design the topology of their networks and promote the development of large-scale SNNs. The code will be publicly available.
VisorGPT: Learning Visual Prior via Generative Pre-Training
May 24, 2023Various stuff and things in visual data possess specific traits, which can be learned by deep neural networks and are implicitly represented as the visual prior, \emph{e.g.,} object location and shape, in the model. Such prior potentially impacts many vision tasks. For example, in conditional image synthesis, spatial conditions failing to adhere to the prior can result in visually inaccurate synthetic results. This work aims to explicitly learn the visual prior and enable the customization of sampling. Inspired by advances in language modeling, we propose to learn Visual prior via Generative Pre-Training, dubbed VisorGPT. By discretizing visual locations of objects, \emph{e.g.,} bounding boxes, human pose, and instance masks, into sequences, \our~can model visual prior through likelihood maximization. Besides, prompt engineering is investigated to unify various visual locations and enable customized sampling of sequential outputs from the learned prior. Experimental results demonstrate that \our~can effectively model the visual prior, which can be employed for many vision tasks, such as customizing accurate human pose for conditional image synthesis models like ControlNet. Code will be released at https://github.com/Sierkinhane/VisorGPT.
TencentPretrain: A Scalable and Flexible Toolkit for Pre-training Models of Different Modalities
Dec 13, 2022



Recently, the success of pre-training in text domain has been fully extended to vision, audio, and cross-modal scenarios. The proposed pre-training models of different modalities are showing a rising trend of homogeneity in their model structures, which brings the opportunity to implement different pre-training models within a uniform framework. In this paper, we present TencentPretrain, a toolkit supporting pre-training models of different modalities. The core feature of TencentPretrain is the modular design. The toolkit uniformly divides pre-training models into 5 components: embedding, encoder, target embedding, decoder, and target. As almost all of common modules are provided in each component, users can choose the desired modules from different components to build a complete pre-training model. The modular design enables users to efficiently reproduce existing pre-training models or build brand-new one. We test the toolkit on text, vision, and audio benchmarks and show that it can match the performance of the original implementations.