 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Towards Automated Model Design on Recommender Systems
Nov 12, 2024The increasing popularity of deep learning models has created new opportunities for developing AI-based recommender systems. Designing recommender systems using deep neural networks requires careful architecture design, and further optimization demands extensive co-design efforts on jointly optimizing model architecture and hardware. Design automation, such as Automated Machine Learning (AutoML), is necessary to fully exploit the potential of recommender model design, including model choices and model-hardware co-design strategies. We introduce a novel paradigm that utilizes weight sharing to explore abundant solution spaces. Our paradigm creates a large supernet to search for optimal architectures and co-design strategies to address the challenges of data multi-modality and heterogeneity in the recommendation domain. From a model perspective, the supernet includes a variety of operators, dense connectivity, and dimension search options. From a co-design perspective, it encompasses versatile Processing-In-Memory (PIM) configurations to produce hardware-efficient models. Our solution space's scale, heterogeneity, and complexity pose several challenges, which we address by proposing various techniques for training and evaluating the supernet. Our crafted models show promising results on three Click-Through Rates (CTR) prediction benchmarks, outperforming both manually designed and AutoML-crafted models with state-of-the-art performance when focusing solely on architecture search. From a co-design perspective, we achieve 2x FLOPs efficiency, 1.8x energy efficiency, and 1.5x performance improvements in recommender models.
* Accepted in ACM Transactions on Recommender Systems. arXiv admin note: substantial text overlap with arXiv:2207.07187
Hierarchical Structured Neural Network for Retrieval
Aug 13, 2024



Embedding Based Retrieval (EBR) is a crucial component of the retrieval stage in (Ads) Recommendation System that utilizes Two Tower or Siamese Networks to learn embeddings for both users and items (ads). It then employs an Approximate Nearest Neighbor Search (ANN) to efficiently retrieve the most relevant ads for a specific user. Despite the recent rise to popularity in the industry, they have a couple of limitations. Firstly, Two Tower model architecture uses a single dot product interaction which despite their efficiency fail to capture the data distribution in practice. Secondly, the centroid representation and cluster assignment, which are components of ANN, occur after the training process has been completed. As a result, they do not take into account the optimization criteria used for retrieval model. In this paper, we present Hierarchical Structured Neural Network (HSNN), a deployed jointly optimized hierarchical clustering and neural network model that can take advantage of sophisticated interactions and model architectures that are more common in the ranking stages while maintaining a sub-linear inference cost. We achieve 6.5% improvement in offline evaluation and also demonstrate 1.22% online gains through A/B experiments. HSNN has been successfully deployed into the Ads Recommendation system and is currently handling major portion of the traffic. The paper shares our experience in developing this system, dealing with challenges like freshness, volatility, cold start recommendations, cluster collapse and lessons deploying the model in a large scale retrieval production system.
Rankitect: Ranking Architecture Search Battling World-class Engineers at Meta Scale
Nov 14, 2023



Neural Architecture Search (NAS) has demonstrated its efficacy in computer vision and potential for ranking systems. However, prior work focused on academic problems, which are evaluated at small scale under well-controlled fixed baselines. In industry system, such as ranking system in Meta, it is unclear whether NAS algorithms from the literature can outperform production baselines because of: (1) scale - Meta ranking systems serve billions of users, (2) strong baselines - the baselines are production models optimized by hundreds to thousands of world-class engineers for years since the rise of deep learning, (3) dynamic baselines - engineers may have established new and stronger baselines during NAS search, and (4) efficiency - the search pipeline must yield results quickly in alignment with the productionization life cycle. In this paper, we present Rankitect, a NAS software framework for ranking systems at Meta. Rankitect seeks to build brand new architectures by composing low level building blocks from scratch. Rankitect implements and improves state-of-the-art (SOTA) NAS methods for comprehensive and fair comparison under the same search space, including sampling-based NAS, one-shot NAS, and Differentiable NAS (DNAS). We evaluate Rankitect by comparing to multiple production ranking models at Meta. We find that Rankitect can discover new models from scratch achieving competitive tradeoff between Normalized Entropy loss and FLOPs. When utilizing search space designed by engineers, Rankitect can generate better models than engineers, achieving positive offline evaluation and online A/B test at Meta scale.
