 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRay-Aware Pointer Memory with Adaptive Updates for Streaming 3D Reconstruction
May 07, 2026Dense 3D reconstruction from continuous image streams requires both accurate geometric aggregation and stable long-term memory management. Recent feed-forward reconstruction frameworks integrate observations through persistent memory representations, yet most rely primarily on appearance-based similarity when updating memory. Such appearance-driven integration often leads to redundant accumulation of observations and unstable geometry when viewpoint changes occur. In this work, we propose a ray-aware pointer memory for streaming 3D reconstruction that explicitly models both spatial location and viewing direction within a unified memory representation. Each memory pointer stores its 3D position, associated ray direction, and feature embedding, allowing the system to reason jointly about geometric proximity and viewpoint consistency. Based on this representation, we introduce an adaptive pointer update strategy that replaces traditional fusion-based memory compression with a retain-or-replace mechanism. Instead of averaging nearby observations, the system selectively retains informative pointers while discarding redundant ones, preserving distinctive geometric structures while maintaining bounded memory growth. Furthermore, the joint reasoning over spatial distance and ray-direction discrepancy enables the system to distinguish between local redundancy, novel observations, and potential loop revisits in a unified manner. When loop candidates are detected, pose refinement is triggered to enforce global geometric consistency across the reconstruction. Extensive experiments demonstrate that the proposed ray-aware memory design significantly improves long-term reconstruction stability and camera pose accuracy while maintaining efficient streaming inference. Our approach provides a principled framework for scalable and drift-resistant online 3D reconstruction from image streams.
SafeRoPE: Risk-specific Head-wise Embedding Rotation for Safe Generation in Rectified Flow Transformers
Apr 02, 2026Recent Text-to-Image (T2I) models based on rectified-flow transformers (e.g., SD3, FLUX) achieve high generative fidelity but remain vulnerable to unsafe semantics, especially when triggered by multi-token interactions. Existing mitigation methods largely rely on fine-tuning or attention modulation for concept unlearning; however, their expensive computational overhead and design tailored to U-Net-based denoisers hinder direct adaptation to transformer-based diffusion models (e.g., MMDiT). In this paper, we conduct an in-depth analysis of the attention mechanism in MMDiT and find that unsafe semantics concentrate within interpretable, low-dimensional subspaces at head level, where a finite set of safety-critical heads is responsible for unsafe feature extraction. We further observe that perturbing the Rotary Positional Embedding (RoPE) applied to the query and key vectors can effectively modify some specific concepts in the generated images. Motivated by these insights, we propose SafeRoPE, a lightweight and fine-grained safe generation framework for MMDiT. Specifically, SafeRoPE first constructs head-wise unsafe subspaces by decomposing unsafe embeddings within safety-critical heads, and computes a Latent Risk Score (LRS) for each input vector via projection onto these subspaces. We then introduce head-wise RoPE perturbations that can suppress unsafe semantics without degrading benign content or image quality. SafeRoPE combines both head-wise LRS and RoPE perturbations to perform risk-specific head-wise rotation on query and key vector embeddings, enabling precise suppression of unsafe outputs while maintaining generation fidelity. Extensive experiments demonstrate that SafeRoPE achieves SOTA performance in balancing effective harmful content mitigation and utility preservation for safe generation of MMDiT. Codes are available at https://github.com/deng12yx/SafeRoPE.
VERTIGO: Visual Preference Optimization for Cinematic Camera Trajectory Generation
Apr 02, 2026Cinematic camera control relies on a tight feedback loop between director and cinematographer, where camera motion and framing are continuously reviewed and refined. Recent generative camera systems can produce diverse, text-conditioned trajectories, but they lack this "director in the loop" and have no explicit supervision of whether a shot is visually desirable. This results in in-distribution camera motion but poor framing, off-screen characters, and undesirable visual aesthetics. In this paper, we introduce VERTIGO, the first framework for visual preference optimization of camera trajectory generators. Our framework leverages a real-time graphics engine (Unity) to render 2D visual previews from generated camera motion. A cinematically fine-tuned vision-language model then scores these previews using our proposed cyclic semantic similarity mechanism, which aligns renders with text prompts. This process provides the visual preference signals for Direct Preference Optimization (DPO) post-training. Both quantitative evaluations and user studies on Unity renders and diffusion-based Camera-to-Video pipelines show consistent gains in condition adherence, framing quality, and perceptual realism. Notably, VERTIGO reduces the character off-screen rate from 38% to nearly 0% while preserving the geometric fidelity of camera motion. User study participants further prefer VERTIGO over baselines across composition, consistency, prompt adherence, and aesthetic quality, confirming the perceptual benefits of our visual preference post-training.