NASRec: Weight Sharing Neural Architecture Search for Recommender Systems
Jul 14, 2022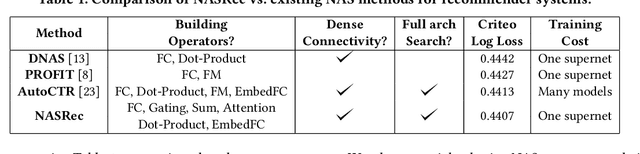
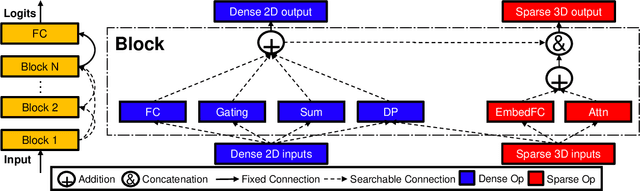
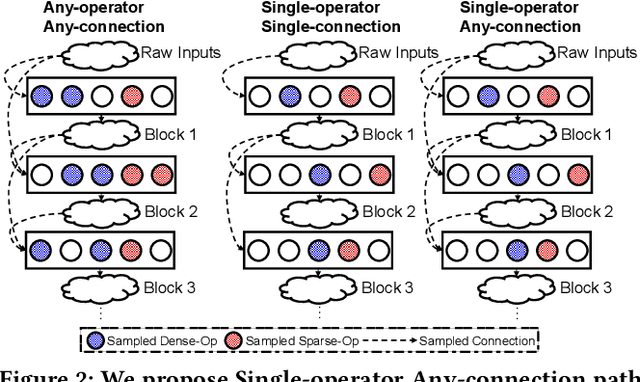

The rise of deep neural networks provides an important driver in optimizing recommender systems. However, the success of recommender systems lies in delicate architecture fabrication, and thus calls for Neural Architecture Search (NAS) to further improve its modeling. We propose NASRec, a paradigm that trains a single supernet and efficiently produces abundant models/sub-architectures by weight sharing. To overcome the data multi-modality and architecture heterogeneity challenges in recommendation domain, NASRec establishes a large supernet (i.e., search space) to search the full architectures, with the supernet incorporating versatile operator choices and dense connectivity minimizing human prior for flexibility. The scale and heterogeneity in NASRec impose challenges in search, such as training inefficiency, operator-imbalance, and degraded rank correlation. We tackle these challenges by proposing single-operator any-connection sampling, operator-balancing interaction modules, and post-training fine-tuning. Our results on three Click-Through Rates (CTR) prediction benchmarks show that NASRec can outperform both manually designed models and existing NAS methods, achieving state-of-the-art performance.
Efficient Dynamic Graph Representation Learning at Scale
Dec 14, 2021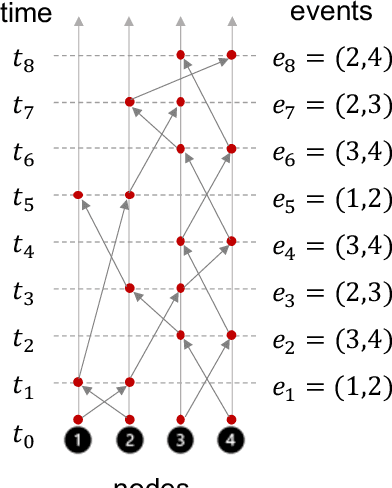
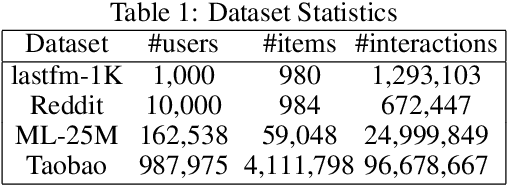
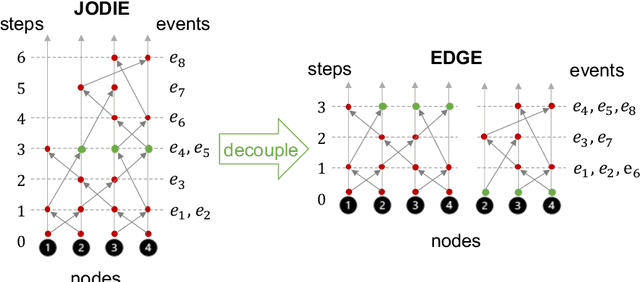
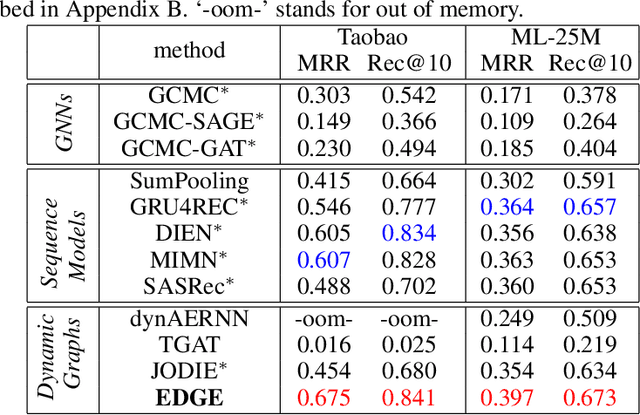
Dynamic graphs with ordered sequences of events between nodes are prevalent in real-world industrial applications such as e-commerce and social platforms. However, representation learning for dynamic graphs has posed great computational challenges due to the time and structure dependency and irregular nature of the data, preventing such models from being deployed to real-world applications. To tackle this challenge, we propose an efficient algorithm, Efficient Dynamic Graph lEarning (EDGE), which selectively expresses certain temporal dependency via training loss to improve the parallelism in computations. We show that EDGE can scale to dynamic graphs with millions of nodes and hundreds of millions of temporal events and achieve new state-of-the-art (SOTA) performance.
Time-based Sequence Model for Personalization and Recommendation Systems
Aug 27, 2020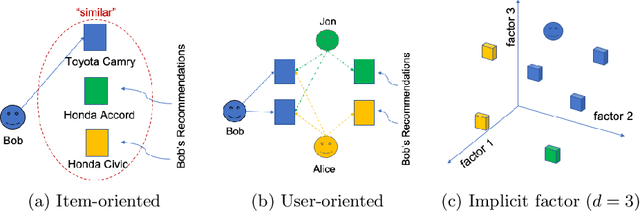

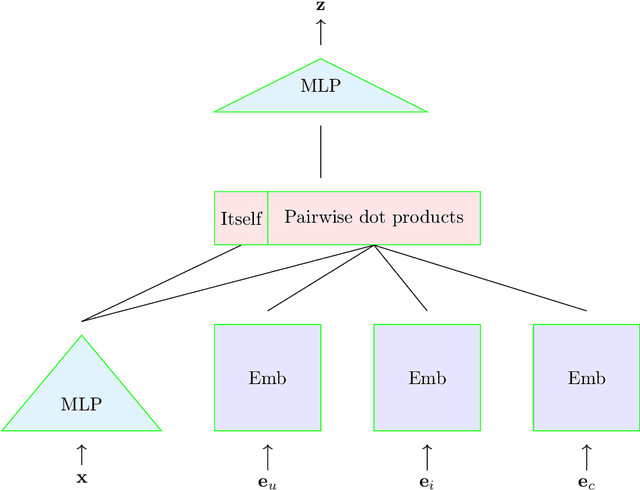
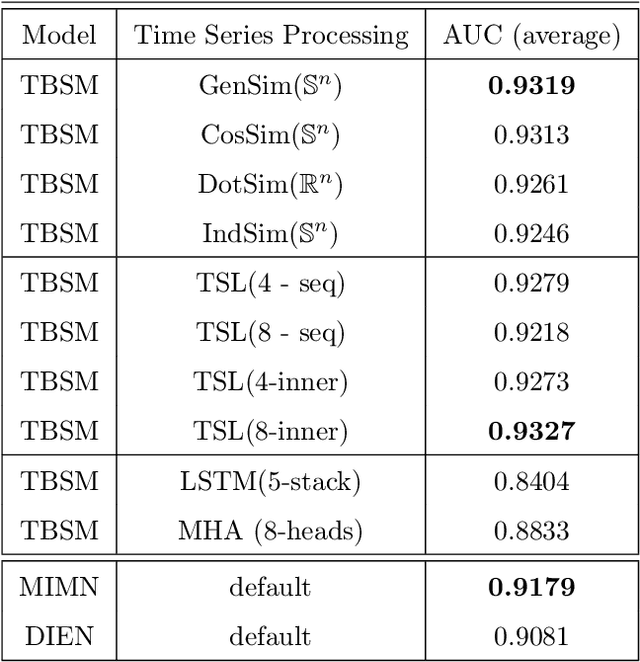
In this paper we develop a novel recommendation model that explicitly incorporates time information. The model relies on an embedding layer and TSL attention-like mechanism with inner products in different vector spaces, that can be thought of as a modification of multi-headed attention. This mechanism allows the model to efficiently treat sequences of user behavior of different length. We study the properties of our state-of-the-art model on statistically designed data set. Also, we show that it outperforms more complex models with longer sequence length on the Taobao User Behavior dataset.