SmartSight: Mitigating Hallucination in Video-LLMs Without Compromising Video Understanding via Temporal Attention Collapse
Dec 21, 2025Despite Video Large Language Models having rapidly advanced in recent years, perceptual hallucinations pose a substantial safety risk, which severely restricts their real-world applicability. While several methods for hallucination mitigation have been proposed, they often compromise the model's capacity for video understanding and reasoning. In this work, we propose SmartSight, a pioneering step to address this issue in a training-free manner by leveraging the model's own introspective capabilities. Specifically, SmartSight generates multiple candidate responses to uncover low-hallucinated outputs that are often obscured by standard greedy decoding. It assesses the hallucination of each response using the Temporal Attention Collapse score, which measures whether the model over-focuses on trivial temporal regions of the input video when generating the response. To improve efficiency, SmartSight identifies the Visual Attention Vanishing point, enabling more accurate hallucination estimation and early termination of hallucinated responses, leading to a substantial reduction in decoding cost. Experiments show that SmartSight substantially lowers hallucinations for Qwen2.5-VL-7B by 10.59% on VRIPT-HAL, while simultaneously enhancing video understanding and reasoning, boosting performance on VideoMMMU by up to 8.86%. These results highlight SmartSight's effectiveness in improving the reliability of open-source Video-LLMs.
InfoCons: Identifying Interpretable Critical Concepts in Point Clouds via Information Theory
May 26, 2025Interpretability of point cloud (PC) models becomes imperative given their deployment in safety-critical scenarios such as autonomous vehicles. We focus on attributing PC model outputs to interpretable critical concepts, defined as meaningful subsets of the input point cloud. To enable human-understandable diagnostics of model failures, an ideal critical subset should be *faithful* (preserving points that causally influence predictions) and *conceptually coherent* (forming semantically meaningful structures that align with human perception). We propose InfoCons, an explanation framework that applies information-theoretic principles to decompose the point cloud into 3D concepts, enabling the examination of their causal effect on model predictions with learnable priors. We evaluate InfoCons on synthetic datasets for classification, comparing it qualitatively and quantitatively with four baselines. We further demonstrate its scalability and flexibility on two real-world datasets and in two applications that utilize critical scores of PC.
Detect-and-Guide: Self-regulation of Diffusion Models for Safe Text-to-Image Generation via Guideline Token Optimization
Mar 19, 2025

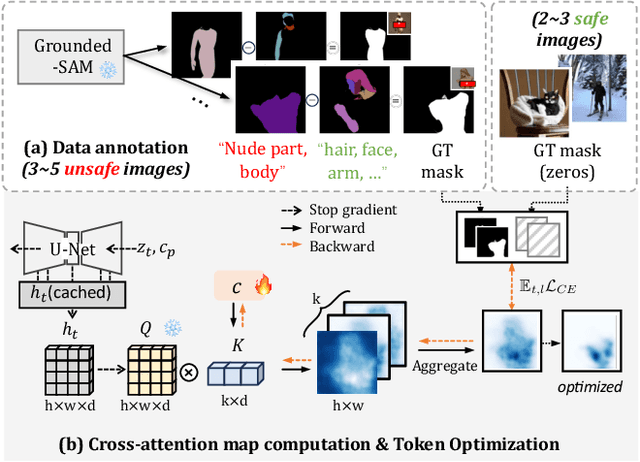
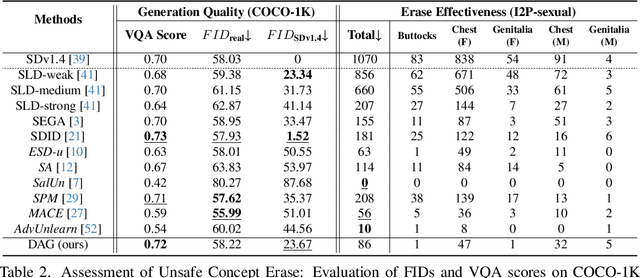
Text-to-image diffusion models have achieved state-of-the-art results in synthesis tasks; however, there is a growing concern about their potential misuse in creating harmful content. To mitigate these risks, post-hoc model intervention techniques, such as concept unlearning and safety guidance, have been developed. However, fine-tuning model weights or adapting the hidden states of the diffusion model operates in an uninterpretable way, making it unclear which part of the intermediate variables is responsible for unsafe generation. These interventions severely affect the sampling trajectory when erasing harmful concepts from complex, multi-concept prompts, thus hindering their practical use in real-world settings. In this work, we propose the safe generation framework Detect-and-Guide (DAG), leveraging the internal knowledge of diffusion models to perform self-diagnosis and fine-grained self-regulation during the sampling process. DAG first detects harmful concepts from noisy latents using refined cross-attention maps of optimized tokens, then applies safety guidance with adaptive strength and editing regions to negate unsafe generation. The optimization only requires a small annotated dataset and can provide precise detection maps with generalizability and concept specificity. Moreover, DAG does not require fine-tuning of diffusion models, and therefore introduces no loss to their generation diversity. Experiments on erasing sexual content show that DAG achieves state-of-the-art safe generation performance, balancing harmfulness mitigation and text-following performance on multi-concept real-world prompts.