ShadowSync: Performing Synchronization in the Background for Highly Scalable Distributed Training
Mar 07, 2020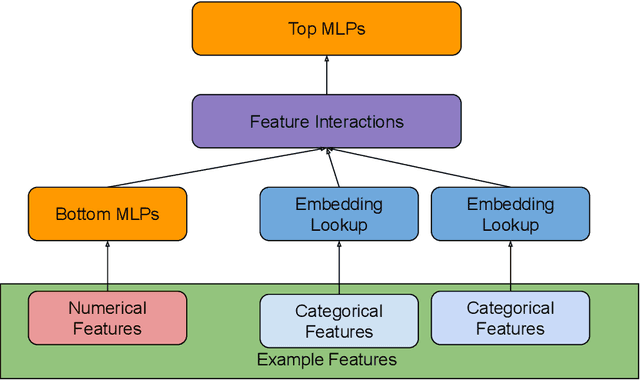
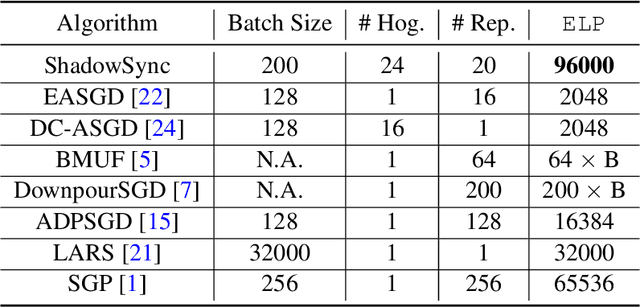
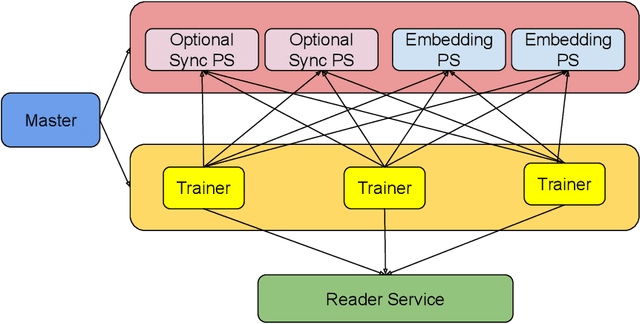
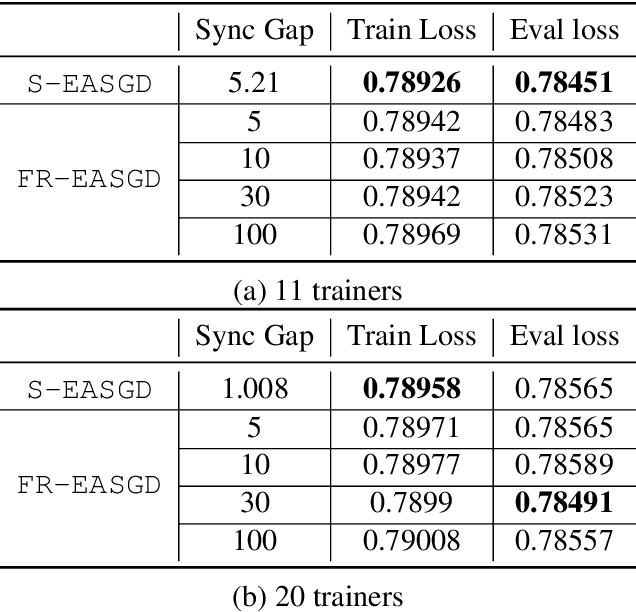
Distributed training is useful to train complicated models to shorten the training time. As each of the workers only sees a small fraction of data, workers need to synchronize on the parameter updates. One of the central questions in distributed training is how to parsimoniously synchronize parameters while preserving model quality. To address this problem, we propose the \textbf{ShadowSync} framework, in which we isolate synchronization from training and run it in the background. In contrast to common strategies including synchronous stochastic gradient descent (SGD), asynchronous SGD, and model averaging on independently trained sub-models, where synchronization happens in the foreground, ShadowSync synchronization is neither part of the backward pass, nor happens every $k$ iterations. Our framework is generic to host various types of synchronization algorithms, and we propose 3 approaches under this theme. The superiority of ShadowSync is confirmed by experiments on training deep neural networks for click-through-rate prediction. Our methods all succeed in making the training throughput linearly scale with the number of trainers. Comparing to their foreground counterparts, our methods exhibit neutral to better model quality and better scalability when we keep the number of parameter servers the same. In our training system which expresses both replication and Hogwild parallelism, ShadowSync also accomplishes the highest example level parallelism number comparing to the prior arts.
The Architectural Implications of Facebook's DNN-based Personalized Recommendation
Jun 18, 2019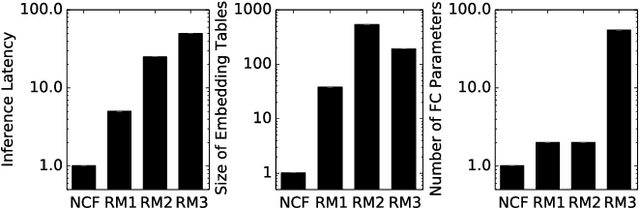
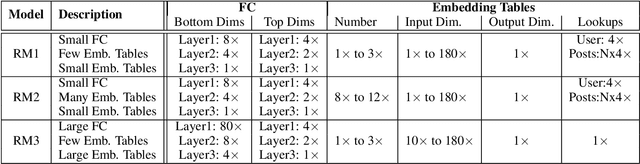
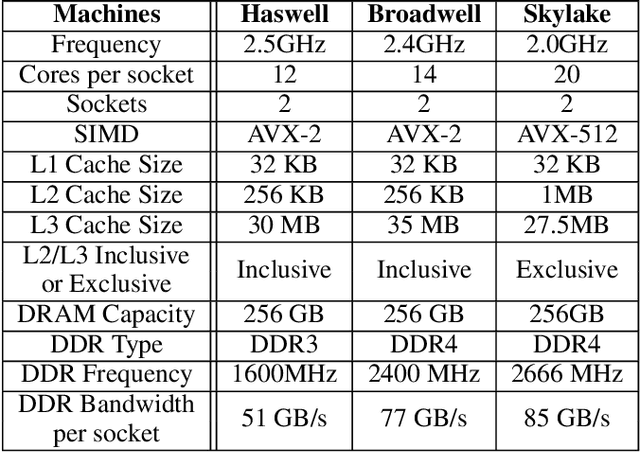
The widespread application of deep learning has changed the landscape of computation in the data center. In particular, personalized recommendation for content ranking is now largely accomplished leveraging deep neural networks. However, despite the importance of these models and the amount of compute cycles they consume, relatively little research attention has been devoted to systems for recommendation. To facilitate research and to advance the understanding of these workloads, this paper presents a set of real-world, production-scale DNNs for personalized recommendation coupled with relevant performance metrics for evaluation. In addition to releasing a set of open-source workloads, we conduct in-depth analysis that underpins future system design and optimization for at-scale recommendation: Inference latency varies by 60% across three Intel server generations, batching and co-location of inferences can drastically improve latency-bounded throughput, and the diverse composition of recommendation models leads to different optimization strategies.