PoI: Pixel of Interest for Novel View Synthesis Assisted Scene Coordinate Regression
Feb 07, 2025The task of estimating camera poses can be enhanced through novel view synthesis techniques such as NeRF and Gaussian Splatting to increase the diversity and extension of training data. However, these techniques often produce rendered images with issues like blurring and ghosting, which compromise their reliability. These issues become particularly pronounced for Scene Coordinate Regression (SCR) methods, which estimate 3D coordinates at the pixel level. To mitigate the problems associated with unreliable rendered images, we introduce a novel filtering approach, which selectively extracts well-rendered pixels while discarding the inferior ones. This filter simultaneously measures the SCR model's real-time reprojection loss and gradient during training. Building on this filtering technique, we also develop a new strategy to improve scene coordinate regression using sparse inputs, drawing on successful applications of sparse input techniques in novel view synthesis. Our experimental results validate the effectiveness of our method, demonstrating state-of-the-art performance on indoor and outdoor datasets.
Efficient MedSAMs: Segment Anything in Medical Images on Laptop
Dec 20, 2024


Promptable segmentation foundation models have emerged as a transformative approach to addressing the diverse needs in medical images, but most existing models require expensive computing, posing a big barrier to their adoption in clinical practice. In this work, we organized the first international competition dedicated to promptable medical image segmentation, featuring a large-scale dataset spanning nine common imaging modalities from over 20 different institutions. The top teams developed lightweight segmentation foundation models and implemented an efficient inference pipeline that substantially reduced computational requirements while maintaining state-of-the-art segmentation accuracy. Moreover, the post-challenge phase advanced the algorithms through the design of performance booster and reproducibility tasks, resulting in improved algorithms and validated reproducibility of the winning solution. Furthermore, the best-performing algorithms have been incorporated into the open-source software with a user-friendly interface to facilitate clinical adoption. The data and code are publicly available to foster the further development of medical image segmentation foundation models and pave the way for impactful real-world applications.
A Reinforcement Learning-Based Automatic Video Editing Method Using Pre-trained Vision-Language Model
Nov 07, 2024



In this era of videos, automatic video editing techniques attract more and more attention from industry and academia since they can reduce workloads and lower the requirements for human editors. Existing automatic editing systems are mainly scene- or event-specific, e.g., soccer game broadcasting, yet the automatic systems for general editing, e.g., movie or vlog editing which covers various scenes and events, were rarely studied before, and converting the event-driven editing method to a general scene is nontrivial. In this paper, we propose a two-stage scheme for general editing. Firstly, unlike previous works that extract scene-specific features, we leverage the pre-trained Vision-Language Model (VLM) to extract the editing-relevant representations as editing context. Moreover, to close the gap between the professional-looking videos and the automatic productions generated with simple guidelines, we propose a Reinforcement Learning (RL)-based editing framework to formulate the editing problem and train the virtual editor to make better sequential editing decisions. Finally, we evaluate the proposed method on a more general editing task with a real movie dataset. Experimental results demonstrate the effectiveness and benefits of the proposed context representation and the learning ability of our RL-based editing framework.
CORAG: A Cost-Constrained Retrieval Optimization System for Retrieval-Augmented Generation
Nov 01, 2024



Large Language Models (LLMs) have demonstrated remarkable generation capabilities but often struggle to access up-to-date information, which can lead to hallucinations. Retrieval-Augmented Generation (RAG) addresses this issue by incorporating knowledge from external databases, enabling more accurate and relevant responses. Due to the context window constraints of LLMs, it is impractical to input the entire external database context directly into the model. Instead, only the most relevant information, referred to as chunks, is selectively retrieved. However, current RAG research faces three key challenges. First, existing solutions often select each chunk independently, overlooking potential correlations among them. Second, in practice the utility of chunks is non-monotonic, meaning that adding more chunks can decrease overall utility. Traditional methods emphasize maximizing the number of included chunks, which can inadvertently compromise performance. Third, each type of user query possesses unique characteristics that require tailored handling, an aspect that current approaches do not fully consider. To overcome these challenges, we propose a cost constrained retrieval optimization system CORAG for retrieval-augmented generation. We employ a Monte Carlo Tree Search (MCTS) based policy framework to find optimal chunk combinations sequentially, allowing for a comprehensive consideration of correlations among chunks. Additionally, rather than viewing budget exhaustion as a termination condition, we integrate budget constraints into the optimization of chunk combinations, effectively addressing the non-monotonicity of chunk utility.