Deep Learning Recommendation Model for Personalization and Recommendation Systems
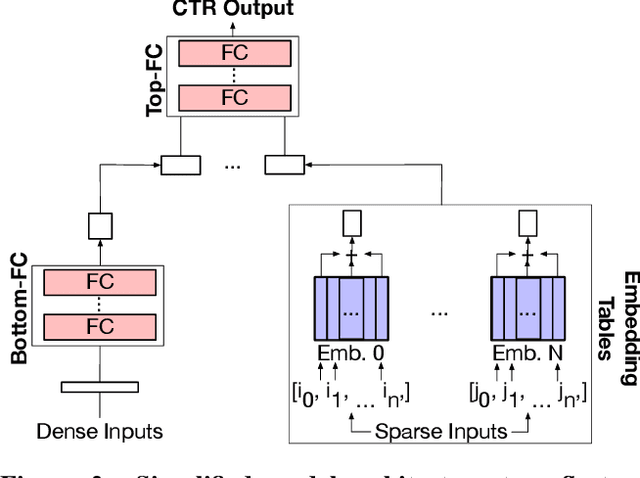
May 31, 2019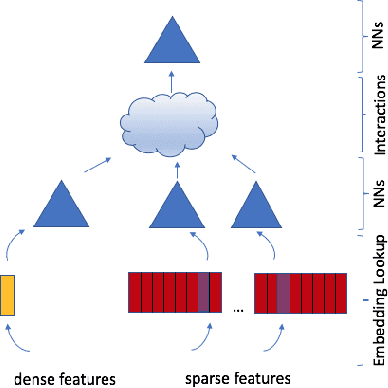

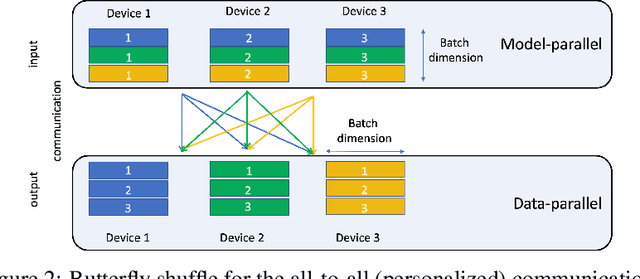
With the advent of deep learning, neural network-based recommendation models have emerged as an important tool for tackling personalization and recommendation tasks. These networks differ significantly from other deep learning networks due to their need to handle categorical features and are not well studied or understood. In this paper, we develop a state-of-the-art deep learning recommendation model (DLRM) and provide its implementation in both PyTorch and Caffe2 frameworks. In addition, we design a specialized parallelization scheme utilizing model parallelism on the embedding tables to mitigate memory constraints while exploiting data parallelism to scale-out compute from the fully-connected layers. We compare DLRM against existing recommendation models and characterize its performance on the Big Basin AI platform, demonstrating its usefulness as a benchmark for future algorithmic experimentation and system co-design.